GCN 实现3 :代码解析
1.代码结构
├── data // 图数据
├── inits // 初始化的一些公用函数
├── layers // GCN层的定义
├── metrics // 评测指标的计算
├── models // 模型结构定义
├── train // 训练
└── utils // 工具函数的定义
2.数据
Data: cora,Citeseer, or Pubmed,在data文件夹下:
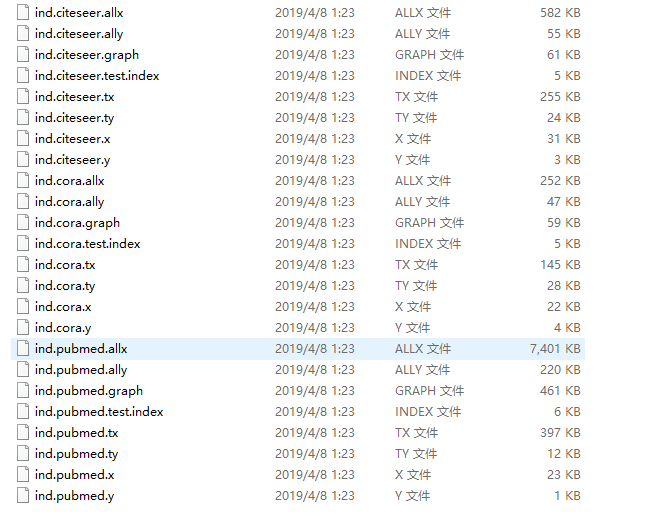
Original data:
Cora的数据集
包括2708份科学出版物,分为7类。引文网络由5429个链接组成。数据集中的每个发布都由一个0/1值的单词向量来描述,该向量表示字典中相应单词的存在或不存在。这部词典由1433个独特的单词组成。数据集中的自述文件提供了更多的细节。

CiteSeer文献分类
CiteSeer数据集包括3312种科学出版物,分为6类。引文网络由4732条链接组成。数据集中的每个发布都由一个0/1值的单词向量来描述,该向量表示字典中相应单词的存在或不存在。该词典由3703个独特的单词组成。
数据集中的自述文件提供了更多的细节。

CiteSeer for Entity Resolution
为了实体解析,CiteSeer数据集包含1504个机器学习文档,其中2892个作者引用了165个作者实体。对于这个数据集,惟一可用的属性信息是作者名。完整的姓总是给出的,在某些情况下,作者的全名和中间名是给出的,其他时候只给出首字母。
PubMed糖尿病数据库
由来自PubMed数据库的19717篇与糖尿病相关的科学出版物组成,分为三类。引文网络由44338个链接组成。数据集中的每个出版物都由一个TF/IDF加权词向量来描述,这个词向量来自一个包含500个唯一单词的字典。数据集中的自述文件提供了更多的细节。

以下以cora数据集为例:



数据集预处理:
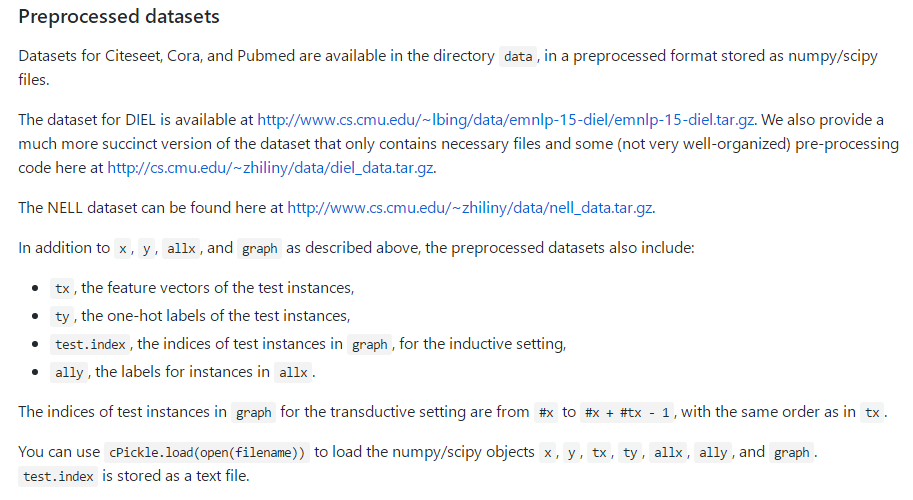
读取数据:

"""
def load_data(dataset_str):
------
Loads input data from gcn/data directory
ind.dataset_str.x => the feature vectors of the training instances as scipy.sparse.csr.csr_matrix object;
ind.dataset_str.tx => the feature vectors of the test instances as scipy.sparse.csr.csr_matrix object;
ind.dataset_str.allx => the feature vectors of both labeled and unlabeled training instances
(a superset of ind.dataset_str.x) as scipy.sparse.csr.csr_matrix object;
ind.dataset_str.y => the one-hot labels of the labeled training instances as numpy.ndarray object;
ind.dataset_str.ty => the one-hot labels of the test instances as numpy.ndarray object;
ind.dataset_str.ally => the labels for instances in ind.dataset_str.allx as numpy.ndarray object;
ind.dataset_str.graph => a dict in the format {index: [index_of_neighbor_nodes]} as collections.defaultdict
object;
ind.dataset_str.test.index => the indices of test instances in graph, for the inductive setting as list object.
All objects above must be saved using python pickle module.
:param dataset_str: Dataset name
:return: All data input files loaded (as well the training/test data).
------
names = ['x', 'y', 'tx', 'ty', 'allx', 'ally', 'graph']
objects = []
for i in range(len(names)):
with open("data/ind.{}.{}".format(dataset_str, names[i]), 'rb') as f:
if sys.version_info > (3, 0):
objects.append(pkl.load(f, encoding='latin1'))
else:
objects.append(pkl.load(f))
x, y, tx, ty, allx, ally, graph = tuple(objects)
test_idx_reorder = parse_index_file("data/ind.{}.test.index".format(dataset_str))
test_idx_range = np.sort(test_idx_reorder)
if dataset_str == 'citeseer':
# Fix citeseer dataset (there are some isolated nodes in the graph)
# Find isolated nodes, add them as zero-vecs into the right position
test_idx_range_full = range(min(test_idx_reorder), max(test_idx_reorder)+1)
tx_extended = sp.lil_matrix((len(test_idx_range_full), x.shape[1]))
tx_extended[test_idx_range-min(test_idx_range), :] = tx
tx = tx_extended
ty_extended = np.zeros((len(test_idx_range_full), y.shape[1]))
ty_extended[test_idx_range-min(test_idx_range), :] = ty
ty = ty_extended
features = sp.vstack((allx, tx)).tolil()
features[test_idx_reorder, :] = features[test_idx_range, :]
adj = nx.adjacency_matrix(nx.from_dict_of_lists(graph))
labels = np.vstack((ally, ty))
labels[test_idx_reorder, :] = labels[test_idx_range, :]
idx_test = test_idx_range.tolist()
idx_train = range(len(y))
idx_val = range(len(y), len(y)+500)
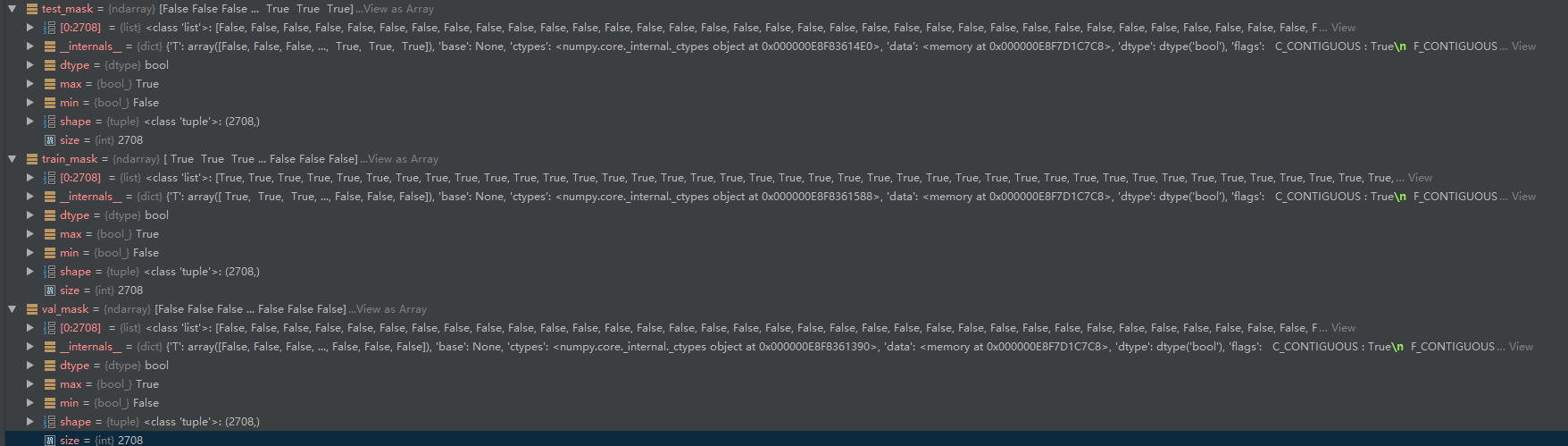
train_mask = sample_mask(idx_train, labels.shape[0])
val_mask = sample_mask(idx_val, labels.shape[0])
test_mask = sample_mask(idx_test, labels.shape[0])
y_train = np.zeros(labels.shape)
y_val = np.zeros(labels.shape)
y_test = np.zeros(labels.shape)
y_train[train_mask, :] = labels[train_mask, :]
y_val[val_mask, :] = labels[val_mask, :]
y_test[test_mask, :] = labels[test_mask, :]
return adj, features, y_train, y_val, y_test, train_mask, val_mask, test_mask
"""
知识点1:
那么为什么需要序列化和反序列化这一操作呢? 便于存储。序列化过程将文本信息转变为二进制数据流。这样就信息就容易存储在硬盘之中,当需要读取文件的时候,从硬盘中读取数据,然后再将其反序列化便可以得到原始的数据。在Python程序运行中得到了一些字符串、列表、字典等数据,想要长久的保存下来,方便以后使用,而不是简单的放入内存中关机断电就丢失数据。python模块大全中的Pickle模块就派上用场了,它可以将对象转换为一种可以传输或存储的格式。 loads()函数执行和load() 函数一样的反序列化。取代接受一个流对象并去文件读取序列化后的数据,它接受包含序列化后的数据的str对象, 直接返回的对象。
import cPickle as pickle
pickle.dump(obj,f) # 序列化方法pickle.dump()
pickle.dumps(obj,f) #pickle.dump(obj, file, protocol=None,*,fix_imports=True) 该方法实现的是将序列化后的对象obj以二进制形式写入文件file中,进行保存。它的功能等同于 Pickler(file, protocol).dump(obj)。
pickle.load(f) #反序列化操作: pickle.load(file, *,fix_imports=True, encoding=”ASCII”. errors=”strict”)
pickle.loads(f)
回顾以下:
cora数据集:包括2708份科学出版物,分为7类。引文网络由5429个链接组成。数据集中的每个发布都由一个0/1值的单词向量来描述,该向量表示字典中相应单词的存在或不存在。这部词典由1433个独特的单词组成。
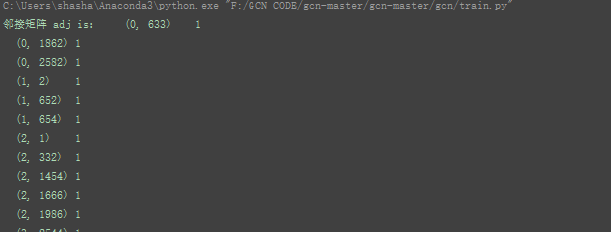
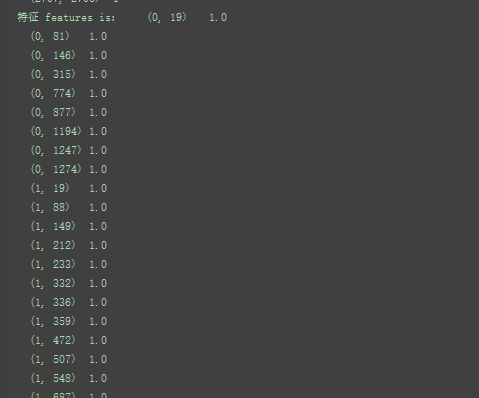

邻接矩阵adj:27082708 对应2708份科学出版物,以及对应的连接

特征feature :27081433 ,这部词典由1433个独特的单词组成。
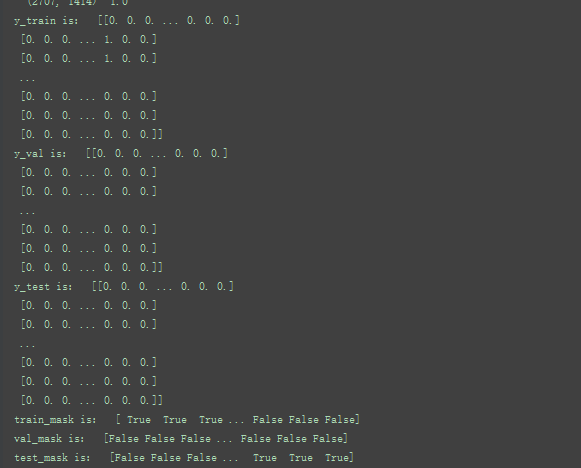
7对应7类
接下来做一些处理:

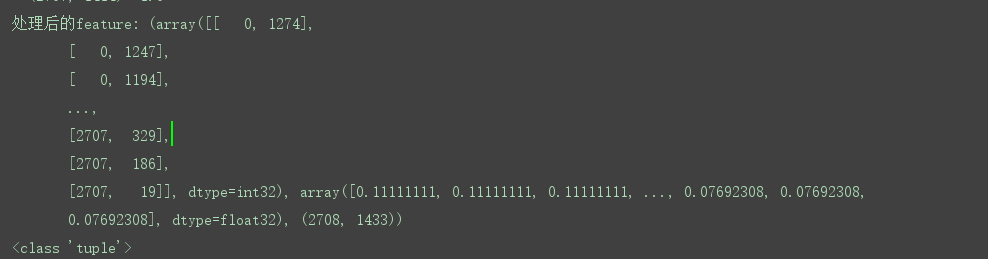
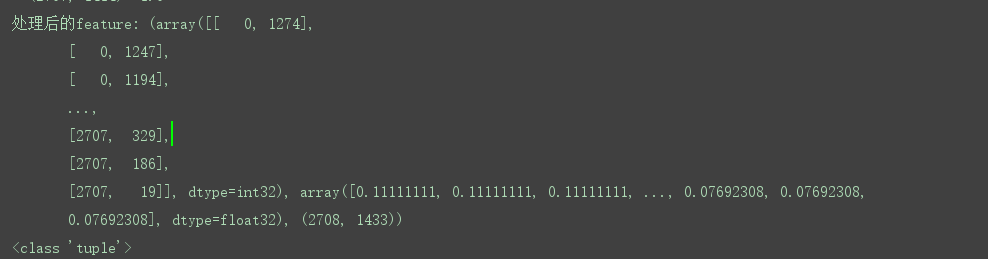
行规格化特征矩阵并转换为元组表示:

处理特征:将特征进行归一化并返回tuple (coords, values, shape)
模型的选择
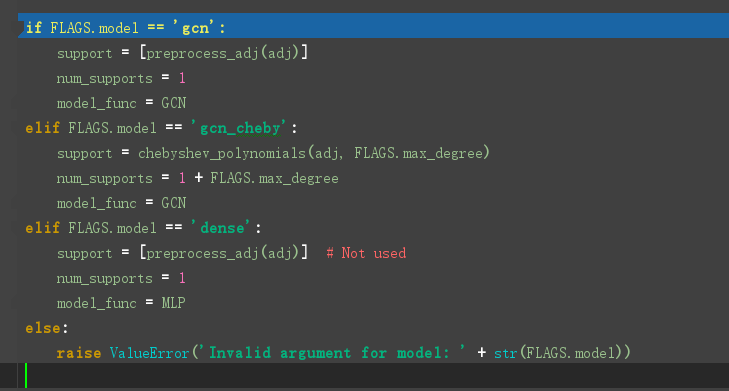

GCN定义在model.py文件中,model.py 定义了一个model基类,以及两个继承自model类的MLP、GCN类。
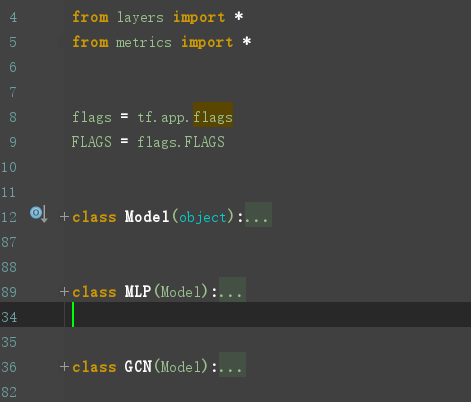
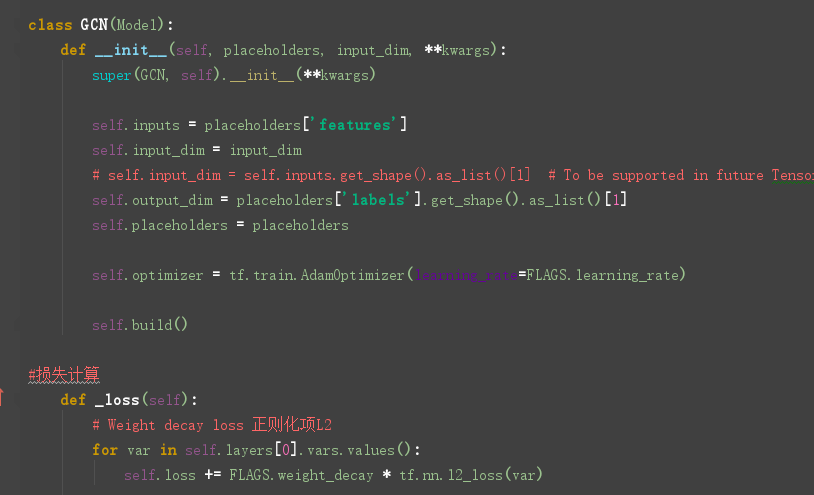
重点来看看GCN类的定义:

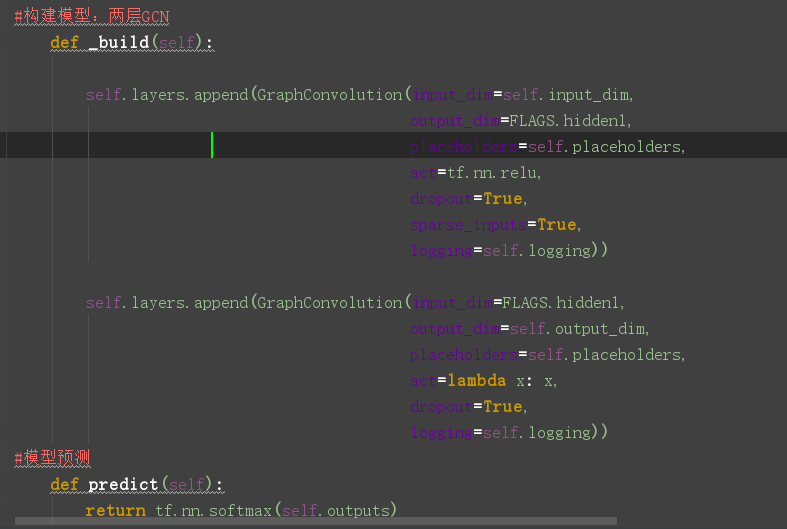
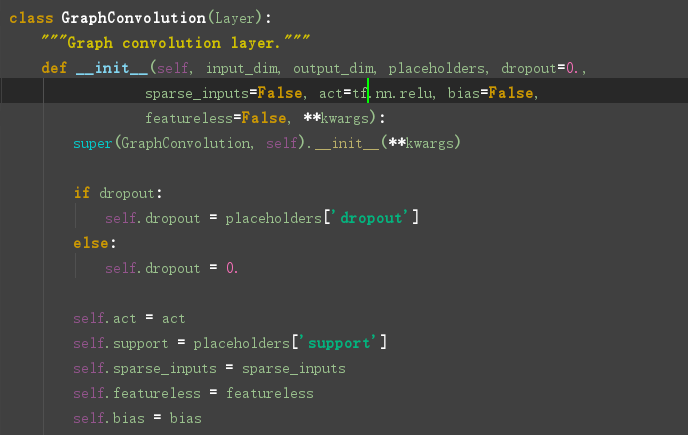
看一下图卷积层的定义:在layer.py文件中,

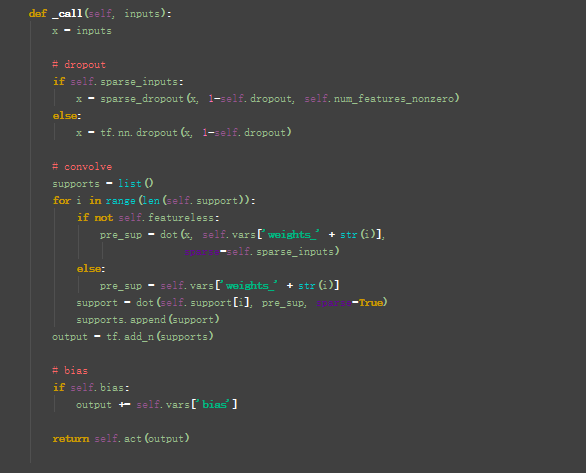
接下来:
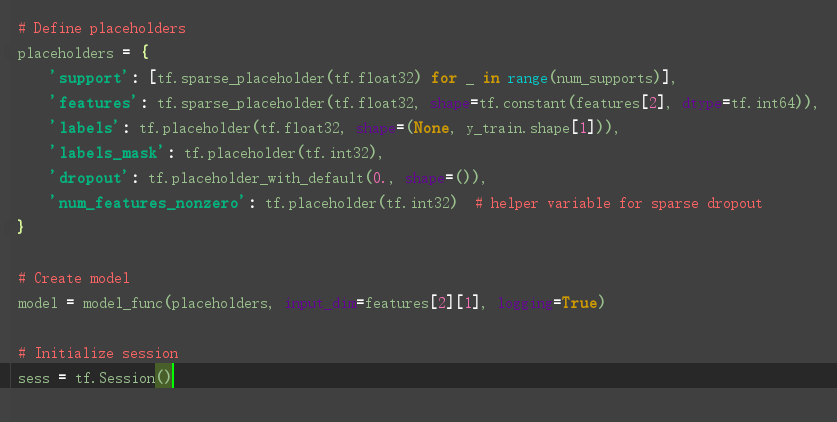

然后训练模型:
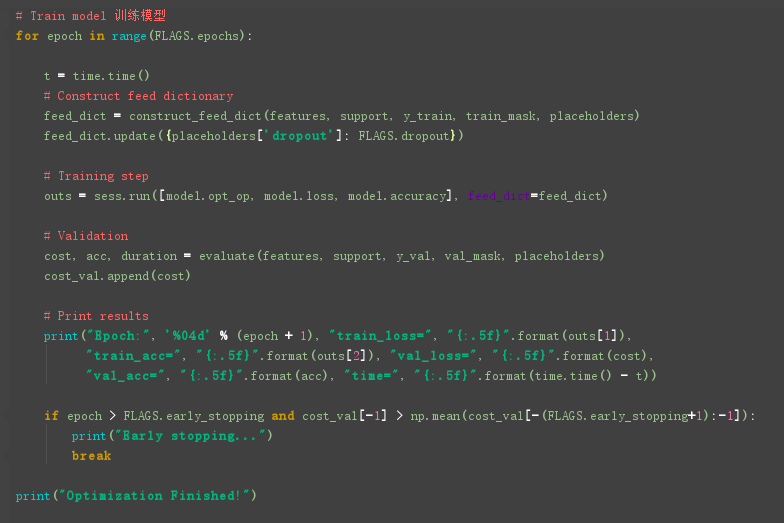

细节补充1:
参考:https://blog.csdn.net/weixin_36474809/article/details/89379727
GCN 实现3 :代码解析的更多相关文章
- GraphSAGE 代码解析(四) - models.py
原创文章-转载请注明出处哦.其他部分内容参见以下链接- GraphSAGE 代码解析(一) - unsupervised_train.py GraphSAGE 代码解析(二) - layers.py ...
- GraphSAGE 代码解析(一) - unsupervised_train.py
原创文章-转载请注明出处哦.其他部分内容参见以下链接- GraphSAGE 代码解析(二) - layers.py GraphSAGE 代码解析(三) - aggregators.py GraphSA ...
- VBA常用代码解析
031 删除工作表中的空行 如果需要删除工作表中所有的空行,可以使用下面的代码. Sub DelBlankRow() DimrRow As Long DimLRow As Long Dimi As L ...
- [nRF51822] 12、基础实验代码解析大全 · 实验19 - PWM
一.PWM概述: PWM(Pulse Width Modulation):脉冲宽度调制技术,通过对一系列脉冲的宽度进行调制,来等效地获得所需要波形. PWM 的几个基本概念: 1) 占空比:占空比是指 ...
- [nRF51822] 11、基础实验代码解析大全 · 实验16 - 内部FLASH读写
一.实验内容: 通过串口发送单个字符到NRF51822,NRF51822 接收到字符后将其写入到FLASH 的最后一页,之后将其读出并通过串口打印出数据. 二.nRF51822芯片内部flash知识 ...
- [nRF51822] 10、基础实验代码解析大全 · 实验15 - RTC
一.实验内容: 配置NRF51822 的RTC0 的TICK 频率为8Hz,COMPARE0 匹配事件触发周期为3 秒,并使能了TICK 和COMPARE0 中断. TICK 中断中驱动指示灯D1 翻 ...
- [nRF51822] 9、基础实验代码解析大全 · 实验12 - ADC
一.本实验ADC 配置 分辨率:10 位. 输入通道:5,即使用输入通道AIN5 检测电位器的电压. ADC 基准电压:1.2V. 二.NRF51822 ADC 管脚分布 NRF51822 的ADC ...
- java集合框架之java HashMap代码解析
java集合框架之java HashMap代码解析 文章Java集合框架综述后,具体集合类的代码,首先以既熟悉又陌生的HashMap开始. 源自http://www.codeceo.com/arti ...
- Kakfa揭秘 Day8 DirectKafkaStream代码解析
Kakfa揭秘 Day8 DirectKafkaStream代码解析 今天让我们进入SparkStreaming,看一下其中重要的Kafka模块DirectStream的具体实现. 构造Stream ...
- linux内存管理--slab及其代码解析
Linux内核使用了源自于 Solaris 的一种方法,但是这种方法在嵌入式系统中已经使用了很长时间了,它是将内存作为对象按照大小进行分配,被称为slab高速缓存. 内存管理的目标是提供一种方法,为实 ...
随机推荐
- 软帝学院:一万字的Java基础知识总结大全(实用)
Java基础总结大全(实用) 一.基础知识: 1.JVM.JRE和JDK的区别: JVM(Java Virtual Machine):java虚拟机,用于保证java的跨平台的特性. java语言是跨 ...
- gradle下mybatis自动生成框架的使用
自动生成框架的意义 主要为了解决人为添加mapper,模型等工作,减少错误,提交效率! 添加引用build.gradle configurations { mybatisGenerator } myb ...
- Git 在同一台机器上配置多个Git帐号
在同一台机器上配置多个Git帐号 By:授客 QQ:1033553122 实践环境 win10 Git-2.21.0-64-bit.exe TortoiseGit-2.8.0.0-64bit.msi ...
- Cesium专栏-淹没分析(附源码下载)
Cesium 是一款面向三维地球和地图的,世界级的JavaScript开源产品.它提供了基于JavaScript语言的开发包,方便用户快速搭建一款零插件的虚拟地球Web应用,并在性能,精度,渲染质量以 ...
- SAP FI 问题汇总
记录工作中遇到的问题汇总 1.固定资产折旧码的设置 2.与资产有关的日期 3.如何添加固定资产分类
- 苹果_公司开发者账号_注册Apple ID
本文所有网站入口为developer.apple.com 注册Apple ID 注意事项:目前注册信息尽量用拼音或英文,姓名格式正确,记住安全问题,出生日期在18岁以上(小于18岁会出现Sorry,y ...
- DialogHost 关闭对话框
<Window x:Class="DialogHost.ClosingConfirmation.CodeBehind.MainWindow" xmlns="http ...
- PWA 学习笔记(四)
Service Worker 简介: 1.Service Worker 是 PWA 技术基础之一,脱离浏览器主线程的特性,使得 Web App 离线缓存成为可能, 更为后台同步.通知推送等功能提供了思 ...
- C编程小结1
1. ‘\0’表示字符串结束符 2. 变量之间互相赋值一定要考虑他们的数据类型,要强制转换匹配上了或者进行一些处理才能赋值,同时读程序的时候也要注意这一点,否则可能看不懂.如: sData[0]=wD ...
- python 基础学习笔记(7)--迭送器
**函数名的运用** - [ ] 函数名是一个变量, 但它是一个特殊的变量, 与括号配合可以执行函数的变量 **函数名的内存地址** ``` def func(): print('666') p ...