solr学习篇(二) solr 分词器篇
关于solr7.4搭建与配置可以参考 solr7.4 安装配置篇 在这里我们探讨一下分词的配置
目录
1.关于分词
1.分词是指将一个中文词语拆成若干个词,提供搜索引擎进行查找,比如说:北京大学 是一个词那么进行拆分可以得到:北京与大学,甚至北京大学整个词也是一个语义
2.市面上常见的分词工具有 IKAnalyzer MMSeg4j Paoding等,这几个分词器各有优劣,大家可以自行研究
在这篇文章,我先演示IKAnalyzer分词器 下载:IKAnalyzer
2.拷贝相关Jar包与配置
下载解压后 把这两个jar文件复制到solr-7.4.0\server\solr-webapp\webapp\WEB-INF\lib中
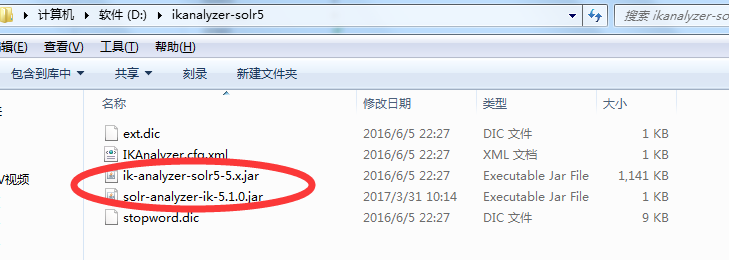
然后在solr-7.4.0\server\solr-webapp\webapp\WEB-INF\目录下新建一个classes目录,把下面三个文件复制进去
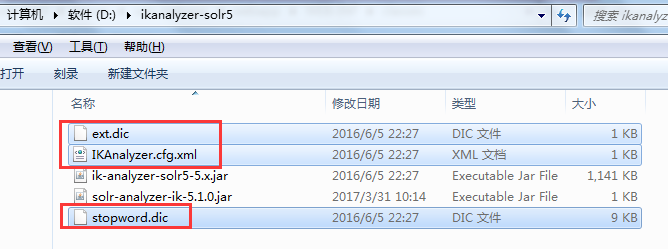
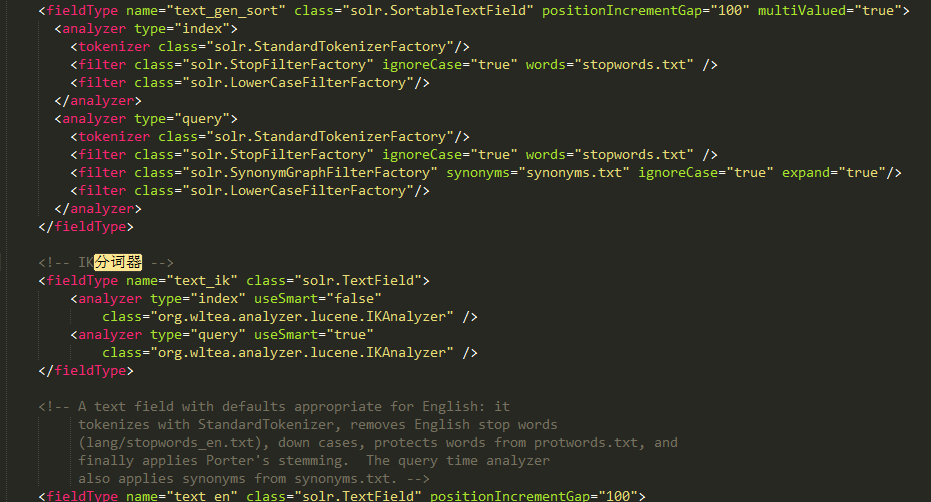
进入之前创建的core 在solr-7.4.0\server\solr\newCore\conf下打开managed-schema.xml 添加如下代码:
<fieldType name="text_ik" class="solr.TextField">
<analyzer type="index" useSmart="false"
class="org.wltea.analyzer.lucene.IKAnalyzer" />
<analyzer type="query" useSmart="true"
class="org.wltea.analyzer.lucene.IKAnalyzer" />
</fieldType>
在这里我们发现并没有schema.xml。这是因为Solr版本中(Solr5之前),在创建core的时候,Solr会自动创建好schema.xml,但是在之后的版本中,新加入了动态更新schema功能,这个默认的schema.xml确找不到了,在Solr5以后,这个schema文件已经不是默认生成好的了,它被取了一个名字managed-schema,并且没有后缀。乍一看,以为是打不开的文件,当然没有什么能难倒程序员的,用Sublime Text 3打开,发现了熟悉的文字,这不就是之前的schema.xml文件吗。

3.验证成功
打开服务,打开你所创建的core
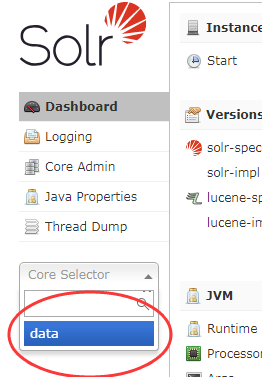
选择Analysis 输入要搜索的中文 选择FieldType为text_ik 可以发现分词成功
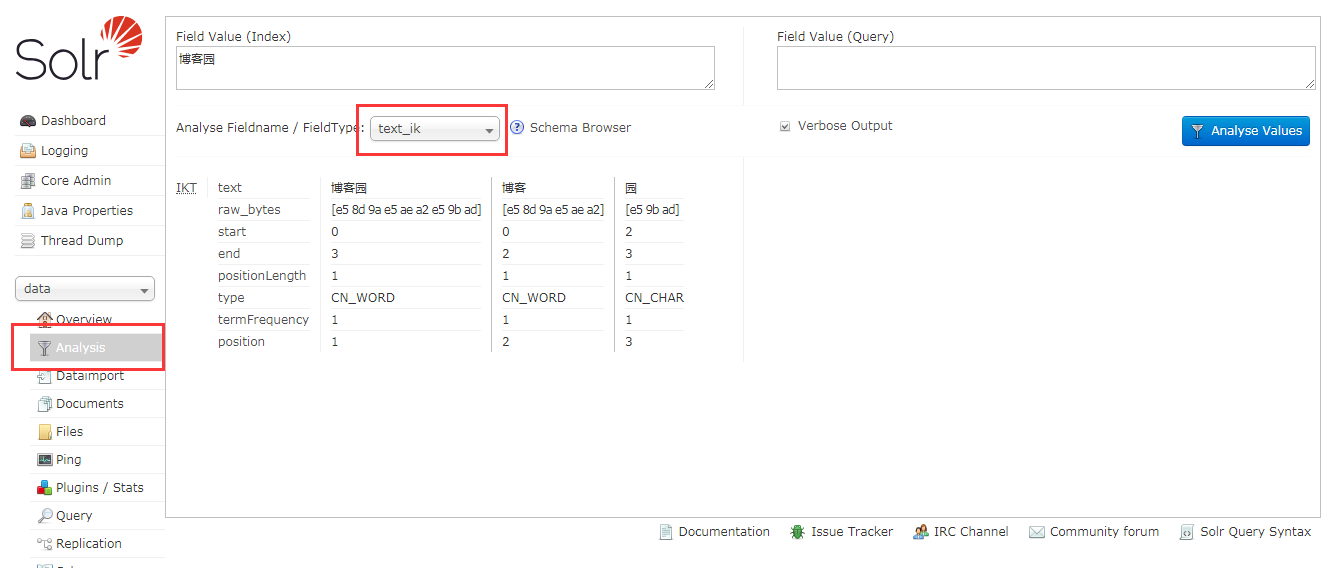
注意filedType一定选择我们配置的分词类型text_ik
----------------------------------------------------------------分割线----------------------------------------------------
有朋友私信说配置好了并没有ik
这是因为本文中我用的 上一篇中的第一种方式创建的code,这种方式连接数据库不是特别好,应该使用第二种命令创建。
但是命令创建后的conf目录是需要去 solr{home}\example\example-DIH\solr\db下的文件进行复制。 详情请参考下一篇。
solr学习篇(二) solr 分词器篇的更多相关文章
- 13.solr学习速成之IK分词器
IKAnalyzer简介 IKAnalyzer是一个开源的,基于java语言开发的轻量级的中文分词工具包. IKAnalyzer特性 a. 算法采用“正向迭代最细粒度切分算法”,支持细粒度和最大词长两 ...
- Solr学习之二-Solr基础知识
一 基本说明 简单来说Solr是基于Lucene的高性能的,开源的Java企业搜索服务器.Solr可以看作一个Web app,运行在tomcat或Jetty这类HTTP服务器上, 底层是一个基于Luc ...
- Solr4.4入门,介绍Solr的安装、IK分词器的配置及高亮查询结果(转)
一.Windows下安装solr-4.4.0 1. 下载solr.4.4 2. 下载绿色版tomcat6.0.18 3. 解压下载的solr到d:\study\solr,将dist目录下的sol ...
- 【three.js详解之二】渲染器篇
[three.js详解之二]渲染器篇 本篇文章将详细讲解three.js中渲染器(renderer)的设置方法. three.js文档中渲染器的分支如下: Renderers CanvasRend ...
- solr英文使用的基本分词器和过滤器配置
solr英文应用的基本分词器和过滤器配置 英文应用分词器和过滤器一般配置顺序 索引(index): 1:空格 WhitespaceTokenizer 2:过滤词(停用词,如:on.of.a.an ...
- solr常用操作及集成分词器或cdh集群部署说明
首先,如果是从http://lucene.apache.org/solr/下载的solr,基本都是自带集成的jetty服务,不需要单独搭建tomcat环境,但是要注意jdk版本,直接解压通过cmd命令 ...
- lucene&solr学习——创建和查询索引(代码篇)
1. Lucene的下载 Lucene是开发全文检索功能的工具包,从官网下载Lucene4.10.3并解压. 官网:http://lucene.apache.org/ 版本:lucene7.7.0 ( ...
- Solr 06 - Solr中配置使用IK分词器 (配置schema.xml)
目录 1 配置中文分词器 1.1 准备IK中文分词器 1.2 配置schema.xml文件 1.3 重启Tomcat并测试 2 配置业务域 2.1 准备商品数据 2.2 配置商品业务域 2.3 配置s ...
- Solr学习笔记---部署Solr到Tomcat上,可视化界面的介绍和使用,Solr的基本内容介绍,SolrJ的使用
学习Solr前需要有Lucene的基础 Lucene的一些简单用法:https://www.cnblogs.com/dddyyy/p/9842760.html 1.部署Solr到Tomcat(Wind ...
随机推荐
- 运用 CSS in JS 实现模块化
一.什么是 CSS in JS 上图来源:https://2019.stateofcss.com/technologies/ CSS in JS 是2014年推出的一种设计模式,它的核心思想是把 CS ...
- selenium-03-常用操作
基本介绍: Selenium工具专门为WEB应用程序编写的一个验收测试工具. Selenium的核心:browser bot,是用JavaScript编写的. Selenium工具有4种:Seleni ...
- java8 函数接口
[前言] java8新特性 java8 Optional使用总结 java8 lambda表达式 Java 8 时间日期使用 1.函数式接口新特性 java8中引入了函数式接口新特性,使用@Funct ...
- go语言标准库之http/template
html/template包实现了数据驱动的模板,用于生成可对抗代码注入的安全HTML输出.它提供了和text/template包相同的接口,Go语言中输出HTML的场景都应使用text/templa ...
- ng 图片的引用
对于图片的引用有两种类型 本地 业务逻辑中(使用url) 本地中图片需要存放在静态资源夹assets中下新建的文件夹images文件夹中 eg:images文件夹中有一张01.png 的图片 显示本地 ...
- kali切换到西电源
准备研究kali的openvas,打开发现居然没有.apt-get更新一下结果各种报错,换成中科大源.阿里源还是始终报错,气到吐血.最后上西电开源社区换成了西电的kali源,更新速度2m多,一气呵成~ ...
- SpringBoot源码分析之---SpringBoot项目启动类SpringApplication浅析
源码版本说明 本文源码采用版本为SpringBoot 2.1.0BUILD,对应的SpringFramework 5.1.0.RC1 注意:本文只是从整体上梳理流程,不做具体深入分析 SpringBo ...
- JS中的prototype、__proto__与constructor
1.前言 作为一名前端工程师,必须搞懂JS中的prototype.__proto__与constructor属性,相信很多初学者对这些属性存在许多困惑,容易把它们混淆,本文旨在帮助大家理清它们之间的关 ...
- Redis 介绍学习
1.Redis 简介 Redis 是一个支持数据结构更多的键值对数据库.它的值不仅可以是字符串等基本数据 类型,也可以是类对象,更可以是 Set.List.计数器等高级的数据结构. Memcached ...
- 加密解密 之base系列编码
Base16 Base16编码使用16个ASCII可打印字符(数字0-9和字母A-F)对任意字节数据进行编码.Base16先获取输入字符串每个字节的二进制值(不足8比特在高位补0),然后将其串联进来, ...