pandas.DataFrame的groupby()方法的基本使用
pandas.DataFrame的groupby()方法是一个特别常用和有用的方法。让我们快速掌握groupby()方法的基础使用,从此数据分析又多一法宝。
首先导入package:
import pandas as pd
import numpy as np
groupby的最基本操作
df = pd.DataFrame({'A':[1,2,3,1],'B':[2,3,3,6],'C':[3,1,5,7]})
df

按照A列来进行分组(其实说白了就是将A列中重复的值和成同一个值,然后把A当成索引来进行重新的数据分组)
df.groupby('A').mean() #mean是取平均值
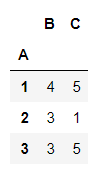
df.groupby('A').sum() #sum是求和

df.groupby(['A']).first() #取第一个出现的数据

df.groupby(['A']).last() #取最后一个出现的数据
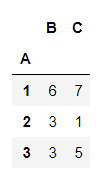
也可以按照多组进行分组
df.groupby(['A','B']).sum()
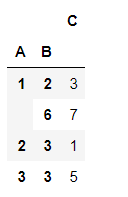
统计数据的数量
size跟count的区别: size计数时包含NaN值,而count不包含NaN值
df = pd.DataFrame({'A':[1,2,3,1],'B':[2,3,3,6],'C':[3,np.nan,5,7]})
df
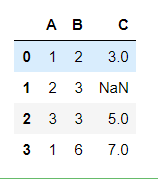
df.groupby(['A']).count()
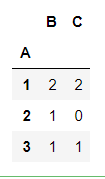
df.groupby(['A']).size()

pandas.DataFrame的groupby()方法的基本使用的更多相关文章
- 把pandas dataframe转为list方法
把pandas dataframe转为list方法 先用numpy的 array() 转为ndarray类型,再用tolist()函数转为list
- pandas DataFrame的修改方法
pandas DataFrame的增删查改总结系列文章: pandas DaFrame的创建方法 pandas DataFrame的查询方法 pandas DataFrame行或列的删除方法 pand ...
- pandas DataFrame的查询方法(loc,iloc,at,iat,ix的用法和区别)
pandas DataFrame的增删查改总结系列文章: pandas DaFrame的创建方法 pandas DataFrame的查询方法 pandas DataFrame行或列的删除方法 pand ...
- pandas DataFrame的创建方法
pandas DataFrame的增删查改总结系列文章: pandas DaFrame的创建方法 pandas DataFrame的查询方法 pandas DataFrame行或列的删除方法 pand ...
- pandas.DataFrame 中save方法
In [5]: frame.save('frame_pickle') ----------------------------------------------------------------- ...
- Pandas:DataFrame数据选择方法(索引)
#首先创建我们的Series对象,然后合并到dataframe对象里面去 import pandas as pd import numpy as np area=pd.Series({,,,}) po ...
- pandas DataFrame行或列的删除方法
pandas DataFrame的增删查改总结系列文章: pandas DaFrame的创建方法 pandas DataFrame的查询方法 pandas DataFrame行或列的删除方法 pand ...
- Pandas的排序和排名(Series, DataFrame) + groupby
根据条件对数据集排序(sorting)也是一种重要的内置运算.要对行或列索引进行排序(按字典顺序), 可使用sort_index 方法, 它将返回一个已排序的新对象: 而DataFrame, 则可以根 ...
- Python时间处理,datetime中的strftime/strptime+pandas.DataFrame.pivot_table(像groupby之类 的操作)
python中datetime模块非常好用,提供了日期格式和字符串格式相互转化的函数strftime/strptime 1.由日期格式转化为字符串格式的函数为: datetime.datetime.s ...
随机推荐
- 快速了解会话管理三剑客cookie、session和JWT
更多内容,欢迎关注微信公众号:全菜工程师小辉.公众号回复关键词,领取免费学习资料. 存储位置 三者都是应用在web中对http无状态协议的补充,达到状态保持的目的 cookie:cookie中的信息是 ...
- Github资源下载
自己收集的一些日常使用软件.编程书籍以及自己动手实践的程序,欢迎下载. 收集维护不易,喜欢请Star或Fork支持呀,(^-^)V. 所有资源均自己制作或收集自网络,如有侵权请联系删除. 友情链接 G ...
- 极简Docker和Kubernetes发展史
2013年 Docker项目开源 2013年,以AWS及OpenStack,以Cloud Foundry为代表的开源Pass项目,成了云计算领域的一股清流,pass提供了一种"应用托管&qu ...
- JIra配置权限方案
目录: 添加用户 添加用户组 将用户分配到不同的组中 创建项目权限方案 配置项目采用的权限方案 1. 添加用户 1)使用admin权限的账户登录后,点击右上角的配置,选择system 2)在打开的页面 ...
- 2019DX#6
Solved Pro.ID Title Ratio(Accepted / Submitted) 1001 Salty Fish 16.28%(7/43) OK 1002 Nonsense Tim ...
- CodeForces 1082 F Speed Dial
题目传送门 题意:现在有n个电话号码,每个电话号码为si,拨打次数为pi. 现在有k 个快捷键,每次拨打号码之前可以先按一次快捷键,然后再输入数字,现在问输入数字次数是多少.快捷键的号码可以不在电话簿 ...
- CF - 652 E Pursuit For Artifacts 边双联通
题目传送门 题解总结起来其实很简单. 把所有的边双联通分量缩成一个点,然后建立好新边, 然后再从起点搜到终点就好了. 代码: /* code by: zstu wxk time: 2019/02/23 ...
- CF980B Marlin 构造 思维 二十四
Marlin time limit per test 1 second memory limit per test 256 megabytes input standard input output ...
- ~!#$%^&*这些符号怎么读? 当然是用英语(键盘特殊符号小结)
~!#$%^&*这些符号怎么读? 当然是用英语(键盘特殊符号小结) 感谢原文作者:http://www.360doc.com/content/14/0105/20/85007_342874 ...
- springboot2之结合mybatis增删改查解析
1. 场景描述 本节结合springboot2.springmvc.mybatis.swagger2等,搭建一个完整的增删改查项目,希望通过这个基础项目,能帮忙朋友快速上手springboot2项目. ...