Kafka源码分析及图解原理之Broker端
一.前言
https://www.cnblogs.com/GrimMjx/p/11354987.html
上一节说过,任何消息队列都是万变不离其宗都是3部分,消息生产者(Producer)、消息消费者(Consumer)和服务载体(在Kafka中用Broker指代)。上一节讲了kafka producer端的一些细节,那么这一节来讲broker端的一些设计与原理
首先从kafka如何创建一个topic来开始:
kafka-topics --create --zookeeper localhost: --replication-factor --partitions --topic test
其中有这么几个参数:
- --zookeeper:zookeeper的地址
- --replication-factor:副本因子
- --partitions:分区个数(默认是1)
- --topic:topic名称
二.什么是分区
一个topic可以有多个分区,每个分区的消息都是不同的。虽然分区可以提供更高的吞吐量,但是分区不是越多越好。一般分区数不要超过kafka集群的机器数量。分区越多占用的内存和文件句柄。一般分区设置为3-10个。比如现在集群有3个机器,要创建一个名为test的topic,分区数为2,那么如图:
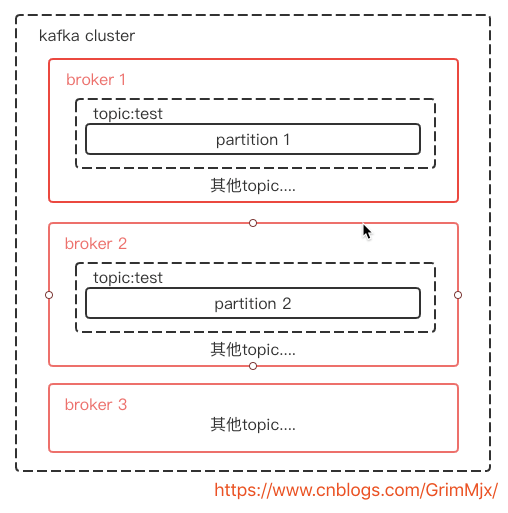
partiton都是有序切顺序不可变的记录集,并且不断追加到log文件,partition中的每一个消息都回分配一个id,也就是offset(偏移量),offset用来标记分区的一条记录,这里就用官网的图了,我画的不好:

2.1 producer端和分区关系
就图上的情况,producer端会把mq给哪个分区呢?这也是上一节我们提到的一个参数partitioner.class。默认分区器的处理是:有key则用murmur2算法计算key的哈希值,对总分区取模算出分区号,无key则轮询。(org.apache.kafka.clients.producer.internals.DefaultPartitioner#partition)。当然了我们也可以自定义分区策略,只要实现org.apache.kafka.clients.producer.Partitioner接口即可:
/**
* Compute the partition for the given record.
*
* @param topic The topic name
* @param key The key to partition on (or null if no key)
* @param keyBytes serialized key to partition on (or null if no key)
* @param value The value to partition on or null
* @param valueBytes serialized value to partition on or null
* @param cluster The current cluster metadata
*/
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {
List<PartitionInfo> partitions = cluster.partitionsForTopic(topic);
int numPartitions = partitions.size();
if (keyBytes == null) {
int nextValue = nextValue(topic);
List<PartitionInfo> availablePartitions = cluster.availablePartitionsForTopic(topic);
if (availablePartitions.size() > 0) {
int part = Utils.toPositive(nextValue) % availablePartitions.size();
return availablePartitions.get(part).partition();
} else {
// no partitions are available, give a non-available partition
return Utils.toPositive(nextValue) % numPartitions;
}
} else {
// hash the keyBytes to choose a partition
return Utils.toPositive(Utils.murmur2(keyBytes)) % numPartitions;
}
}
2.2 consumer端和分区关系
先来看下官网对于消费组的定义:Consumers label themselves with a consumer group name, and each record published to a topic is delivered to one consumer instance within each subscribing consumer group.
翻译:消费者使用一个消费者组名来标记自己,一个topic的消息会被发送到订阅它的消费者组的一个消费者实例上。
consumer group是用于实现高伸缩性,高容错性的consumer机制。如果有consumer挂了或者新增一个consumer,consumer group会进行重平衡(rebalance),重平衡机制会在consumer篇具体讲解,本节不讲。那么按照上面的图继续画消费者端:
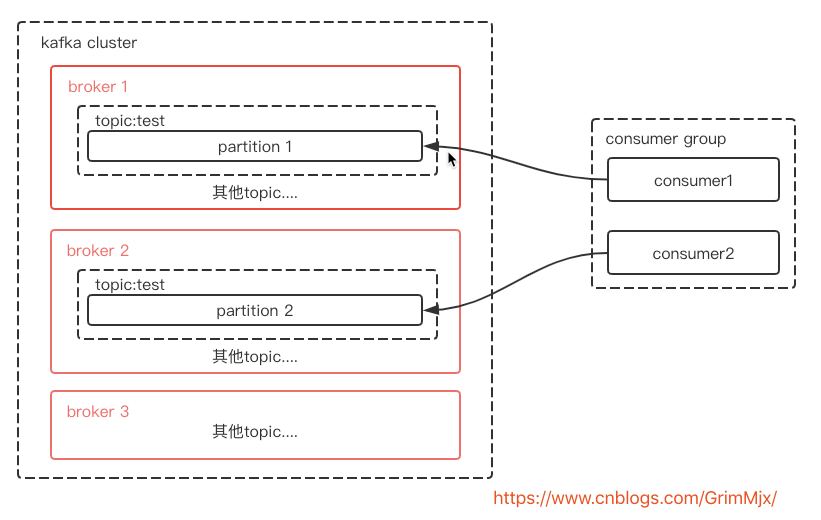
这里是最好的情况,2个partition对应1个group中的2个consumer。那么思考,如果一个消费组的消费者大于分区数呢?或者小于分区数呢?
如果一个消费组的消费者大于分区数,那么相当于多余的消费者是一种浪费,多余的消费者将无法消费消息。
如果一个消费组的消费者小于分区数,会有对应的消费者分区分配策略。一种是Range(默认),一种是RoundRobin(轮询),当然也可以自定义策略。其实思想换汤不换药的啊,每个消费者能负载均衡的工作。具体会在消费者篇讲解,这里不讲。
建议:配置分区数是消费者数的整数倍
三.副本与ISR设计
3.1 什么是副本
在创建topic的时候有个参数是--replication-factor来设定副本数。Kafka利用多份相同的备份保持系统的高可用性,这些备份在Kafka中被称为副本(replica)。副本分为3类:
- leader副本:响应producer端的读写请求
- follower副本:备份leader副本的数据,不响应producer端的读写请求!
- ISR副本集合:包含1个leader副本和所有follower副本(也可能没有follower副本)
Kafka会把所有的副本均匀分配到kafka-cluster中的所有broker上,并从这些副本中挑选一个作为leader副本,其他成为follow副本。如果leader副本所在的broker宕机了,那么其中的一个follow副本就会成为leader副本。leader副本接收producer端的读写请求,而follow副本只是向leader副本请求数据不会接收读写请求!

3.2 副本同步机制
上面说了ISR就是动态维护一组同步副本集合,leader副本总是包含在ISR集合中。只有ISR中的副本才有资格被选举为leader副本。当producer端的ack参数配置为all(-1)时,producer写入的mq需要ISR所有副本都接收到,才被视为已提交。当然了,上一节就提到了,使用ack参数必须配合broker端的min.insync.replicas(默认是1)参数一起用才能达到效果,该参数控制写入isr中的多少副本才算成功。如果ISR中的副本数少于min.insync.replicas时,客户端会返回异常org.apache.kafka.common.errors.NotEnoughReplicasExceptoin: Messages are rejected since there are fewer in-sync replicas than required。
要了解副本同步机制需要先学习几个术语:
- High Watermark:副本高水位值,简称HW,小于HW或者说在HW以下的消息都被认为是“已备份的”,HW指向的也是下一条消息!leader副本的HW值决定consumer能poll的消息数量!consumer只能消费小于HW值的消息!
- LEO:log end offset,下一条消息的位移。也就是说LEO指向的位置是没有消息的!
- remote LEO:严格来说这是一个集合。leader副本所在broker的内存中维护了一个Partition对象来保存对应的分区信息,这个Partition中维护了一个Replica列表,保存了该分区所有的副本对象。除了leader Replica副本之外,该列表中其他Replica对象的LEO就被称为remote LEO
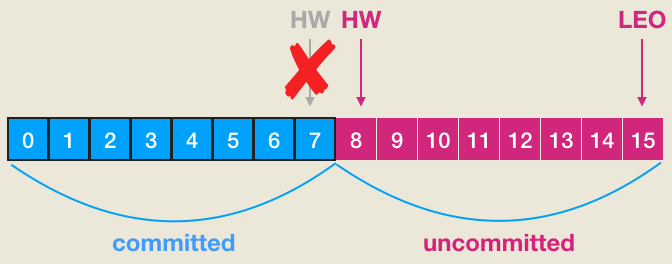
下面举个一个实际的例子(本例子参考胡夕博客),该例子中的topic是单分区,副本因子是2。也就是说一个leader副本,一个follower副本,ISR中包含这2个副本集合。我们首先看下当producer发送一条消息时,leader/follower端broker的副本对象到底会发生什么事情以及分区HW是如何被更新的。首先是初始状态:

此时producer给该topic分区发送了一条消息。此时的状态如下图所示:
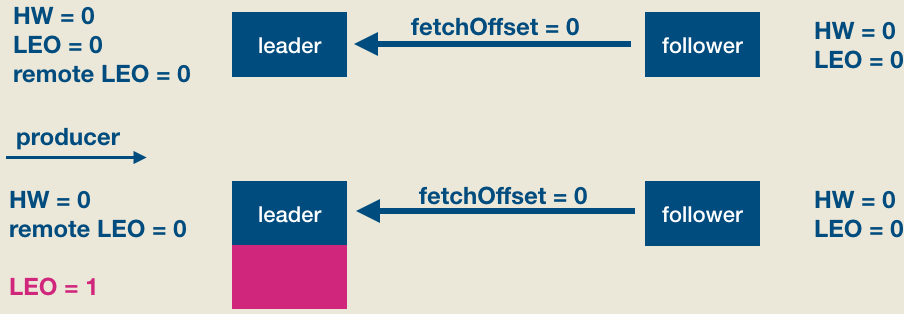
如上图所见,producer发送消息成功后(假设acks=1, leader成功写入即返回),follower发来了新的FECTH请求,依然请求fetchOffset = 0的数据。和上次不同的是,这次是有数据可以读取的,因此整个处理流程如下图:
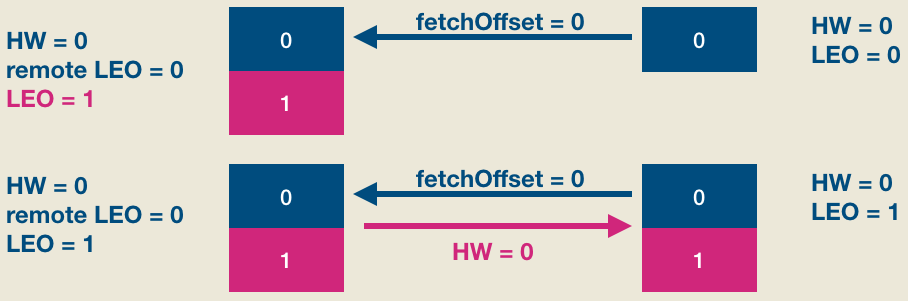
显然,现在leader和follower都保存了位移是0的这条消息,但两边的HW值都没有被更新,它们需要在下一轮FETCH请求处理中被更新,如下图所示:
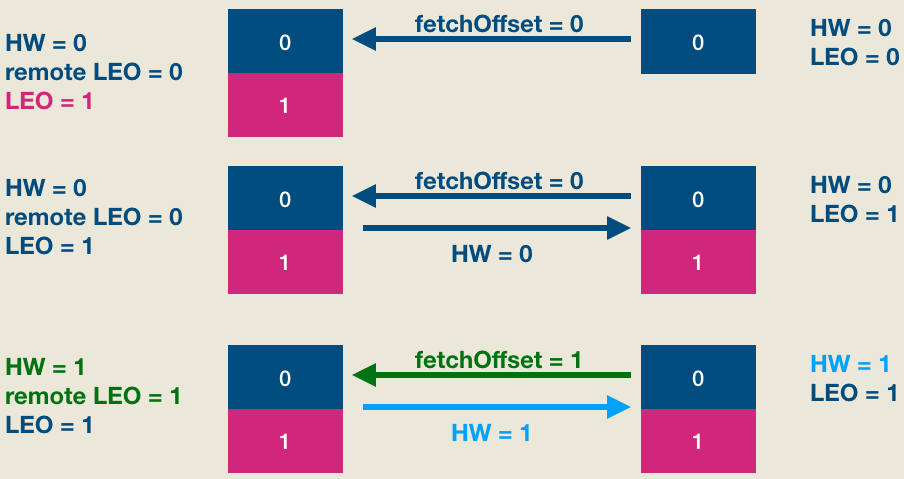
简单解释一下, 第二轮FETCH请求中,follower发送fetchOffset = 1的FETCH请求——因为fetchOffset = 0的消息已经成功写入follower本地日志了,所以这次请求fetchOffset = 1的数据了。Leader端broker接收到FETCH请求后首先会更新other replicas中的LEO值,即将remote LEO更新成1,然后更新分区HW值为1——具体的更新规则参见上面的解释。做完这些之后将当前分区HW值(1)封装进FETCH response发送给follower。Follower端broker接收到FETCH response之后从中提取出当前分区HW值1,然后与自己的LEO值比较,从而将自己的HW值更新成1,至此完整的HW、LEO更新周期结束。
3.3 ISR维护
在0.9.0.0版本之后,只有一个参数:replica.lag.time.max.ms来判定该副本是否应该在ISR集合中,这个参数默认值为10s。意思是如果一个follower副本响应leader副本的时间超过10s,kafka会认为这个副本走远了从同步副本列表移除。
四.日志设计
Kafka的每个主题相互隔离,每个主题可以有一个或者多个分区,每个分区都有记录消息数据的日志文件:

图中有个demo-topic的主题,这个topic有8个分区,每一个分区都存在[topic-partition]命名的消息日志文件。在分区日志文件中,可以看到前缀一样,但是文件类型不一样的几个文件。比如图中的3个文件,(00000000000000000000.index、00000000000000000000.timestamp、00000000000000000000.log)。这称之为一个LogSegment(日志分段)。
4.1 LogSegment
以一个测试环境的具体例子来讲,一个名为ALC.ASSET.EQUITY.SUBJECT.CHANGE的topic,我们看partition0的日志文件:

每一个LogSegment都包含一些文件名一致的文件集合。文件名的固定是20位数字,如果文件名是00000000000000000000代表当前LogSegment的第一条消息的offset(偏移量)为0,如果文件名是00000000000000000097代表当前LogSegment的第一条消息的offset(偏移量)为97。日志文件有多种后缀的文件,重点关注.index、.timestamp、.log三种类型文件即可。
- .index:偏移量索引文件
- .timeindex:时间索引文件
- .log:日志文件
- .snapshot:快照文件
- .swap:Log Compaction之后的临时文件
4.2 索引与日志文件
kafka有2种索引文件,第一种是offset(偏移量)索引文件,也就是.index结尾的文件。第二种是时间戳索引文件,也就是.timeindex结尾的文件。
我们可以用kafka-run-class.sh来查看offset(偏移量)索引文件的内容:

可以看到每一行都是offset:xxx position:xxxx。这两者没有直接关系。
- offset:相对偏移量
- position:物理地址
那么第一行的offset:12 position:4423是什么意思呢?它代表偏移量从0-12的消息的物理地址在0-4423。
同理第二行的offset:24 position:8773的意思也能猜得出来:它代表偏移量从13-24的消息的物理地址在4424-8773。
我们可以再用kafka-run-class.sh来看下.log文件的文件内容,关注里面的baseOffset和postion的值。你看看和上面说的对应的上吗。

4.3 如何用offset查找
按上面的例子,如何查询偏移量为60的消息
- 根据offset首先找到对应的LogSegment,这里找到00000000000000000000.index
- 通过二分法找到不大于offset的最大索引项,这里找到offset:24 position:8773
- 打开00000000000000000000.log文件,从position为8773的那个地方开始顺序扫描直到找到offset=60的消息

参考文档:
http://kafka.apachecn.org/documentation.html#introduction
https://www.cnblogs.com/huxi2b/p/9579681.html
《Apache Kafka实战》
Kafka源码分析及图解原理之Broker端的更多相关文章
- Kafka源码分析及图解原理之Producer端
一.前言 任何消息队列都是万变不离其宗都是3部分,消息生产者(Producer).消息消费者(Consumer)和服务载体(在Kafka中用Broker指代).那么本篇主要讲解Producer端,会有 ...
- Kafka源码分析系列-目录(收藏不迷路)
持续更新中,敬请关注! 目录 <Kafka源码分析>系列文章计划按"数据传递"的顺序写作,即:先分析生产者,其次分析Server端的数据处理,然后分析消费者,最后再补充 ...
- Kafka源码分析(三) - Server端 - 消息存储
系列文章目录 https://zhuanlan.zhihu.com/p/367683572 目录 系列文章目录 一. 业务模型 1.1 概念梳理 1.2 文件分析 1.2.1 数据目录 1.2.2 . ...
- Guava 源码分析(Cache 原理 对象引用、事件回调)
前言 在上文「Guava 源码分析(Cache 原理)」中分析了 Guava Cache 的相关原理. 文末提到了回收机制.移除时间通知等内容,许多朋友也挺感兴趣,这次就这两个内容再来分析分析. 在开 ...
- 深入源码分析SpringMVC底层原理(二)
原文链接:深入源码分析SpringMVC底层原理(二) 文章目录 深入分析SpringMVC请求处理过程 1. DispatcherServlet处理请求 1.1 寻找Handler 1.2 没有找到 ...
- 【转】MaBatis学习---源码分析MyBatis缓存原理
[原文]https://www.toutiao.com/i6594029178964673027/ 源码分析MyBatis缓存原理 1.简介 在 Web 应用中,缓存是必不可少的组件.通常我们都会用 ...
- Apache Kafka源码分析 – Broker Server
1. Kafka.scala 在Kafka的main入口中startup KafkaServerStartable, 而KafkaServerStartable这是对KafkaServer的封装 1: ...
- php中foreach源码分析(编译原理)
php中foreach源码分析(编译原理) 一.总结 编译原理(lex and yacc)的知识 二.php中foreach源码分析 foreach是PHP中很常用的一个用作数组循环的控制语句.因为它 ...
- Kafka源码分析(一) - 概述
系列文章目录 https://zhuanlan.zhihu.com/p/367683572 目录 系列文章目录 一. 实际问题 二. 什么是Kafka, 如何解决这些问题的 三. 基本原理 1. 基本 ...
随机推荐
- 利用DoHome APP和音箱控制继电器通断电实验参考步骤
准备材料: Arduino Uno 一块 Arduino 扩展板 购买链接 DT-06模块一个 购买链接 安卓手机一个 小度音箱一个 继电器模块一个 杜邦线若干 1.DT-0 ...
- MySQL-EXPLAIN执行计划Extra解释
EXPLAIN命令输出的列中Extra字段可选值较多,这里单独说一下. 该Extra列 EXPLAIN输出包含MySQL解决查询的额外信息.以下列表说明了此列中可能出现的值.每个项目还指示JSON格式 ...
- memcached中hash表相关操作
以下转自http://blog.csdn.net/luotuo44/article/details/42773231 memcached源码中assoc.c文件里面的代码是构造一个哈希表.memc ...
- UI 组件 | Button
最近在与其他自学 Cocos Creator 的小伙伴们交流过程中,发现许多小伙伴对基础组件的应用并不是特别了解,自己在编写游戏的过程中也经常对某个属性或者方法的用法所困扰,而网上也没有比较清晰的用法 ...
- 数据仓库系列之ETL过程和ETL工具
上周因为在处理很多数据源集成的事情一直没有更新系列文章,在这周后开始规律更新.在维度建模中我们已经了解数据仓库中的维度建模方法以及基本要素,在这篇文章中我们将学习了解数据仓库的ETL过程以及实用的ET ...
- CF553C Love Triangles(二分图)
Tyher推的好题. 题意就是给你一些好边一些坏边,其他边随意,让你求符合好坏坏~,或者只包含好好好的三元环的无向图个数. 坏坏的Tyher的题意是这样的. 再翻译得更加透彻一点就是:给你一些0(好边 ...
- 【数据结构】8.java源码关于HashMap
1.hashmap的底层数据结构 众所皆知map的底层结构是类似邻接表的结构,但是进入1.8之后,链表模式再一定情况下又会转换为红黑树在JDK8中,当链表长度达到8,并且hash桶容量超过64(MIN ...
- Groovy语法基础
Groovy 简介 Groovy 是一种基于 JVM 的动态语言,他的语法和 Java 相似,最终也是要编译 .class 在JVM上运行. Groovy 完全兼容 Java 并且在此基础上添加了很多 ...
- Spring源码剖析开篇:什么是Spring?
在讲源码之前,先让我们回顾一下一下Spring的基本概念,当然,在看源码之前你需要使用过spring或者spirngmvc. Spring是什么 Spring是一个开源的轻量级Java SE(Java ...
- maven项目编译通过,测试用例卡住,断点也用不了
maven项目编译通过,测试用例卡住,断点也用不了.如下图 maven的tomcat插件可以运行没报错,但是网页访问一直转圈 原因: 最后发现是typeAliasesPackage这里设置了别名,所以 ...