mybatis 源码分析(七)KeyGenerator 详解
一、KeyGenerator 概述
在平时开发的时候经常会有这样的需求,插入数据返回主键,或者插入数据之前需要获取主键,这样的需求在 mybatis 中也是支持的,其中主要的逻辑部分就在 KeyGenerator 中,下面是他的类图:
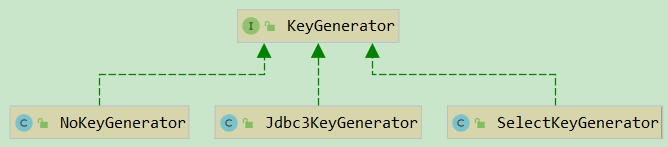
其中:
- NoKeyGenerator:默认空实现,不需要对主键单独处理;
- Jdbc3KeyGenerator:主要用于数据库的自增主键,比如 MySQL、PostgreSQL;
- SelectKeyGenerator:主要用于数据库不支持自增主键的情况,比如 Oracle、DB2;
接口方法如下:
public interface KeyGenerator {
void processBefore(Executor executor, MappedStatement ms, Statement stmt, Object parameter);
void processAfter(Executor executor, MappedStatement ms, Statement stmt, Object parameter);
}
如代码所见 KeyGenerator 非常的简单,主要是通过两个拦截方法实现的:
- Jdbc3KeyGenerator:主要基于 java.sql.Statement.getGeneratedKeys 的主键返回接口实现的,所以他不需要 processBefore 方法,只需要在获取到结果后使用 processAfter 拦截,然后用反射将主键设置到参数中即可;
- SelectKeyGenerator:主要是通过 XML 配置或者注解设置 selectKey ,然后单独发出查询语句,在返回拦截方法中使用反射设置主键,其中两个拦截方法只能使用其一,在 selectKey.order 属性中设置
AFTER|BEFORE来确定;
拦截时机:
processBefore 是在生成 StatementHandler 的时候;
protected BaseStatementHandler(Executor executor, MappedStatement mappedStatement, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler, BoundSql boundSql) {
...
if (boundSql == null) { // issue #435, get the key before calculating the statement
generateKeys(parameterObject);
boundSql = mappedStatement.getBoundSql(parameterObject);
}
...
}
protected void generateKeys(Object parameter) {
KeyGenerator keyGenerator = mappedStatement.getKeyGenerator();
ErrorContext.instance().store();
keyGenerator.processBefore(executor, mappedStatement, null, parameter);
ErrorContext.instance().recall();
}
processAfter 则是在完成插入返回结果之前,但是 PreparedStatementHandler、SimpleStatementHandler、CallableStatementHandler 的代码稍微有一点不同,但是位置是不变的,这里以 PreparedStatementHandler 举例:
@Override
public int update(Statement statement) throws SQLException {
PreparedStatement ps = (PreparedStatement) statement;
ps.execute();
int rows = ps.getUpdateCount();
Object parameterObject = boundSql.getParameterObject();
KeyGenerator keyGenerator = mappedStatement.getKeyGenerator();
keyGenerator.processAfter(executor, mappedStatement, ps, parameterObject);
return rows;
}
二、Jdbc3KeyGenerator
上面也将了 Jdbc3KeyGenerator 是主要基于 java.sql.Statement.getGeneratedKeys 的主键返回接口实现的,但是 Statement 和 PreparedStatement 稍有不同,所以导致了 PreparedStatementHandler、SimpleStatementHandler 的 update 方法稍有不同:
// java.sql.Connection
PreparedStatement prepareStatement(String sql, int autoGeneratedKeys) throws SQLException;
PreparedStatement prepareStatement(String sql, String columnNames[]) throws SQLException;
PreparedStatement prepareStatement(String sql, int columnIndexes[]) throws SQLException;
// java.sql.Statement
boolean execute(String sql, int autoGeneratedKeys) throws SQLException;
boolean execute(String sql, int columnIndexes[]) throws SQLException;
boolean execute(String sql, String columnNames[]) throws SQLException;
// 其中 autoGenerateKeys - Statement.RETURN_GENERATED_KEYS、Statement.NO_GENERATED_KEYS
可以看到 PreparedStatement 是在实例化的时候就指定了,而 Statement 是在执行 sql 的时候才指定但实质是一样的,这里就以 PreparedStatement 举例:
public void testJDBC3() {
try {
String url = "jdbc:mysql://localhost:3306/mybatis?serverTimezone=GMT";
String sql = "INSERT INTO user(username,password,address) VALUES (?,?,?)";
Class.forName("com.mysql.jdbc.Driver");
Connection conn = DriverManager.getConnection(url, "root", "root");
String[] columnNames = {"ids", "name"};
PreparedStatement stmt = conn.prepareStatement(sql, columnNames);
stmt.setString(1, "test");
stmt.setString(2, "123456");
stmt.setString(3, "test");
stmt.executeUpdate();
ResultSet rs = stmt.getGeneratedKeys();
int id = 0;
if (rs.next()) {
id = rs.getInt(1);
System.out.println("----------" + id);
}
} catch (Exception e) {
e.printStackTrace();
}
}
这里的 User 表以 id 为主键,但是代码中我传的 columnNames 都不符合,而结果仍然可以正确的返回主键,主要是因为在 mybatis 的驱动中只要 columnNames.length > 1就可以了,所以在具体使用的时候还要注意不同数据库驱动实现不同所带来的影响;
上面将了 Statement 和 PreparedStatement 指定返回主键的位置不同,在下面就能很清楚的看到:
// org.apache.ibatis.executor.statement.SimpleStatementHandler
public int update(Statement statement) throws SQLException {
String sql = boundSql.getSql();
Object parameterObject = boundSql.getParameterObject();
KeyGenerator keyGenerator = mappedStatement.getKeyGenerator();
int rows;
if (keyGenerator instanceof Jdbc3KeyGenerator) {
statement.execute(sql, Statement.RETURN_GENERATED_KEYS);
rows = statement.getUpdateCount();
keyGenerator.processAfter(executor, mappedStatement, statement, parameterObject);
} else if (keyGenerator instanceof SelectKeyGenerator) {
statement.execute(sql);
rows = statement.getUpdateCount();
keyGenerator.processAfter(executor, mappedStatement, statement, parameterObject);
} else {
//如果没有keyGenerator,直接调用Statement.execute和Statement.getUpdateCount
statement.execute(sql);
rows = statement.getUpdateCount();
}
return rows;
}
// org.apache.ibatis.executor.statement.PreparedStatementHandler
protected Statement instantiateStatement(Connection connection) throws SQLException {
String sql = boundSql.getSql();
if (mappedStatement.getKeyGenerator() instanceof Jdbc3KeyGenerator) {
String[] keyColumnNames = mappedStatement.getKeyColumns();
if (keyColumnNames == null) {
return connection.prepareStatement(sql, PreparedStatement.RETURN_GENERATED_KEYS);
} else {
return connection.prepareStatement(sql, keyColumnNames);
}
} else if (mappedStatement.getResultSetType() != null) {
return connection.prepareStatement(sql, mappedStatement.getResultSetType().getValue(), ResultSet.CONCUR_READ_ONLY);
} else {
return connection.prepareStatement(sql);
}
}
在完成初始化后,下面来看 Jdbc3KeyGenerator 中最主要的拦截方法:
public void processAfter(Executor executor, MappedStatement ms, Statement stmt, Object parameter) {
List<Object> parameters = new ArrayList<Object>();
parameters.add(parameter);
processBatch(ms, stmt, parameters);
}
public void processBatch(MappedStatement ms, Statement stmt, List<Object> parameters) {
ResultSet rs = null;
try {
//核心是使用JDBC3的Statement.getGeneratedKeys
rs = stmt.getGeneratedKeys();
final Configuration configuration = ms.getConfiguration();
final TypeHandlerRegistry typeHandlerRegistry = configuration.getTypeHandlerRegistry();
final String[] keyProperties = ms.getKeyProperties();
final ResultSetMetaData rsmd = rs.getMetaData();
TypeHandler<?>[] typeHandlers = null;
if (keyProperties != null && rsmd.getColumnCount() >= keyProperties.length) {
for (Object parameter : parameters) {
// there should be one row for each statement (also one for each parameter)
if (!rs.next()) {
break;
}
final MetaObject metaParam = configuration.newMetaObject(parameter);
if (typeHandlers == null) {
//先取得类型处理器
typeHandlers = getTypeHandlers(typeHandlerRegistry, metaParam, keyProperties);
}
//填充键值
populateKeys(rs, metaParam, keyProperties, typeHandlers);
}
}
} catch (Exception e) {
...
}
}
这里就很清楚了,直接获取返回的主键,然后一次使用反射设置到参数中;
三、SelectKeyGenerator
上面也讲了 SelectKeyGenerator 主要是配置 selectKey 使用的,默认 使用 processBefore,但是可以配置 order 属性(AFTER|BEFORE);
<insert id="insertUser2" parameterType="u" useGeneratedKeys="true" keyProperty="id">
<selectKey keyProperty="id" resultType="long" order="BEFORE">
SELECT if(max(id) is null,1,max(id)+2) as newId FROM user2
</selectKey>
INSERT INTO user2(id,username,password,address) VALUES (#{id},#{userName},#{password},#{address})
</insert>
这里直接看源码:
public void processBefore(Executor executor, MappedStatement ms, Statement stmt, Object parameter) {
if (executeBefore) processGeneratedKeys(executor, ms, parameter);
}
public void processAfter(Executor executor, MappedStatement ms, Statement stmt, Object parameter) {
if (!executeBefore) processGeneratedKeys(executor, ms, parameter);
}
private void processGeneratedKeys(Executor executor, MappedStatement ms, Object parameter) {
try {
if (parameter != null && keyStatement != null && keyStatement.getKeyProperties() != null) {
String[] keyProperties = keyStatement.getKeyProperties();
final Configuration configuration = ms.getConfiguration();
final MetaObject metaParam = configuration.newMetaObject(parameter);
if (keyProperties != null) {
// Do not close keyExecutor.
// The transaction will be closed by parent executor.
Executor keyExecutor = configuration.newExecutor(executor.getTransaction(), ExecutorType.SIMPLE);
List<Object> values = keyExecutor.query(keyStatement, parameter, RowBounds.DEFAULT, Executor.NO_RESULT_HANDLER);
if (values.size() == 0) {
throw new ExecutorException("SelectKey returned no data.");
} else if (values.size() > 1) {
throw new ExecutorException("SelectKey returned more than one value.");
} else {
MetaObject metaResult = configuration.newMetaObject(values.get(0));
if (keyProperties.length == 1) {
if (metaResult.hasGetter(keyProperties[0])) {
setValue(metaParam, keyProperties[0], metaResult.getValue(keyProperties[0]));
} else {
// no getter for the property - maybe just a single value object
// so try that
setValue(metaParam, keyProperties[0], values.get(0));
}
} else {
handleMultipleProperties(keyProperties, metaParam, metaResult);
}
}
}
}
} catch (ExecutorException e) {
...
}
}
这里代码也很简单,就是用一个新的 Executor 再发一条 SQL,然后反射设置参数即可;
mybatis 源码分析(七)KeyGenerator 详解的更多相关文章
- 【集合框架】JDK1.8源码分析之ArrayList详解(一)
[集合框架]JDK1.8源码分析之ArrayList详解(一) 一. 从ArrayList字表面推测 ArrayList类的命名是由Array和List单词组合而成,Array的中文意思是数组,Lis ...
- nginx源码分析线程池详解
nginx源码分析线程池详解 一.前言 nginx是采用多进程模型,master和worker之间主要通过pipe管道的方式进行通信,多进程的优势就在于各个进程互不影响.但是经常会有人问道,n ...
- vuex 源码分析(六) 辅助函数 详解
对于state.getter.mutation.action来说,如果每次使用的时候都用this.$store.state.this.$store.getter等引用,会比较麻烦,代码也重复和冗余,我 ...
- vuex 源码分析(五) action 详解
action类似于mutation,不同的是Action提交的是mutation,而不是直接变更状态,而且action里可以包含任意异步操作,每个mutation的参数1是一个对象,可以包含如下六个属 ...
- Golang源码分析之目录详解
开源项目「go home」聚焦Go语言技术栈与面试题,以协助Gopher登上更大的舞台,欢迎go home~ 导读 学习Go语言源码的第一步就是了解先了解它的目录结构,你对它的源码目录了解多少呢? 目 ...
- Tomcat源码分析 | 一文详解生命周期机制Lifecycle
目录 什么是Lifecycle? Lifecycle方法 LifecycleBase 增加.删除和获取监听器 init() start() stop() destroy() 模板方法 总结 前言 To ...
- Java 容器源码分析之集合类详解
集合类说明及区别 Collection ├List │├LinkedList │├ArrayList │└Vector │ └Stack └Set Map ├Hashtable ├HashMap └W ...
- Cloudera Impala源码分析: SimpleScheduler调度策略详解包括作用、接口及实现等
问题导读:1.Scheduler任务中Distributed Plan.Scan Range是什么?2.Scheduler基本接口有哪些?3.QuerySchedule这个类如何理解?4.Simple ...
- MyBatis源码分析-MyBatis初始化流程
MyBatis 是支持定制化 SQL.存储过程以及高级映射的优秀的持久层框架.MyBatis 避免了几乎所有的 JDBC 代码和手动设置参数以及获取结果集.MyBatis 可以对配置和原生Map使用简 ...
- Mybatis源码分析-StatementHandler
承接前文Mybatis源码分析-BaseExecutor,本文则对通过StatementHandler接口完成数据库的CRUD操作作简单的分析 StatementHandler#接口列表 //获取St ...
随机推荐
- 数据库---T-SQL语句(一)
一.T-SQL语句 1.创建表:create table Name(Code varchar(50),) 主键:primary key 自增长:auto_increment 外键关系:referenc ...
- Java性能调优之让程序“飞”起来-Java 代码优化
代码优化的目标是: 1.减小代码的体积 2.提高代码运行的效率 代码优化细节 1.尽量指定类.方法的final修饰符 带有final修饰符的类是不可派生的.在Java核心API中,有许多应用final ...
- div span img对齐,垂直居中对齐问题
我想你们在前端开发中或多或少都遇到过这种问题,文字和图片不能平齐,很是头疼. HTML代码: <div class="">小太阳<span>小太阳</ ...
- Linux学习笔记03
一.Linux常见命令 file:查看文件类型(windows用扩展名识别文件类型) 语法:file [options] [args] -b:显示结果时,不显示文件名 -c:显示执行file命令的执行 ...
- 跟着阿里p7一起学java高并发 - 第19天:JUC中的Executor框架详解1,全面掌握java并发核心技术
这是java高并发系列第19篇文章. 本文主要内容 介绍Executor框架相关内容 介绍Executor 介绍ExecutorService 介绍线程池ThreadPoolExecutor及案例 介 ...
- python多线程详解
目录 python多线程详解 一.线程介绍 什么是线程 为什么要使用多线程 二.线程实现 threading模块 自定义线程 守护线程 主线程等待子线程结束 多线程共享全局变量 互斥锁 递归锁 信号量 ...
- memcached.c 源码分析
上文分析了memcached的autoconf过程以及configure, make过程,可以看到,memcached可执行文件是由memcached-memcached.o以及其他文件连接后编译出来 ...
- Java悲观锁Pessimistic-Lock常用实现场景
1:商品库存秒杀采用悲观锁Pessimistic-Lock主要好处是安全,充分利用了数据库的性能来做的一种锁机制. 悲观锁的实现: (1)环境:mysql + jdbctemplate (2)商品表g ...
- 使用Junit测试一个 spring静态工厂实例化bean 的例子,所有代码都没有问题,但是出现java.lang.IllegalArgumentException异常
使用Junit测试一个spring静态工厂实例化bean的例子,所有代码都没有问题,但是出现 java.lang.IllegalArgumentException 异常, 如下图所示: 开始以为是代码 ...
- 3、大型项目的接口自动化实践记录----开放API练习
开始做实际项目前,先拿个网上的简单API练下手 一.API说明: 接口信息 接口名:京东获取单个商品价格 地址:http://p.3.cn/prices/mgets 入参:skuids=J_商品ID& ...