sqlserver的表变量在没有预估偏差的情况下,与物理表可join产生的性能问题
众所周知,在sqlserver中,表变量最大的特性之一就是没有统计信息,无法较为准备预估其数据分布情况,因此不适合参与较为复杂的SQL运算。
当SQL相对简单的时候,使用表变量,在某些场景下,即便是对表变量的预估没有产生偏差的情况下,仍旧会有问题。
sqlserver的优化引擎对于表变量的支持十分不友好,再次对表变量的使用产生了警惕。
测试环境搭建
理搭建一个简单的测试环境,来验证本文的想要表达的主题,
测试表TestTableVariable 上有KeyCode1 ~KeyCode5 5个字段,分别创建非聚集索引,
对于数据分布,刻意设计出当前这种场景:KeyCode1 ~KeyCode5的字段值,分别趋于稀疏(非空值的越来越少,null值越来越多)
如下,写入100W行数据,就可以出来下面要表达的效果了。
create table TestTableVariable
(
Id int identity(1,1),
KeyCode1 varchar(10),
KeyCode2 varchar(10),
KeyCode3 varchar(10),
KeyCode4 varchar(10),
KeyCode5 varchar(10),
CreateDate datetime
) alter table TestTableVariable
add constraint pk_TestTableVariable primary key(Id) create index idx_KeyCode1 on TestTableVariable(KeyCode1)
create index idx_KeyCode2 on TestTableVariable(KeyCode2)
create index idx_KeyCode3 on TestTableVariable(KeyCode3)
create index idx_KeyCode4 on TestTableVariable(KeyCode4)
create index idx_KeyCode5 on TestTableVariable(KeyCode5) insert into TestTableVariable(KeyCode1,CreateDate) values (CONCAT('XX',CAST(RAND()*1000000 AS INT)),GETDATE())
GO 1000000 update TestTableVariable set KeyCode2 = KeyCode1 where Id%10 = 0
update TestTableVariable set KeyCode3 = KeyCode1 where Id%1000 = 0
update TestTableVariable set KeyCode4 = KeyCode1 where Id%10000= 0
update TestTableVariable set KeyCode5 = KeyCode1 where Id%100000 = 0
GO
问题重现
对于普通的查询,找一个KeyCode1 ~KeyCode5均有值的条件进行查询,执行计划都在预期之中,均可以用到索引,不过多表述
select * from TestTableVariable where KeyCode1 = 'XX156876'
select * from TestTableVariable where KeyCode2 = 'XX156876'
select * from TestTableVariable where KeyCode3 = 'XX156876'
select * from TestTableVariable where KeyCode4 = 'XX156876'
select * from TestTableVariable where KeyCode5 = 'XX156876'
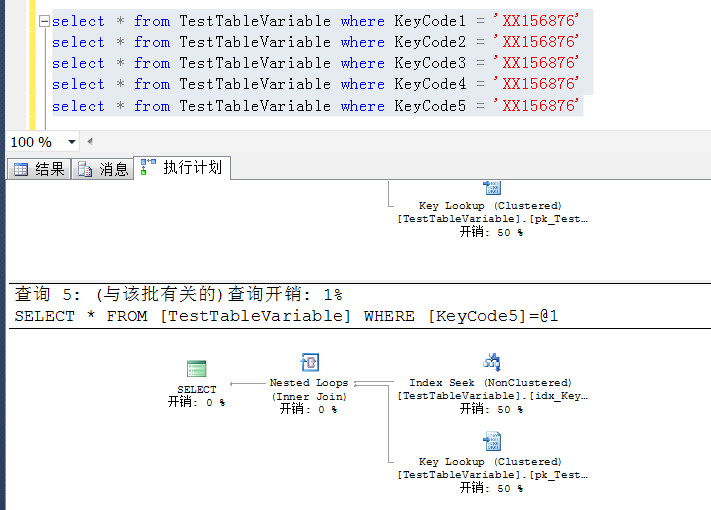
下面将查询条件写入一张表变,让表变量与物理表TestTableVariable进行join
如下语句,分别用KeyCode1 ~KeyCode5进行查询,对于非空值分布相对较多的KeyCode1 ~KeyCode3,做查询的时候,执行计划也在预期之中(索引查找)
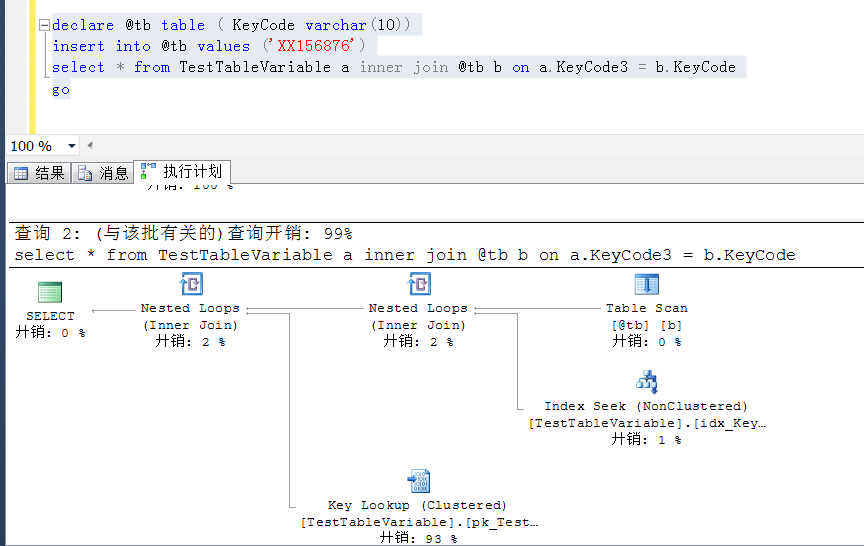
从非空值分布越来越少的KeyCode4开始,执行计划开始变成非预期的索引查找,变成了表扫描
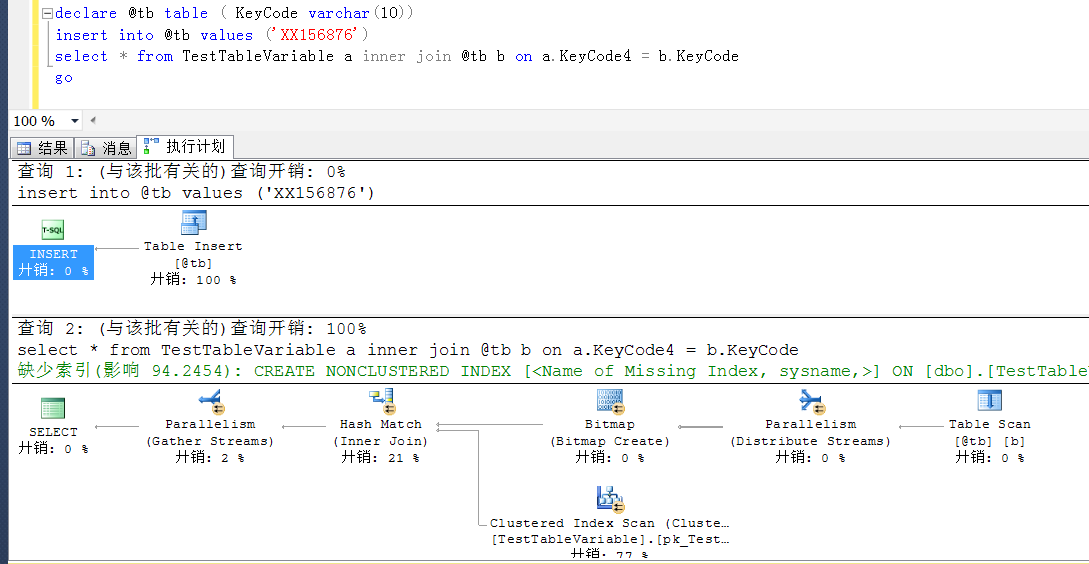
KeyCode5依旧是非预期的索引查找,也是表扫描
这里不是提出类似问题的解决办法的,当然解决办法也比较简单,
1,添加一个不影响逻辑的条件,相当于简单地改写SQL,如下增加where a.KeyCode5 is not null 筛选条件,因为null值不等于任何值,包括null值,因此增加这个条件不会影响这个SQL的逻辑
2,将表变量的数据写入临时表,让临时表与测试表JOIN,其他不做任何修改
两种方式都可以达到index seek的效果。
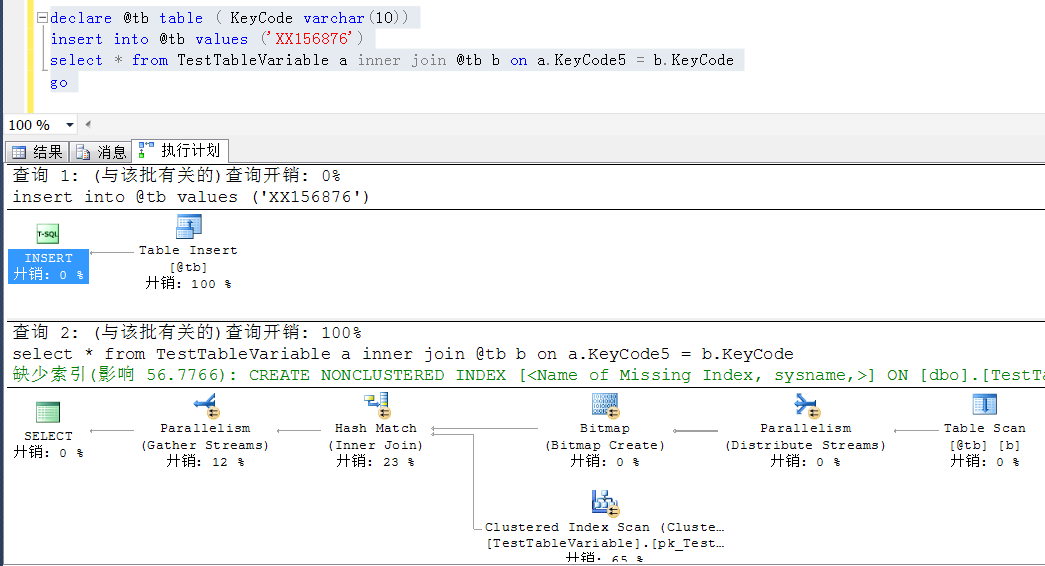
declare @tb table ( KeyCode varchar(10))
insert into @tb values ('XX156876')
select * from TestTableVariable a inner join @tb b on a.KeyCode5 = b.KeyCode
where a.KeyCode5 is not null
go declare @tb table ( KeyCode varchar(10))
insert into @tb values ('XX156876')
select * into #t from @tb
select * from TestTableVariable a inner join #t b on a.KeyCode5 = b.KeyCode
go
以下是两者的执行计划,都是index seek
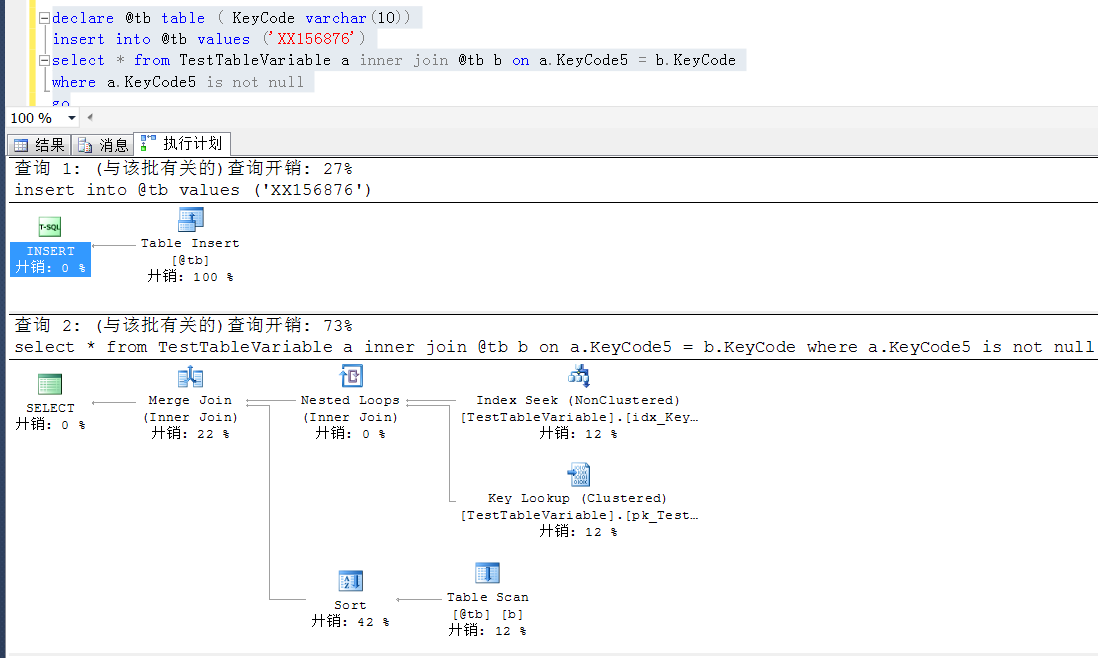
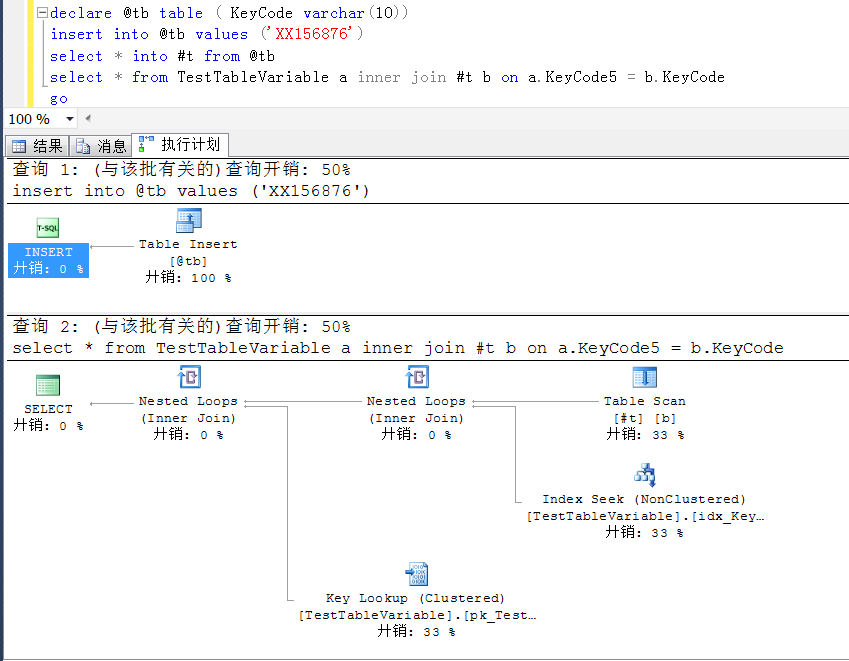
以上是解决办法,暂不过多表述。
存在的疑问
问题就在于:
即便是表变量没有统计信息,sqlserver默认情况下总是会预估为1行(不加任何查询提示),既然预估为1行,在当前情况下也是准确的,不认为是预估出现偏差导致执行计划出现非最优。
对于临时表,同样是1行数据,来驱动物理表TestTableVariable,就可以正常使用到index seek,而表变量不行?
再就是,对于TestTableVariable表上的统计信息,经过几个SQL查询过后,触发了统计信息的更新,统计信息也相对准确地预估到了999999行为null,1行是一个特定的值XX156876)
1,对于物理表TestTableVariable与表变量的join,由于NULL值跟任何值对比都是没有结果的,换句话说就是,不管表变量里的数据量有多少,按照统计信息中的预估,这个查询对于TestTableVariable这个表来说,最多只有1行数据(统计信息中的那个非NULL)的数据参与查询运算
2,对于表变量,既然预估为1行,哪有为什么不使用索引查找的方式,就算是用不到索引查找,join双方,按照预估,都只有一行数据参与运算的情况下,为什么竟然要选择HASH JOIN?
表变量参数join的时候,优化器为什么连这么一个简单的推断逻辑都做不到,并没有非常复杂的逻辑,或者说数据分布异常的情况在里面,最终选择了最差的执行计划进行运算。
反观临时表,用临时表join的情况下,一切都回归到预期的索引查找,可否认为,sqlserver对表变量的join或者说运算,支持的非常不友好(2012~2016均没有改善)。
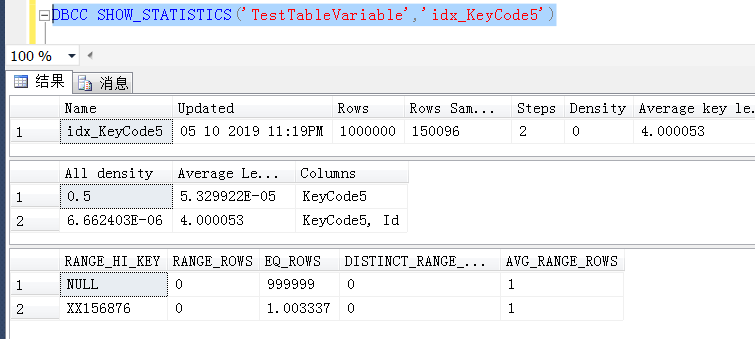
后面怀疑是不是KeyCode5上的统计信息取样百分比不够大,造成的执行计划错误,尝试100%取样
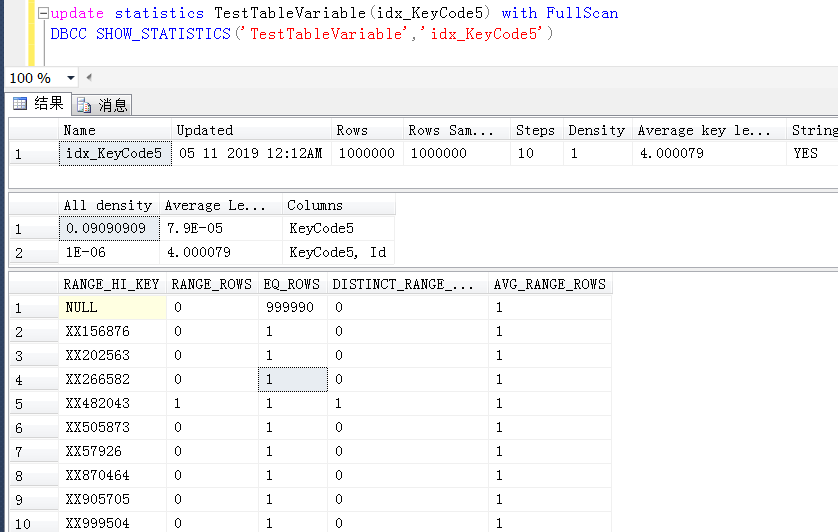
继续测试,问题依旧

当前这个case,并不是那种经典的,因为对表变量预估偏差造成的执行计划错误,暂时也无法理解,sqlserver为什么会对表变量参数参与的join,在当前这种case中,采用如此保守的执行方式。
越来越多的case证明,在sqlserver中使用表变量参与join,就好比是一颗定时炸弹,随时可以引爆你的系统,看来要慎重。
sqlserver的表变量在没有预估偏差的情况下,与物理表可join产生的性能问题的更多相关文章
- Oracle备份恢复之无备份情况下恢复undo表空间
UNDO表空间存储着DML操作数据块的前镜像数据,在数据回滚,一致性读,闪回操作,实例恢复的时候都可能用到UNDO表空间中的数据.如果在生产过程中丢失或破坏了UNDO表空间,可能导致某些事务无法回滚, ...
- Django框架第七篇(模型层)--多表操作:一对多/多对多增删改,跨表查询(基于对象、基于双下划线跨表查询),聚合查询,分组查询,F查询与Q查询
一.多表操作 一对多字段的增删改(book表和publish表是一对多关系,publish_id字段) 增 create publish_id 传数字 (publish_id是数据库显示的字段名 ...
- sqlserver同步后在不重新初始化快照的情况下新增表
在已有事务复制中,时长需要新增表.索引,这些变更时不会同步到从库中.如果采用默认的设置,每次都需要重新初始化快照,从库重新应用快照和未执行的同步命令,这显然是无法在线上实践的方法.另一种 ...
- 错误ORA-01110,在已删除数据文件情况下如何删除表空间
如果先行删除了数据文件,再删除表空间,drop tablespace 会出现如下错误: ORA-01116: error in opening database file 89 ORA-01110: ...
- SQLServer中临时表与表变量的区别分析(转)
在实际使用的时候,我们如何灵活的在存储过程中运用它们,虽然它们实现的功能基本上是一样的,可如何在一个存储过程中有时候去使用临时表而不使用表变量,有时候去使用表变量而不使用临时表呢? 临时表 临时表与永 ...
- SQLServer中临时表与表变量的区别分析
临时表 临时表与永久表相似,只是它的创建是在Tempdb中,它只有在一个数据库连接结束后或者由SQL命令DROP掉,才会消失,否则就会一直存在.临时表在创建的时候都会产生SQL Server的系统日志 ...
- SQLServer中临时表与表变量的区别分析【转】
在实际使用的时候,我们如何灵活的在存储过程中运用它们,虽然它们实现的功能基本上是一样的,可如何在一个存储过程中有时候去使用临时表而不使用表变量,有时候去使用表变量而不使用临时表呢? 临时表 临时表与永 ...
- [转]SQL Server中临时表与表变量的区别
[转]http://blog.csdn.net/skyremember/archive/2009/03/05/3960687.aspx 我们在数据库中使用表的时候,经常会遇到两种使用表的方法,分别就是 ...
- SQL Server中临时表与表变量的区别
我们在数据库中使用表的时候,经常会遇到两种使用表的方法,分别就是使用临时表及表变量.在实际使用的时候,我们如何灵活的在存储过程中运用它们,虽然它们实现的功能基本上是一样的,可如何在一个存储过程中有时候 ...
随机推荐
- cocoapods 安装使用详解
http://blog.csdn.net/showhilllee/article/details/38398119 http://www.jianshu.com/p/1222dd6c4271 删除 ...
- SDCycleScrollView-简单的循环
cocoapods 导入SDCycleScrollView1 记得使用 SDWebImage 2 SDCycleScrollViewDelegate _cycleScrollerView = [SDC ...
- Node.js 中 __dirname 和 ./ 的区别
概要 __dirname 总是指向被执行 js 文件的绝对路径 在 /d1/d2/myscript.js 文件中写了 __dirname, 它的值就是 /d1/d2 . ./ 会返回你执行 node ...
- JSTL学习
基本标签: out标签:<c:out value="${表达式}" default="默认值"></c:out> 作用:结合EL表达式将 ...
- 第4节:Java基础 - 必知必会(中)
第4节:Java基础 - 必知必会(中) 本小节是Java基础篇章的第二小节,主要讲述抽象类与接口的区别,注解以及反射等知识点. 一.抽象类和接口有什么区别 抽象类和接口的主要区别可以总结如下: 抽象 ...
- CoderForces999B- Reversing Encryption
time limit per test 1 second memory limit per test 256 megabytes input standard input output standar ...
- NCPC 2016 Fleecing the Raffle
Description A tremendously exciting raffle is being held, with some tremendously exciting prizes bei ...
- 【JS】376- Axios 使用指南
点击上方"前端自习课"关注,学习起来~ 来源 | https://www.jianshu.com/p/df464b26ae58 一.axios 基于promise用于浏览器和 ...
- 【CuteJavaScript】GraphQL真香入门教程
看完复联四,我整理了这份 GraphQL 入门教程,哈哈真香... 欢迎关注我的 个人主页 && 个人博客 && 个人知识库 && 微信公众号" ...
- Go 修改map slice array元素值
在“range”语句中生成的数据的值其实是集合元素的拷贝.它们不是原有元素的引用.这就意味着更新这些值将不会修改原来的数据.我们来直接看段示例: package main import "f ...