Python爬虫实战:批量下载网站图片
前言
本文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理。
作者: GitPython
PS:如有需要Python学习资料的小伙伴可以加点击下方链接自行获取
http://note.youdao.com/noteshare?id=3054cce4add8a909e784ad934f956cef
1.获取图片的url链接
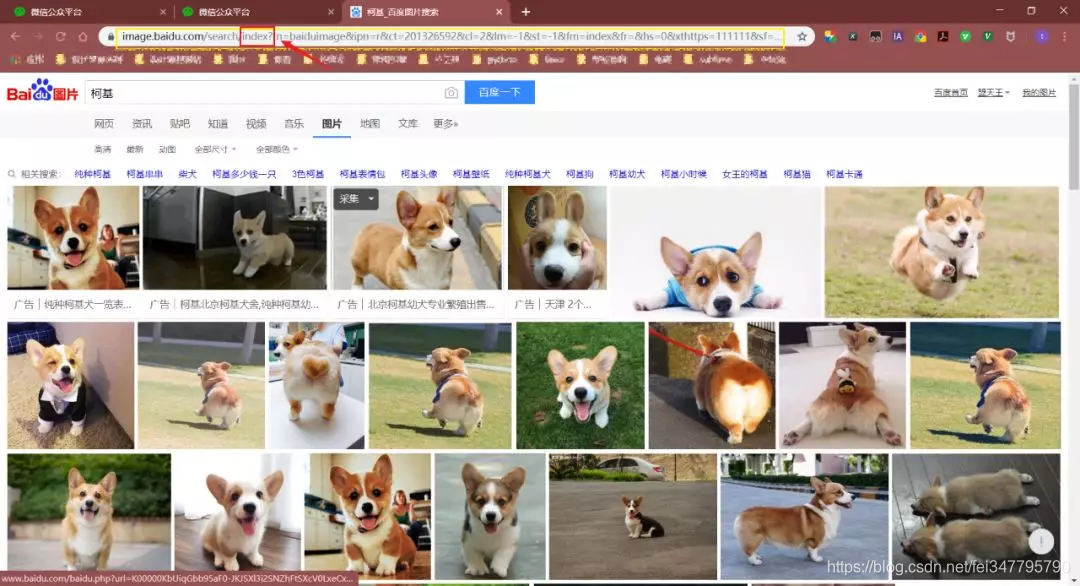
首先,打开百度图片首页,注意下图url中的index
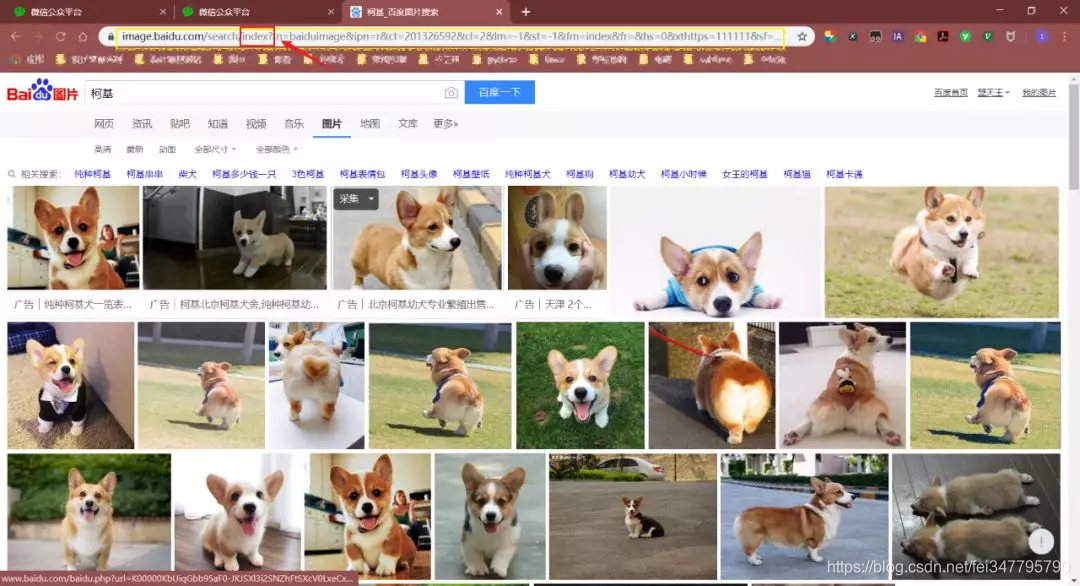
接着,把页面切换成传统翻页版(flip),因为这样有利于我们爬取图片!
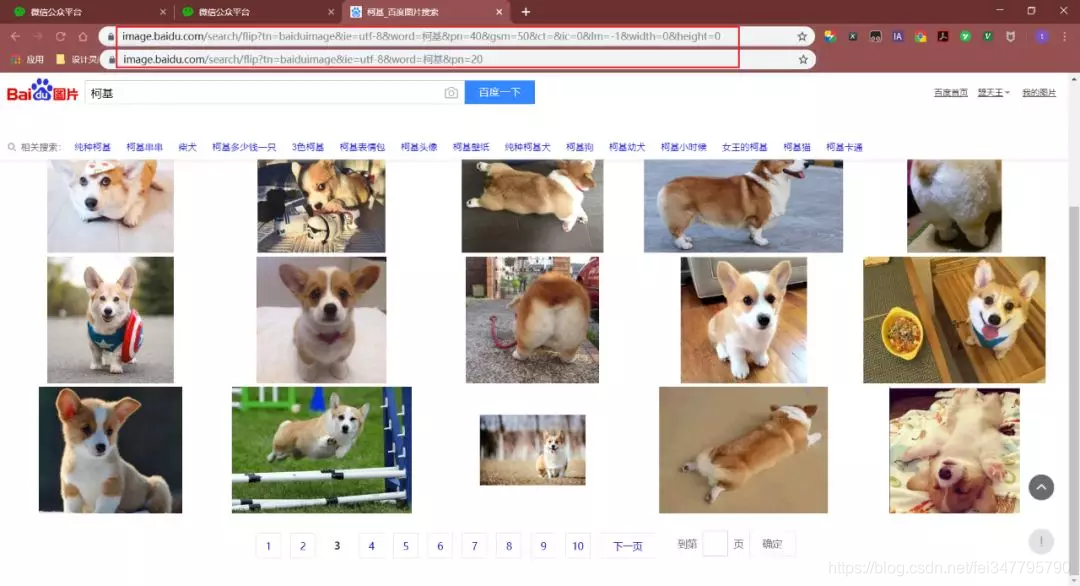
对比了几个url发现,pn参数是请求到的数量。通过修改pn参数,观察返回的数据,发现每页最多只能是60个图片。
注:gsm参数是pn参数的16进制表达,去掉无妨
然后,右键检查网页源代码,直接(ctrl+F)搜索 objURL
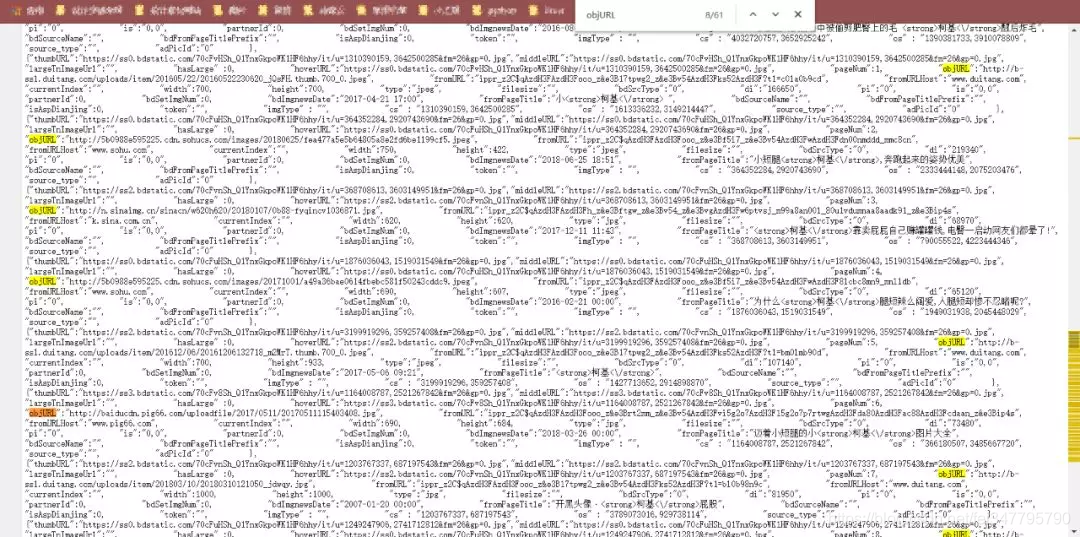
这样,我们发现了需要图片的url了。
2.把图片链接保存到本地
现在,我们要做的就是将这些信息爬取出来。
注:网页中有objURL,hoverURL…但是我们用的是objURL,因为这个是原图
那么,如何获取objURL?用正则表达式!
那我们该如何用正则表达式实现呢?其实只需要一行代码…
results = re.findall('"objURL":"(.*?)",', html)
核心代码:
1.获取图片url代码:
# 获取图片url连接
def get_parse_page(pn,name):
for i in range(int(pn)):
# 1.获取网页
print('正在获取第{}页'.format(i+1))
# 百度图片首页的url
# name是你要搜索的关键词
# pn是你想下载的页数
url = 'https://image.baidu.com/search/flip?tn=baiduimage&ie=utf-8&word=%s&pn=%d' %(name,i*20)
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.104 Safari/537.36 Core/1.53.4843.400 QQBrowser/9.7.13021.400'}
# 发送请求,获取相应
response = requests.get(url, headers=headers)
html = response.content.decode()
# print(html)
# 2.正则表达式解析网页
# "objURL":"http://n.sinaimg.cn/sports/transform/20170406/dHEk-fycxmks5842687.jpg"
results = re.findall('"objURL":"(.*?)",', html) # 返回一个列表
# 根据获取到的图片链接,把图片保存到本地
save_to_txt(results, name, i)
2.保存图片到本地代码:
# 保存图片到本地
def save_to_txt(results, name, i):
j = 0
# 在当目录下创建文件夹
if not os.path.exists('./' + name):
os.makedirs('./' + name)
# 下载图片
for result in results:
print('正在保存第{}个'.format(j))
try:
pic = requests.get(result, timeout=10)
time.sleep(1)
except:
print('当前图片无法下载')
j += 1
continue
# 可忽略,这段代码有bug
# file_name = result.split('/')
# file_name = file_name[len(file_name) - 1]
# print(file_name)
#
# end = re.search('(.png|.jpg|.jpeg|.gif)$', file_name)
# if end == None:
# file_name = file_name + '.jpg'
# 把图片保存到文件夹
file_full_name = './' + name + '/' + str(i) + '-' + str(j) + '.jpg'
with open(file_full_name, 'wb') as f:
f.write(pic.content)
j += 1
3.主函数代码:
# 主函数
if __name__ == '__main__':
name = input('请输入你要下载的关键词:')
pn = input('你想下载前几页(1页有60张):')
get_parse_page(pn,
使用说明:
# 配置以下模块
import requests
import re
import os
import time
# 1.运行 py源文件
# 2.输入你想搜索的关键词,比如“柯基”、“泰迪”等
# 3.输入你想下载的页数,比如5,那就是下载 5 x 60=300 张图片
Python爬虫实战:批量下载网站图片的更多相关文章
- Python爬虫实战 批量下载高清美女图片
彼岸图网站里有大量的高清图片素材和壁纸,并且可以免费下载,读者也可以根据自己需要爬取其他类型图片,方法是类似的,本文通过python爬虫批量下载网站里的高清美女图片,熟悉python写爬虫的基本方法: ...
- 批量下载网站图片的Python实用小工具(下)
引子 在 批量下载网站图片的Python实用小工具 一文中,讲解了开发一个Python小工具来实现网站图片的并发批量拉取.不过那个工具仅限于特定网站的特定规则,本文将基于其代码实现,开发一个更加通用的 ...
- 批量下载网站图片的Python实用小工具
定位 本文适合于熟悉Python编程且对互联网高清图片饶有兴趣的筒鞋.读完本文后,将学会如何使用Python库批量并发地抓取网页和下载图片资源.只要懂得如何安装Python库以及运行Python程序, ...
- 利用python爬虫关键词批量下载高清大图
前言 在上一篇写文章没高质量配图?python爬虫绕过限制一键搜索下载图虫创意图片!中,我们在未登录的情况下实现了图虫创意无水印高清小图的批量下载.虽然小图能够在一些移动端可能展示的还行,但是放到pc ...
- python爬虫实战(3)--图片下载器
本篇目标 1.输入关键字能够根据关键字爬取百度图片 2.能够将图片保存到本地文件夹 1.URL的格式 进入百度图片搜索apple,这时显示的是瀑布流版本,我们选择传统翻页版本进行爬取.可以看到网址为: ...
- 【图文详解】python爬虫实战——5分钟做个图片自动下载器
python爬虫实战——图片自动下载器 之前介绍了那么多基本知识[Python爬虫]入门知识,(没看的先去看!!)大家也估计手痒了.想要实际做个小东西来看看,毕竟: talk is cheap sho ...
- python爬虫实战——5分钟做个图片自动下载器
python爬虫实战——图片自动下载器 制作爬虫的基本步骤 顺便通过这个小例子,可以掌握一些有关制作爬虫的基本的步骤. 一般来说,制作一个爬虫需要分以下几个步骤: 分析需求(对,需求分析非常重要, ...
- 《精通Python网络爬虫》|百度网盘免费下载|Python爬虫实战
<精通Python网络爬虫>|百度网盘免费下载|Python爬虫实战 提取码:7wr5 内容简介 为什么写这本书 网络爬虫其实很早就出现了,最开始网络爬虫主要应用在各种搜索引擎中.在搜索引 ...
- python多线程批量下载远程图片
python多线程使用场景:多线程采集, 以及性能测试等 . 数据库驱动类-简单封装下 mysqlDriver.py #!/usr/bin/python3 #-*- coding: utf-8 -*- ...
随机推荐
- 为什么坚果云Markdown值得使用?
值得使用说明是被认为有价值的,值得有两种意思的解释:1.有价值,有意义:2.价钱合适,合算:那么坚果云Markdown是否是人们值得使用的呢?下面就来看看坚果云Markdown到底是什么?为什么值得使 ...
- 对 /langversion 无效;必须是 ISO-1、ISO-2、3、4、5 或 Default
反编译或者.net用更高版本打开时会出现这个问题,解决办法如下: 1.网页版程序,将解决方案中的Web.config中的 /langversion 的值改为指定的值,既可以解决,我这里采用的是默认值, ...
- .Net Core 3.0 使用 Serilog 把日志记录到 SqlServer
Serilog简介 Serilog是.net中的诊断日志库,可以在所有的.net平台上面运行.Serilog支持结构化日志记录,对复杂.分布式.异步应用程序的支持非常出色.Serilog可以通过插件的 ...
- 用Spring Security, JWT, Vue实现一个前后端分离无状态认证Demo
简介 完整代码 https://github.com/PuZhiweizuishuai/SpringSecurity-JWT-Vue-Deom 运行展示 后端 主要展示 Spring Security ...
- Alertmanager 部署配置
目录 前言 源码安装 配置 启动 配置prometheus监控Alertmanager 修改prometheus配置 重新加载配置文件 配置测试告警 修改prometheus配置 重新加载配置文件 测 ...
- HTML 5 中的textarea标签
HTML 5 中的textarea标签 定义和用法 定义一个文本区域 (text-area) (一个多行的文本输入区域).用户可在此文本区域中写文本.在一个文本区中,您可输入无限数量的文本.文本区中的 ...
- 计算机硬件-CPU
计算机硬件-CPU 冯.诺依曼计算机体系 1.计算机硬件设备由存储器.运算器.控制器.输入设备和输出设备五部分 2.采取二进制形式和指令 3.将程序(数据和指令序列)预先存放在主存储器中,使计算机在工 ...
- SpringBoot 使用IDEA 配置热部署
在开发中稍微更改一点内容就要重启,很麻烦.这个时候使用Spring Boot的热部署就能解决你的问题. 上图: 1,在pom.xml文件中添加依赖: <dependency> <gr ...
- map.entrySet().iterator()
1.首先创建一个HashMap, Map map= new HashMap(); 2.Iterator iter= map.entrySet().iterator(); 首先是map.entrySet ...
- MySQL必知必会(Select, Where子句)
SELECT prod_name, prod_price FROM products WHERE prod_price = 2.5; SELECT prod_name, prod_price FROM ...