solr学习篇(二) solr 分词器篇
关于solr7.4搭建与配置可以参考 solr7.4 安装配置篇 在这里我们探讨一下分词的配置
目录
1.关于分词
1.分词是指将一个中文词语拆成若干个词,提供搜索引擎进行查找,比如说:北京大学 是一个词那么进行拆分可以得到:北京与大学,甚至北京大学整个词也是一个语义
2.市面上常见的分词工具有 IKAnalyzer MMSeg4j Paoding等,这几个分词器各有优劣,大家可以自行研究
在这篇文章,我先演示IKAnalyzer分词器 下载:IKAnalyzer
2.拷贝相关Jar包与配置
下载解压后 把这两个jar文件复制到solr-7.4.0\server\solr-webapp\webapp\WEB-INF\lib中
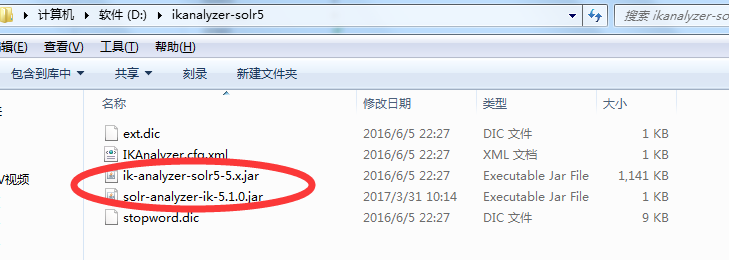
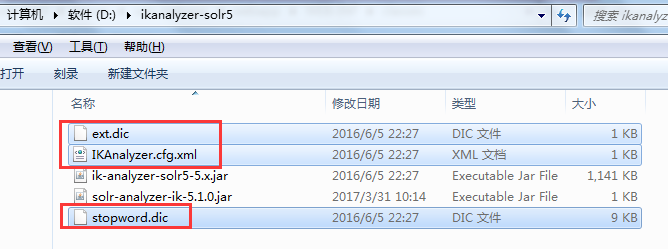
然后在solr-7.4.0\server\solr-webapp\webapp\WEB-INF\目录下新建一个classes目录,把下面三个文件复制进去
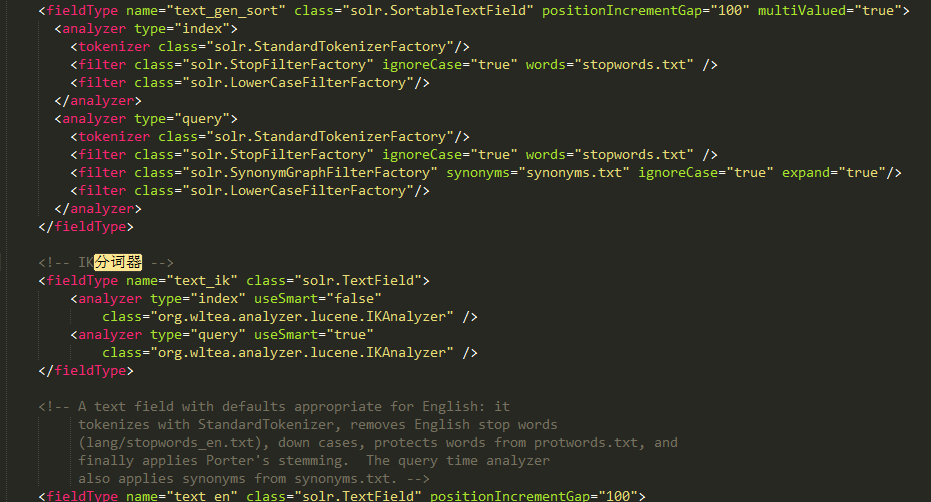
进入之前创建的core 在solr-7.4.0\server\solr\newCore\conf下打开managed-schema.xml 添加如下代码:
<fieldType name="text_ik" class="solr.TextField">
<analyzer type="index" useSmart="false"
class="org.wltea.analyzer.lucene.IKAnalyzer" />
<analyzer type="query" useSmart="true"
class="org.wltea.analyzer.lucene.IKAnalyzer" />
</fieldType>
在这里我们发现并没有schema.xml。这是因为Solr版本中(Solr5之前),在创建core的时候,Solr会自动创建好schema.xml,但是在之后的版本中,新加入了动态更新schema功能,这个默认的schema.xml确找不到了,在Solr5以后,这个schema文件已经不是默认生成好的了,它被取了一个名字managed-schema,并且没有后缀。乍一看,以为是打不开的文件,当然没有什么能难倒程序员的,用Sublime Text 3打开,发现了熟悉的文字,这不就是之前的schema.xml文件吗。

3.验证成功
打开服务,打开你所创建的core
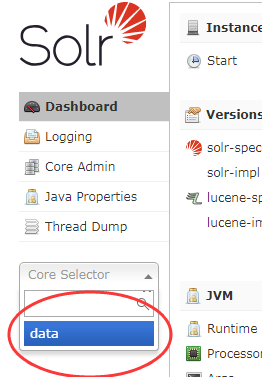
选择Analysis 输入要搜索的中文 选择FieldType为text_ik 可以发现分词成功
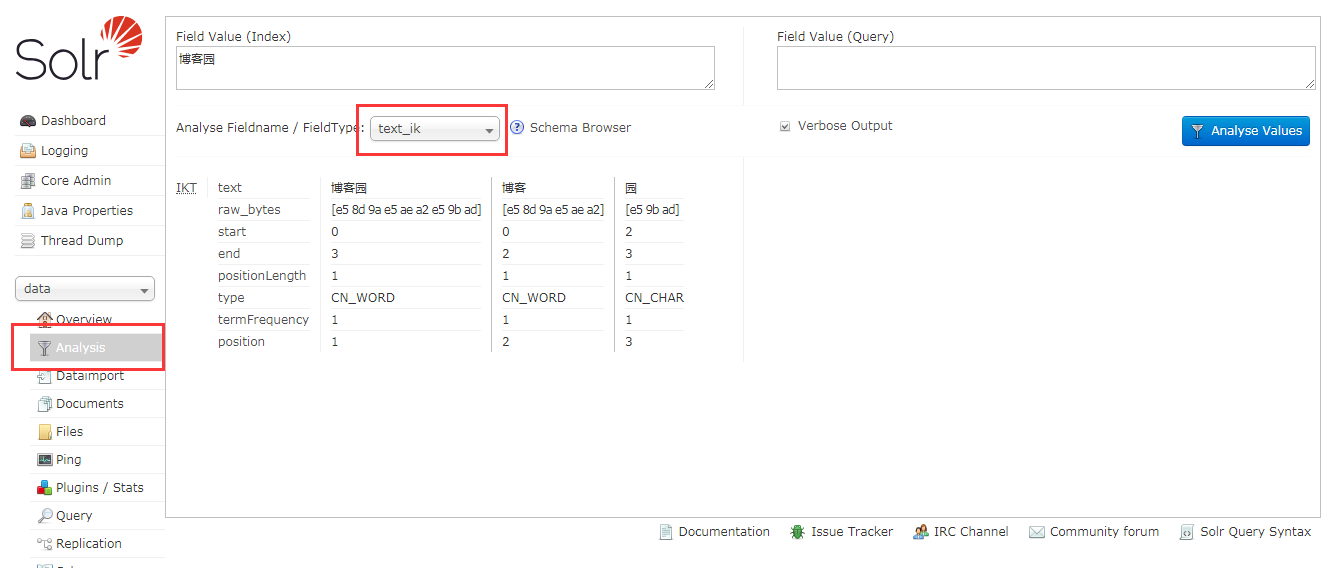
注意filedType一定选择我们配置的分词类型text_ik
----------------------------------------------------------------分割线----------------------------------------------------
有朋友私信说配置好了并没有ik
这是因为本文中我用的 上一篇中的第一种方式创建的code,这种方式连接数据库不是特别好,应该使用第二种命令创建。
但是命令创建后的conf目录是需要去 solr{home}\example\example-DIH\solr\db下的文件进行复制。 详情请参考下一篇。
solr学习篇(二) solr 分词器篇的更多相关文章
- 13.solr学习速成之IK分词器
IKAnalyzer简介 IKAnalyzer是一个开源的,基于java语言开发的轻量级的中文分词工具包. IKAnalyzer特性 a. 算法采用“正向迭代最细粒度切分算法”,支持细粒度和最大词长两 ...
- Solr学习之二-Solr基础知识
一 基本说明 简单来说Solr是基于Lucene的高性能的,开源的Java企业搜索服务器.Solr可以看作一个Web app,运行在tomcat或Jetty这类HTTP服务器上, 底层是一个基于Luc ...
- Solr4.4入门,介绍Solr的安装、IK分词器的配置及高亮查询结果(转)
一.Windows下安装solr-4.4.0 1. 下载solr.4.4 2. 下载绿色版tomcat6.0.18 3. 解压下载的solr到d:\study\solr,将dist目录下的sol ...
- 【three.js详解之二】渲染器篇
[three.js详解之二]渲染器篇 本篇文章将详细讲解three.js中渲染器(renderer)的设置方法. three.js文档中渲染器的分支如下: Renderers CanvasRend ...
- solr英文使用的基本分词器和过滤器配置
solr英文应用的基本分词器和过滤器配置 英文应用分词器和过滤器一般配置顺序 索引(index): 1:空格 WhitespaceTokenizer 2:过滤词(停用词,如:on.of.a.an ...
- solr常用操作及集成分词器或cdh集群部署说明
首先,如果是从http://lucene.apache.org/solr/下载的solr,基本都是自带集成的jetty服务,不需要单独搭建tomcat环境,但是要注意jdk版本,直接解压通过cmd命令 ...
- lucene&solr学习——创建和查询索引(代码篇)
1. Lucene的下载 Lucene是开发全文检索功能的工具包,从官网下载Lucene4.10.3并解压. 官网:http://lucene.apache.org/ 版本:lucene7.7.0 ( ...
- Solr 06 - Solr中配置使用IK分词器 (配置schema.xml)
目录 1 配置中文分词器 1.1 准备IK中文分词器 1.2 配置schema.xml文件 1.3 重启Tomcat并测试 2 配置业务域 2.1 准备商品数据 2.2 配置商品业务域 2.3 配置s ...
- Solr学习笔记---部署Solr到Tomcat上,可视化界面的介绍和使用,Solr的基本内容介绍,SolrJ的使用
学习Solr前需要有Lucene的基础 Lucene的一些简单用法:https://www.cnblogs.com/dddyyy/p/9842760.html 1.部署Solr到Tomcat(Wind ...
随机推荐
- Spring boot 梳理 - SpringApplication
简单启动方式 public static void main(String[] args) { SpringApplication.run(MySpringConfiguration.class, a ...
- [Week 2][Guarantee of PLA] the Correctness Verification of PLA
Conditions: For the data set D, there exists a $\displaystyle W_{f}$ which satisfies that for every ...
- Scanner类的next()方法和nextLine()方法的异同点
通过一段代码就可以明白其中的奥妙!! import java.util.Scanner; public class next_nextLine { public static void main(St ...
- Win10下80端口被System占用导致Apache无法启动
Windows10下80端口被PID为4的System占用导致Apache无法启动的分析与解决方案 方法/步骤 最近更新了Windows10,总体上来说效果还是蛮不错的,然而今天在开启Apac ...
- ng-cli新建项目
tip:所有的命令是红色标签 , 链接为蓝色标签 使用ng-cli创建新的项目一般需要安装一些新的东西后才可以进行创建成功 1.需要先安装node.js 链接: https://nodejs.org ...
- mysql库复制
一.使用navicate复制mysql库 二.使用命令 通过命令:1.创建新数据库CREATE DATABASE `newdb` DEFAULT CHARACTER SET UTF8 COLLATE ...
- MongoDB 学习笔记之 批处理
批处理: MongoDB批处理方式有2种, 有序插入(有序仍是顺序处理的.发生错误就停止.) 无序插入(无序列表会将操作按类型分组,来提高性能,因此,应确保应用不依赖操作执行顺序.发生错误继续处理剩余 ...
- Flask上下文管理机制流程(源码剖析)
Flask请求上下文管理 1 偏函数 partial 使用该方式可以生成一个新函数 from functools import partial def mod( n, m ): return n % ...
- Javascript设计模式——建造者模式
建造者模式是相对比较简单的一种设计模式,属于创建型模式的一种: 定义:将一个复杂的对象分解成多个简单的对象来进行构建,将复杂的构建层与表现层分离,使相同的构建过程可以创建不同的表示模式: 优点: ...
- Hyper-V虚拟机win7网络红叉,无法上网解决方法
之前一直都是玩Vmware虚拟机,后来win8之后的系统有Hyper-V虚拟机就开始接触了. Windows 中内置的Hyper-V管理器可以说是给很多人带来了惊喜!至少运行的流畅程度要比Vmware ...