通过手动创建统计信息优化sql查询性能案例
本质原因在于:SQL Server 统计信息只包含复合索引的第一个列的信息,而不包含复合索引数据组合的信息
来源于工作中的一个实际问题,
这里是组合列数据不均匀导致查询无法预估数据行数,从而导致无法选择合理的执行计划导致性能低下的情况
我这里把问题简单化,主要是为了说明问题
如下一张业务表,主要看两个“状态”字段,BusinessStatus1 和 BusinessStatus2 create table BusinessTable
(
Id int identity(1,1),
Col2 varchar(50),
Col3 varchar(50),
Col4 varchar(50),
BusinessStatus1 tinyint,
BusinessStatus2 tinyint,
CreateDate Datetime
)
GO --向测试表中写入数据: begin tran
declare @i int
set @i=0
while @i<500000
begin
insert into BusinessTable values (NEWID(),NEWID(),NEWID(),1,10,GETDATE()-RAND()*1000)
insert into BusinessTable values (NEWID(),NEWID(),NEWID(),1,20,GETDATE()-RAND()*1000)
insert into BusinessTable values (NEWID(),NEWID(),NEWID(),1,30,GETDATE()-RAND()*1000) insert into BusinessTable values (NEWID(),NEWID(),NEWID(),2,20,GETDATE()-RAND()*1000)
insert into BusinessTable values (NEWID(),NEWID(),NEWID(),2,30,GETDATE()-RAND()*1000)
insert into BusinessTable values (NEWID(),NEWID(),NEWID(),2,40,GETDATE()-RAND()*1000) insert into BusinessTable values (NEWID(),NEWID(),NEWID(),3,30,GETDATE()-RAND()*1000)
insert into BusinessTable values (NEWID(),NEWID(),NEWID(),3,40,GETDATE()-RAND()*1000)
insert into BusinessTable values (NEWID(),NEWID(),NEWID(),3,50,GETDATE()-RAND()*1000) set @i=@i+1
end
commit --插入一条特殊数据,也就是实际业务场景中:
insert into BusinessTable values (NEWID(),NEWID(),NEWID(),3,10,GETDATE()-RAND()*1000)
--测试数据的特点是: --BusinessStatus1 的分布位:1,2,3,
--BusinessStatus2 的分布位:10,20,30,40,50 --目前数据的对应关系, --但是注意插入的一条特殊数据:
--BusinessStatus1 和 BusinessStatus2 的组合为:BusinessStatus1=3 and BusinessStatus2=10,在451W条数据中是唯一的一个组合 --创建如下索引:
Create Clustered index idx_createDate on BusinessTable(CreateDate) Create Index idx_status on BusinessTable(BusinessStatus1,BusinessStatus2)
进行如下查询,就是查询那条所谓的特殊数据
select *
from BusinessTable
where BusinessStatus1=3 and BusinessStatus2=10
发现执行计划如下:走的是全表扫描,IO代价也不小,
这种情况下,明明只有一条数据,却要走全表扫描
(实际业务中类似数据也不仅只有一条这么巧,但是在千万级的表中,符合类似条件的数据很少,
打个比方好理解一点,就像订单表一样,订单是退订状态,且尚未退款,这种数据的分布是少之又少吧
只是举例,不要较真)
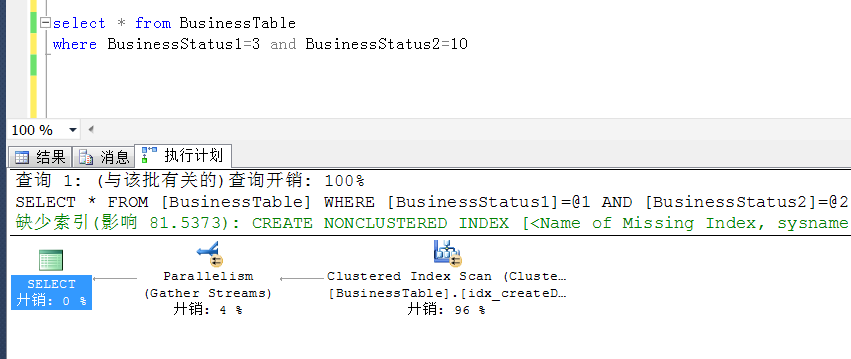
上面查询的IO信息

再通过强制索引提示的情况下,发现同样的查询,IO有一个非常大的下降
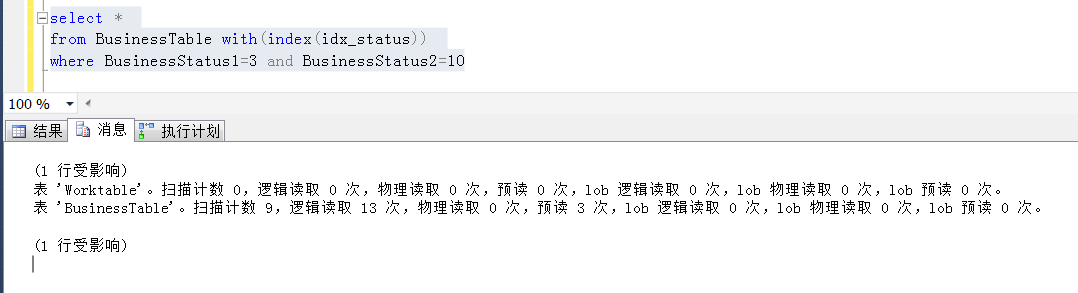
分析上述sql为什么不走索引?因为毕竟符合条件的数据只有一条,走全表扫描代价也过于大了,尤其是实际情况中,业务表更大,逻辑也没有这么直白
这个还要从索引统计信息说起,在符合索引中,索引统计信息只是统计前导列的,对于组合列的分布,sqlserver是无法预估到的,这一点可以通过第一个查询的执行计划发现
sqlserver只是能够预估到 BusinessStatus1 =3 的情况下的数据分布,但是无法预估到 BusinessStatus1=3 and BusinessStatus2=10这个组合情况下的数据分布情况
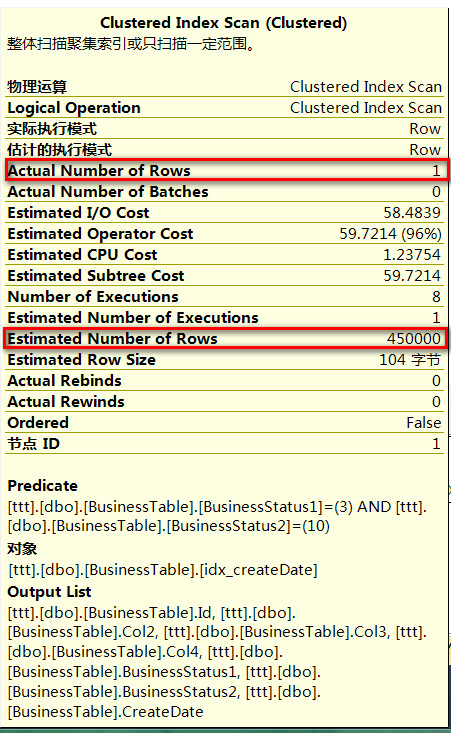
当然通过统计信息也可以看到,统计信息只记录了BusinessStatus1的列的数据分布情况,但是实际执行的过程中,无法预估BusinessStatus1=3 and BusinessStatus2=10的准确分布
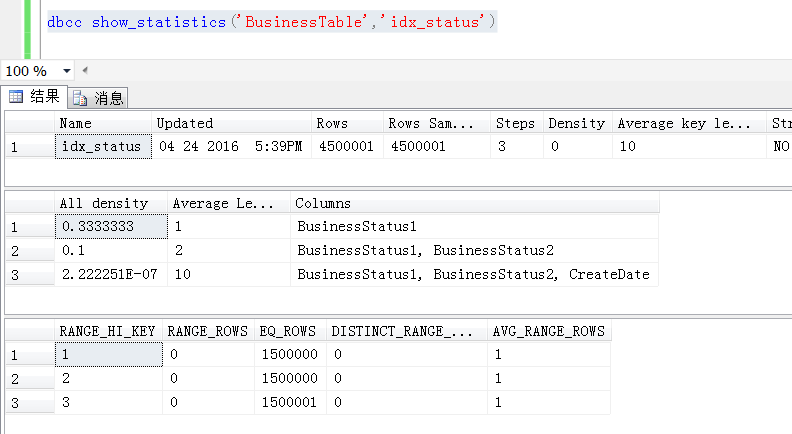
找到了问题的原因,就容易解决了,既然sqlserver无法预估到BusinessStatus1=3 and BusinessStatus2=10这个组合条件的数据分布请,
那么就创建一个过滤统计信息,让sqlserver准确地知道这个条件下数据的分布请,就容易做出相对准确的执行计划了
通过如下语句,创建一个该条件的统计信息
create statistics BusinessTableFilterStatistics
on BusinessTable(BusinessStatus1,BusinessStatus2)
where BusinessStatus1=3 and BusinessStatus2=10 --创建完统计信息之后注意要做个更新
UPDATE STATISTICS BusinessTable BusinessTableFilterStatistics with fullscan
创建完统计信息之后,发现表上会增加一个刚刚创建的统计信息
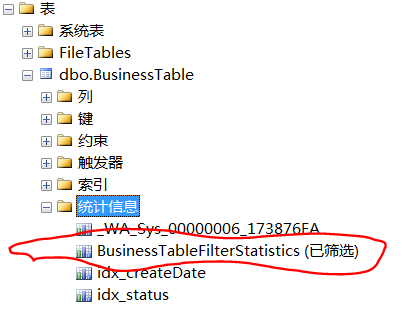
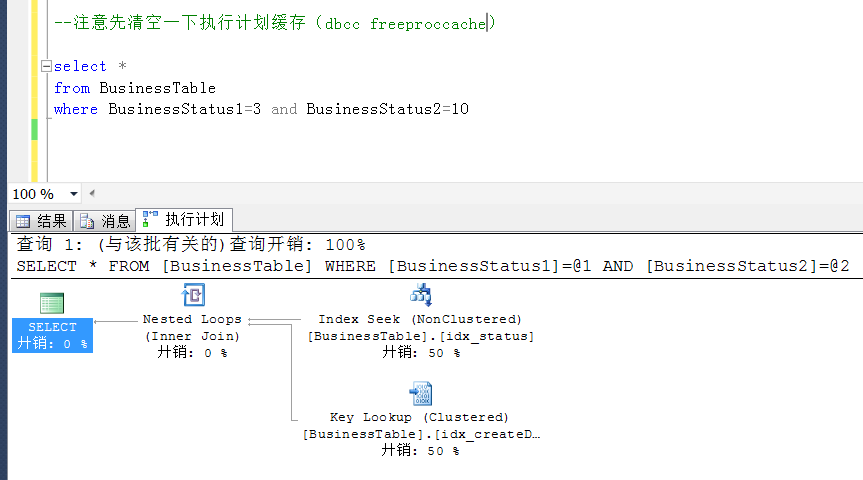
现在再来看这个查询的执行计划情况,发现其按照预期的走了索引
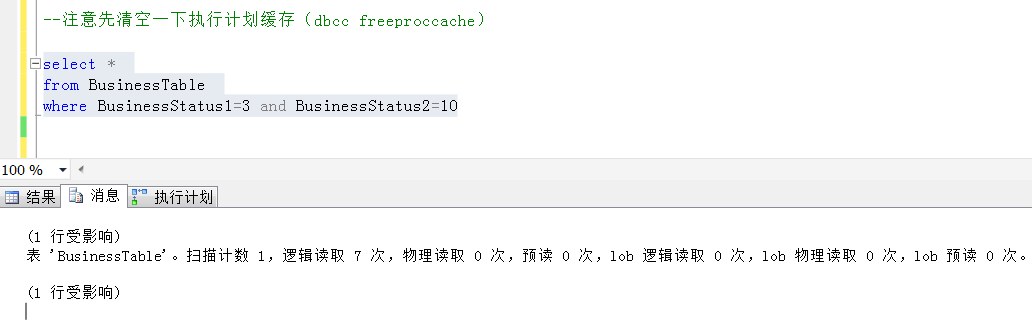
同时观察起IO情况,也有一个大幅度的下降
总结:
以上通过手动创建统计信息,来促使sqlserver在生成执行计划的时候,准确地知道数据的分布情况,做出较为优化的执行计划,在某些特殊的情况下,可以作为优化的一个考虑方向
后记:
或许有人认为这个问题该归结于parameter sniff的问题,其实这个问题跟parameter sniff还不太一样(当然也有一点像)
通常情况下,所说的parameter sniff问题是单列数据分布不均匀的情况下,因为执行计划重用导致性能地下的一个现象,重点是执行计划的不合理重用
这里的问题在于,由于统计信息的数据计算方式,sqlserver 压根无法预估到符合条件数据的准确分布,从而无法做出合理的执行计划的情况
当然这种情况也比较特殊,在强制索引提示以外,可以通过手动创建统计信息来达到优化的目的
通过手动创建统计信息优化sql查询性能案例的更多相关文章
- SQL常见优化Sql查询性能的方法有哪些?
常见优化Sql查询性能的方法有哪些? 1.查询条件减少使用函数,避免全表扫描 2.减少不必要的表连接 3.有些数据操作的业务逻辑可以放到应用层进行实现 4.可以使用with as 5.使用“临时表”暂 ...
- 优化SQL 查询性能
为什么查询会很慢 如果把查询看作是一个任务,那么它由一系列子任务组成,每个子任务都会消耗一定的时间.要优化查询,实际上是要优化其子任务,要么消除其中一些子任务,要么减少子任务的执行次数,要么让子任务运 ...
- 转载:性能优化——统计信息——SQLServer自动更新和自动创建统计信息选项
这段时间AX查询变得非常慢,每天都有很多锁. 最后发现是数据库统计信息需要更新. ----------------------------------------------------------- ...
- 性能优化——统计信息——SQLServer自动更新和自动创建统计信息选项
原文:性能优化--统计信息--SQLServer自动更新和自动创建统计信息选项 原文译自:http://www.mssqltips.com/sqlservertip/2766/sql-server-a ...
- Oracle 手动收集统计信息
收集oracle统计信息 优化器统计范围: 表统计: --行数,块数,行平均长度:all_tables:NUM_ROWS,BLOCKS,AVG_ROW_LEN: 列统计: --列中唯一值的数量(NDV ...
- Oracle 判断 并 手动收集 统计信息 脚本
CREATE OR REPLACE PROCEDURE SchameB.PRC_GATHER_STATS AUTHID CURRENT_USER IS BEGIN SYS.DBMS_STATS.GAT ...
- SQL查询性能分析
http://blog.csdn.net/dba_huangzj/article/details/8300784 SQL查询性能的好坏直接影响到整个数据库的价值,对此,必须郑重对待. SQL Serv ...
- Mysql sql查询性能侦查
Mysql 服务性能优化配置:http://5434718.blog.51cto.com/5424718/1207526[该文章很好] Sql查询性能优化 对Sql进行优化,肯定是该Sql运行未能达到 ...
- SQL Server-聚焦sp_executesql执行动态SQL查询性能真的比exec好?
前言 之前我们已经讨论过动态SQL查询呢?这里为何再来探讨一番呢?因为其中还是存在一定问题,如标题所言,很多面试题也好或者有些博客也好都在说在执行动态SQL查询时sp_executesql的性能比ex ...
随机推荐
- 欢迎进入MyKTV前后台点歌系统展示
一个项目,一分收获:一个项目,一些资源.Ktv项目也是一样的,所以我想分享我的收获,让你们获得你需要的资源. 一. 那MyKTV点歌系统具体的功能有哪些呢?我们就来看看吧! 1.MyKTV前台功能: ...
- java获取cpu和内存
利用jar包sigar 下载地址:http://sourceforge.net/projects/sigar/files/latest/download?source=files 需要将sigar-x ...
- Linux 系统的初始化配置
1.零时配置网卡IP地址 2.配置永久生效IP地址 需要进如 cd /etc/sysconfig/network-scripts 找到网卡文件编辑 3.零时主机名的更改. 4.永久主机名的更 ...
- SDOI 2016 数字配对
题目大意:给定n个数字以及每个数字的个数和权值,将满足条件的数字配对,使得总代价不小于0,且配对最多 最大费用最大流拆点,对于每个点,连一条由S到该点的边,容量为b,花费为0,再连一条到T的边 对于每 ...
- Unity3D游戏开发初探—4.开发一个“疯狂击箱子”游戏
一.预备知识—对象的”生“与”死“ (1)如何在游戏脚本程序中创建对象而不是一开始就创建好对象?->使用GameObject的静态方法:CreatePrimitive() 以上一篇的博文中的“指 ...
- 在Windows中安装Memcached
Memcached是一个高并发的内存键值对缓存系统,它的主要作用是将数据库查询结果,内容,以及其它一些耗时的计算结果缓存到系统内存中,从而加速Web应用程序的响应速度. Memcached最开始是作为 ...
- EF Codefirst 多对多关系 操作中间表的 增删改查(CRUD)
前言 此文章只是为了给新手程序员,和经验不多的程序员,在学习ef和lambada表达式的过程中可能遇到的问题. 本次使用订单表和员工表建立多对多关系. 首先是订单表: public class Ord ...
- Unsupported major.minor version 51.0
org/jboss/as/domain/management/security/adduser/AddUser : Unsupported major.minor version 51. 0 已编译好 ...
- Oracle 超长字符串分割劈分
Oracle 超长字符串分割劈分,具体能有多长没测过,反正很大.... 下面,,,,直奔主题了: CREATE OR REPLACE FUNCTION splitstr(p_string IN clo ...
- for循环或Repeat里面对某个字段进行复杂处理的解决方案
在后台用一个方法处理