【JDK】JDK源码分析-AbstractQueuedSynchronizer(2)
概述
前文「JDK源码分析-AbstractQueuedSynchronizer(1)」初步分析了 AQS,其中提到了 Node 节点的「独占模式」和「共享模式」,其实 AQS 也主要是围绕对这两种模式的操作进行的。
Node 节点是对线程 Thread 类的封装,因此两种模式可以理解如下:
独占模式(exclusive):线程对资源的访问是排他的,即某个时间只能一个线程单独访问资源;
共享模式(shared):与独占模式不同,多个线程可以同时访问资源。
本文先分析独占模式下的各种操作,后面再分析共享模式。
独占模式
方法概述
独占模式下的操作主要有以下几个方法(可与前面分析的 Lock 接口的方法类比):
1. acquire(int arg)
以独占模式获取资源,忽略中断;可以类比 Lock 接口的 lock 方法;
2. acquireInterruptibly(int arg)
以独占模式获取资源,响应中断;可以类比 Lock 接口的 lockInterruptibly 方法;
3. tryAcquireNanos(int arg, long nanosTimeout)
以独占模式获取资源,响应中断,且有超时等待;可以类比 Lock 接口的 tryLock(long, TimeUnit) 方法;
4. release(int arg)
释放资源,可以类比 Lock 接口的 unlock 方法。
方法分析
1. 独占模式获取资源(忽略中断)
这几种获取资源的方法很多地方是类似的。我们先从 acquire 方法开始分析,如下:
public final void acquire(int arg) {
if (!tryAcquire(arg) &&
acquireQueued(addWaiter(Node.EXCLUSIVE), arg))
selfInterrupt();
}
该方法看似很短,其实是内部做了封装。这几行代码包含了如下四个操作步骤:
1. tryAcquire
2. addWaiter(Node.EXECUSIVE)
3. acquireQueued(final Node node, arg))
4. selfInterrupt
上面的四个步骤不一定全部执行,下面依次进行分析。
step 1: tryAcquire
protected boolean tryAcquire(int arg) {
throw new UnsupportedOperationException();
}
该方法的作用是尝试以独占模式获取资源,若成功则返回 true。
可以看到该方法是一个 protected 方法,而且 AQS 中该方法直接抛出了异常,其实是它把实现委托给了子类。这也是 ReentrantLock、CountdownLatch 等类(严格来说是其内部类 Sync)的实现功能不同的地方,这些类正是通过对该方法的不同实现来制定了自己的“游戏规则”。
若 step 1 中的 tryAcquire 方法返回 true,则表示当前线程获取资源成功,方法直接返回,该线程接下来就可以“为所欲为”了;否则表示获取失败,接下来会依次执行 step 2 和 step 3。
step 2: addWaiter(Node.EXECUSIVE)
private Node addWaiter(Node mode) {
// 将当前线程封装为一个 Node 节点,指定 mode
// PS: 独占模式 Node.EXECUSIVE, 共享模式 Node.SHARED
Node node = new Node(Thread.currentThread(), mode);
// Try the fast path of enq; backup to full enq on failure
Node pred = tail;
if (pred != null) {
node.prev = pred;
// 通过 CAS 操作设置主队列的尾节点
if (compareAndSetTail(pred, node)) {
pred.next = node;
return node;
}
}
// 尾节点 tail 为 null,表示主队列未初始化
enq(node);
return node;
}
enq 方法:
private Node enq(final Node node) {
for (;;) {
Node t = tail;
// 尾节点为空,表明当前队列未初始化
if (t == null) { // Must initialize
// 将队列的头尾节点都设置为一个新的节点
if (compareAndSetHead(new Node()))
tail = head;
} else {
// 将 node 节点插入主队列末尾
node.prev = t;
if (compareAndSetTail(t, node)) {
t.next = node;
return t;
}
}
}
}
可以看到 addWaiter(Node.EXECUSIVE) 方法的作用是:把当前线程封装成一个独占模式的 Node 节点,并插入到主队列末尾(若主队列未初始化,则将其初始化后再插入)。
step 3: acquireQueued(final Node node, arg))
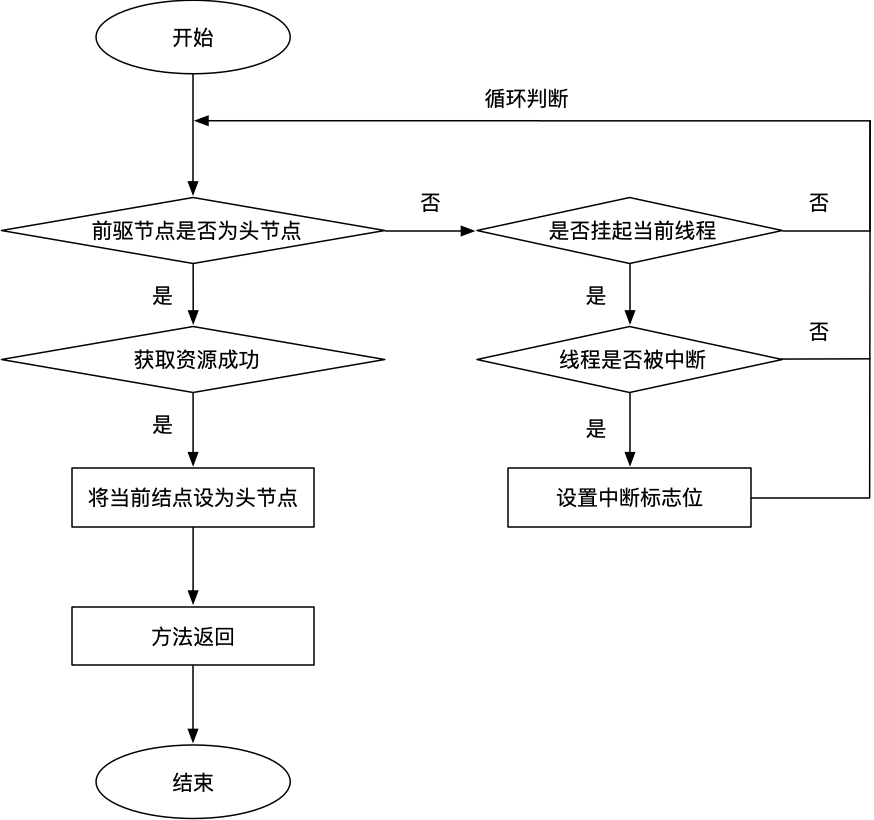
final boolean acquireQueued(final Node node, int arg) {
boolean failed = true;
try {
// 中断标志位
boolean interrupted = false;
for (;;) {
// 获取该节点的前驱节点
final Node p = node.predecessor();
// 若前驱节点为头节点,则尝试获取资源
if (p == head && tryAcquire(arg)) {
// 若获取成功,则将该节点设置为头节点并返回
setHead(node);
p.next = null; // help GC
failed = false;
return interrupted;
}
// 若上面条件不满足,即前驱节点不是头节点,或尝试获取失败
// 判断当前线程是否可以休眠
if (shouldParkAfterFailedAcquire(p, node) &&
parkAndCheckInterrupt())
interrupted = true;
}
} finally {
if (failed)
cancelAcquire(node);
}
}
若当前节点的前驱节点为头节点,则会再次尝试获取资源(tryAcuqire),若获取成功,则将当前节点设置为头节点并返回;否则,若前驱节点不是头节点,或者获取资源失败,则执行如下两个方法:
private static boolean shouldParkAfterFailedAcquire(Node pred, Node node) {
// 前驱节点的等待状态
int ws = pred.waitStatus;
// 若前驱节点的等待状态为 SIGNAL,返回 true,表示当前线程可以休眠
if (ws == Node.SIGNAL)
/*
* This node has already set status asking a release
* to signal it, so it can safely park.
*/
return true;
// 若前驱节点的状态大于 0,表示前驱节点处于取消(CANCELLED)状态
// 则将前驱节点跳过(相当于踢出队列)
if (ws > 0) {
/*
* Predecessor was cancelled. Skip over predecessors and
* indicate retry.
*/
do {
node.prev = pred = pred.prev;
} while (pred.waitStatus > 0);
pred.next = node;
} else {
/*
* waitStatus must be 0 or PROPAGATE. Indicate that we
* need a signal, but don't park yet. Caller will need to
* retry to make sure it cannot acquire before parking.
*/
// 此时 waitStatus 只能为 0 或 PROPAGATE 状态,将前驱节点的等着状态设置为 SIGNAL
compareAndSetWaitStatus(pred, ws, Node.SIGNAL);
}
return false;
}
该方法的流程:
1. 若前驱节点的等待状态为 SIGNAL,返回 true,表示当前线程可以休眠(park);
2. 若前驱节点是取消状态 (ws > 0),则将其清理出队列,以此类推;
3. 若前驱节点为 0 或 PROPAGATE,则将其设置为 SIGNAL 状态。
正如其名,该方法(shouldParkAfterFailedAcquire)的作用就是判断当前线程在获取资源失败后,是否可以休眠(park)。
parkAndCheckInterrupt:
private final boolean parkAndCheckInterrupt() {
// 将当前线程休眠
LockSupport.park(this);
return Thread.interrupted();
}
该方法的作用:
1. 使当前线程休眠(park);
2. 返回该线程是否被中断(其他线程对其发过中断信号)。
上面就是 acquireQueued(final Node node, arg)) 方法的执行过程,为了便于理解,可参考下面的流程图:
若此期间被其他线程中断过,则此时再去执行 selfInterrupt 方法去响应中断请求:
static void selfInterrupt() {
Thread.currentThread().interrupt();
}
以上就是 acquire 方法执行的整体流程。
2. 以独占模式获取资源(响应中断)
该操作其实与前面的过程类似,因此分析相对简单些,代码如下:
public final void acquireInterruptibly(int arg)
throws InterruptedException
// 若线程被中断过,则抛出异常
if (Thread.interrupted())
throw new InterruptedException();
// 尝试获取资源
if (!tryAcquire(arg))
// 尝试获取资源失败
doAcquireInterruptibly(arg);
}
tryAcquire 与前面的操作一样,若尝试获取资源成功则直接返回;否则,执行 doAcquireInterruptibly:
private void doAcquireInterruptibly(int arg)
throws InterruptedException
// 将当前线程封装成 Node 节点插入主队列末尾
final Node node = addWaiter(Node.EXCLUSIVE);
boolean failed = true;
try {
for (;;) {
final Node p = node.predecessor();
if (p == head && tryAcquire(arg)) {
setHead(node);
p.next = null; // help GC
failed = false;
return;
}
if (shouldParkAfterFailedAcquire(p, node) &&
parkAndCheckInterrupt())
// 抛出中断异常
throw new InterruptedException();
}
} finally {
if (failed)
cancelAcquire(node);
}
}
通过与前面的 acquire 方法对比可以发现,二者代码几乎一样,区别在于 acquire 方法检测到中断(parkAndCheckInterrupt)时只是记录了标志位,并未响应;而此处直接抛出了异常。这也是二者仅有的区别,此处不再详细分析。
3. 以独占模式获取资源(响应中断,且有超时)
该操作与前者也是类似的,代码如下:
public final boolean tryAcquireNanos(int arg, long nanosTimeout)
throws InterruptedException
// 若被中断,则响应
if (Thread.interrupted())
throw new InterruptedException();
return tryAcquire(arg) ||
doAcquireNanos(arg, nanosTimeout);
}
doAcquireNanos:
static final long spinForTimeoutThreshold = 1000L; private boolean doAcquireNanos(int arg, long nanosTimeout)
throws InterruptedException {
// 若超时时间小于等于 0,直接获取失败
if (nanosTimeout <= 0L)
return false;
// 计算截止时间
final long deadline = System.nanoTime() + nanosTimeout;
final Node node = addWaiter(Node.EXCLUSIVE);
boolean failed = true;
try {
for (;;) {
final Node p = node.predecessor();
if (p == head && tryAcquire(arg)) {
setHead(node);
p.next = null; // help GC
failed = false;
return true;
}
nanosTimeout = deadline - System.nanoTime();
// 已经超时了,获取失败
if (nanosTimeout <= 0L)
return false;
// 若大于自旋时间,则线程休眠;否则自旋
if (shouldParkAfterFailedAcquire(p, node) &&
nanosTimeout > spinForTimeoutThreshold)
LockSupport.parkNanos(this, nanosTimeout);
// 若被中断,则响应
if (Thread.interrupted())
throw new InterruptedException();
}
} finally {
if (failed)
cancelAcquire(node);
}
}
这里有个变量 spinForTimeoutThreshold,表示自旋时间,若大于该值则将线程休眠,否则继续自旋。个人理解这里增加该时间是为了提高效率,即,只有在等待时间较长的时候才让线程休眠。
该方法与 acquireInterruptibly 也是类似的,在前者的基础上增加了 timeout,不再详细分析。
4. 释放资源
前面分析了三种获取资源的方式,自然也有释放资源。下面分析释放资源的 release 操作:
public final boolean release(int arg) {
// 尝试释放资源,若成功则返回 true
if (tryRelease(arg)) {
Node h = head;
// 若头节点不为空,且等待状态不为 0(此时为 SIGNAL)
// 则唤醒其后继节点
if (h != null && h.waitStatus != 0)
unparkSuccessor(h);
return true;
}
return false;
}
与 tryAcquire 方法类似,tryRelease 方法在 AQS 中也是抛出异常,同样交由子类实现:
protected boolean tryRelease(int arg) {
throw new UnsupportedOperationException();
}
unparkSuccessor 的主要作用是唤醒 node 的后继节点,代码如下:
private void unparkSuccessor(Node node) {
/*
* If status is negative (i.e., possibly needing signal) try
* to clear in anticipation of signalling. It is OK if this
* fails or if status is changed by waiting thread.
*/
int ws = node.waitStatus;
if (ws < 0)
compareAndSetWaitStatus(node, ws, 0);
/*
* Thread to unpark is held in successor, which is normally
* just the next node. But if cancelled or apparently null,
* traverse backwards from tail to find the actual
* non-cancelled successor.
*/
// 后继节点
Node s = node.next;
if (s == null || s.waitStatus > 0) {
// 若后继节点是取消状态,则从尾节点向前遍历,找到 node 节点后面一个未取消状态的节点
s = null;
for (Node t = tail; t != null && t != node; t = t.prev)
if (t.waitStatus <= 0)
s = t;
}
// 唤醒node节点的后继节点
if (s != null)
LockSupport.unpark(s.thread);
}
若 node 节点的后继节点是取消状态(ws > 0),则从主队列中取其后面一个非取消状态的线程唤醒。
前面三个获取资源的方法中,finally 代码块中都用到了 cancelAcquire 方法,都是获取失败时的操作,这里也分析一下:
private void cancelAcquire(Node node) {
// Ignore if node doesn't exist
if (node == null)
return;
node.thread = null;
// Skip cancelled predecessors
// 跳过取消状态的前驱节点
Node pred = node.prev;
while (pred.waitStatus > 0)
node.prev = pred = pred.prev;
// predNext is the apparent node to unsplice. CASes below will
// fail if not, in which case, we lost race vs another cancel
// or signal, so no further action is necessary.
// 前驱节点的后继节点引用
Node predNext = pred.next;
// Can use unconditional write instead of CAS here.
// After this atomic step, other Nodes can skip past us.
// Before, we are free of interference from other threads.
// 将当前节点设置为取消状态
node.waitStatus = Node.CANCELLED;
// If we are the tail, remove ourselves.
// 若该节点为尾节点(后面没其他节点了),将 predNext 指向 null
if (node == tail && compareAndSetTail(node, pred)) {
compareAndSetNext(pred, predNext, null);
} else {
// If successor needs signal, try to set pred's next-link
// so it will get one. Otherwise wake it up to propagate.
int ws;
if (pred != head &&
((ws = pred.waitStatus) == Node.SIGNAL ||
(ws <= 0 && compareAndSetWaitStatus(pred, ws, Node.SIGNAL))) &&
pred.thread != null) {
Node next = node.next;
if (next != null && next.waitStatus <= 0)
compareAndSetNext(pred, predNext, next);
} else {
// 前驱节点为头节点,表明当前节点为第一个,取消时唤醒它的下一个节点
unparkSuccessor(node);
}
node.next = node; // help GC
}
}
该方法的主要操作:
1. 将 node 节点设置为取消(CANCELLED)状态;
2. 找到它在队列中非取消状态的前驱节点 pred:
2.1 若 node 节点是尾节点,则前驱节点的后继设为空,
2.2 若 pred 不是头节点,且状态为 SIGNAL,则后继节点设为 node 的后继节点;
2.3 若 pred 是头节点,则唤醒 node 的后继节点。
PS: 该过程可以跟双链表删除一个节点的过程进行对比分析。
小结
本文分析了以独占模式获取资源的三种方式,以及释放资源的操作。分别为:
1. acquire: 独占模式获取资源,忽略中断;
2. acquireInterruptibly: 独占模式获取资源,响应中断;
tryAcquireNanos: 独占模式获取资源,响应中断,有超时;
4. release: 释放资源,唤醒主队列中的下一个线程。
这几个方法都可以类比 Lock 接口的相关方法定义。
相关阅读:
JDK源码分析-AbstractQueuedSynchronizer(1)
Stay hungry, stay foolish.

PS: 本文首发于微信公众号【WriteOnRead】。
【JDK】JDK源码分析-AbstractQueuedSynchronizer(2)的更多相关文章
- 【JDK】JDK源码分析-AbstractQueuedSynchronizer(3)
概述 前文「JDK源码分析-AbstractQueuedSynchronizer(2)」分析了 AQS 在独占模式下获取资源的流程,本文分析共享模式下的相关操作. 其实二者的操作大部分是类似的,理解了 ...
- JDK Collection 源码分析(2)—— List
JDK List源码分析 List接口定义了有序集合(序列).在Collection的基础上,增加了可以通过下标索引访问,以及线性查找等功能. 整体类结构 1.AbstractList 该类作为L ...
- JDK AtomicInteger 源码分析
@(JDK)[AtomicInteger] JDK AtomicInteger 源码分析 Unsafe 实例化 Unsafe在创建实例的时候,不能仅仅通过new Unsafe()或者Unsafe.ge ...
- 【JDK】JDK源码分析-AbstractQueuedSynchronizer(1)
概述 前文「JDK源码分析-Lock&Condition」简要分析了 Lock 接口,它在 JDK 中的实现类主要是 ReentrantLock (可译为“重入锁”).ReentrantLoc ...
- 设计模式(十八)——观察者模式(JDK Observable源码分析)
1 天气预报项目需求,具体要求如下: 1) 气象站可以将每天测量到的温度,湿度,气压等等以公告的形式发布出去(比如发布到自己的网站或第三方). 2) 需要设计开放型 API,便于其他第三方也能接入气象 ...
- AQS框架源码分析-AbstractQueuedSynchronizer
前言:AQS框架在J.U.C中的地位不言而喻,可以说没有AQS就没有J.U.C包,可见其重要性,因此有必要对其原理进行详细深入的理解. 1.AQS是什么 在深入AQS之前,首先我们要搞清楚什么是AQS ...
- JDK Collection 源码分析(3)—— Queue
@(JDK)[Queue] JDK Queue Queue:队列接口,对于数据的存取,提供了两种方式,一种失败会抛出异常,另一种则返回null或者false. 抛出异常的接口:add,remove ...
- JDK Collection 源码分析(1)—— Collection
JDK Collection JDK Collection作为一个最顶层的接口(root interface),JDK并不提供该接口的直接实现,而是通过更加具体的子接口(sub interface ...
- 【JDK】JDK源码分析-ReentrantLock
概述 在 JDK 1.5 以前,锁的实现只能用 synchronized 关键字:1.5 开始提供了 ReentrantLock,它是 API 层面的锁.先看下 ReentrantLock 的类签名以 ...
随机推荐
- Jquery实现搜索功能
<script> //搜索功能 (function ($) { jQuery.expr[':'].Contains = function (a, i, m) { return (a.tex ...
- k8s对象类资源格式
k8s api仅接受及响应json格式的数据,同时,为了便于使用,它也允许用户提供yaml格式的post对象,但apiserver需要事先自行将其转换为json格式后方能提交.每个资源通常仅接受并返回 ...
- ES5_04_Array扩展
介绍什么是Array对象? # Array 对象用于在单个的变量中存储多个值 1. 创建 Array 对象的语法: 2. Array 对象属性 3. Array 对象方法 补充: 1. Array.p ...
- Python之Pandas库学习(三):数据处理
1. 合并 可以将其理解为SQL中的JOIN操作,使用一个或多个键把多行数据结合在一起. 1.1. 简单合并 参数on表示合并依据的列,参数how表示用什么方式操作(默认是内连接). >> ...
- Ural 2062:Ambitious Experiment(树状数组 || 分块)
http://acm.timus.ru/problem.aspx?space=1&num=2062 题意:有n个数,有一个值,q个询问,有单点询问操作,也有对于区间[l,r]的每个数i,使得n ...
- Codeforces 760C:Pavel and barbecue(DFS+思维)
http://codeforces.com/problemset/problem/760/C 题意:有n个盘子,每个盘子有一块肉,当肉路过这个盘子的时候,当前朝下的这一面会被煎熟,每个盘子有两个数,p ...
- golang 单元测试&&性能测试
一:单元测试 1.为什么要做单元测试和性能测试 减少bug 快速定位bug 减少调试时间 提高代码质量 2.golang的单元测试 单元测试代码的go文件必须以_test.go结尾 单元测试的函数名必 ...
- SFC20 功能例子 注解
谁能够把这注解一下,给大家分享一下,谢谢了 LAR1 P##SOURCE L B#16#10 T LB [AR1,P#0.0] L B#1 ...
- C语言学习书籍推荐《数据结构与算法分析:C语言描述(原书第2版)》下载
维斯 (作者), 冯舜玺 (译者) <数据结构与算法分析:C语言描述(原书第2版)>内容简介:书中详细介绍了当前流行的论题和新的变化,讨论了算法设计技巧,并在研究算法的性能.效率以及对运行 ...
- docker-compose exec时 出现"fork/exec /proc/self/exe: no such file or directory" 报错
问题:跟往常一样执行docker-compos exec redis sh时出现如下错误,而容器是运行状态中. # docker-compose exec redis sh rpc error: co ...