python 抓取youtube教程
前言:
相信大家很多人都看过youtube网站上的视频,网站上有很多的优质视频,清晰度也非常的高,看到喜欢的想要下载到本地,虽然也有很多方法,但是肯定没有python 来的快,
废话不多说,上代码:
先安装:
pip install pafy
pip install youtube-dl
pip install pytube
先来研究下pafy模块,百度了下没有这个模块的信息,到python官网https://pypi.org/project/pafy/ 查了下,我们来看看这个模块都有些什么功能
import pafy
url = "https://www.youtube.com/watch?v=bMt47wvK6u0"
video = pafy.new(url)
print(video)
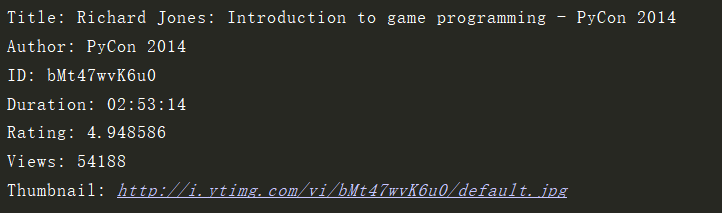
这是周杰伦的一条视频链接,我们看看会输出什么 https://www.youtube.com/watch?v=zk4Olw9eRVo
print(video.title)
#袁詠琳 Cindy Yen【我相信你了 I Believe】Official Lyric MV - 電視劇「用九柑仔店」插曲
print(video.author)
#杰威爾音樂 JVR Music
print(video.viewcount)
#
print(video.length)
#
print(video.duration)
#00:04:55
print(video.likes)
#
print(video.dislikes)
#
print(video.description)
# 简介......
还可以查看可以下载视频的分别率列表
for s in streams:
print(s)
normal:webm@640x360
normal:mp4@640x360
normal:mp4@1280x720
当然了,详细的我们再的查看
for s in streams:
print(s.resolution, s.extension, s.get_filesize(), s.url)

是不是分辨率、格式、大小、下载链接就都有了,这些还不算什么,我们接着看
import pafy
url = "https://www.youtube.com/watch?v=bMt47wvK6u0"
video = pafy.new(url)
best = video.getbest()
print(best.resolution, best.extension) 1280x720 mp4
getbest()方法呢 输出的就是这条视频最清晰的那一条信息
getbest(preftype="webm")这样用也可以输出指定格式的视频,接着看
import pafy
url = "https://www.youtube.com/watch?v=bMt47wvK6u0"
video = pafy.new(url)
best = video.getbest(preftype="webm")
print(best.url) # 打印出指定格式的视频链接
我们接着来看视频的下载方法,这个模块已经为我们封装好了,直接调用此方法即可
import pafy
url = "https://www.youtube.com/watch?v=bMt47wvK6u0"
video = pafy.new(url)
best = video.getbest()
best.download(quiet=False)
best.download(filepath="/tmp/",quiet=False)
可以指定下载路径,和是否显示进度条 下面我们来看音频的下载方法:
import pafy
url = "https://www.youtube.com/watch?v=bMt47wvK6u0"
video = pafy.new(url)
audiostreams = video.audiostreams
for a in audiostreams:
print(a.bitrate, a.extension, a.get_filesize())
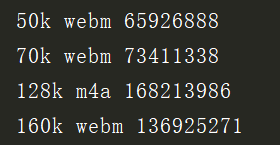
audiostreams[1].download() #下载第一条音频信息
bestaudio = video.getbestaudio() # 同样是输出最优质的那一条
print(bestaudio.bitrate) 160k
bestaudio.download() # 直接下载就可以
接着看:
allstreams = video.allstreams
for s in allstreams:
print(s.mediatype, s.extension, s.quality)
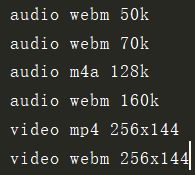
这个方法,可以输出这条视频的所有数据信息
在最后的,上完整的代码:
from pytube import Playlist
import pafy
from multiprocessing import Pool
import os class YoutubeVideoDownload():
def __init__(self,video_path,list_url):
self.video_path = video_path
self.list_url = list_url def get_video_list(self):
"""解析视频列表方法"""
pl = Playlist(self.list_url)
url_lists = pl.parse_links()
data = ["https://www.youtube.com" + i for i in url_lists]
return data def get_video_info(self,detail_url):
"""下载视频"""
print(detail_url)
video = pafy.new(detail_url)
v_best = video.getbest()
v_best.download(self.video_path) if __name__ == '__main__':
p = Pool(4)
video_path = "videos/Pete The Cat Books"
list_url = "https://www.youtube.com/watch?v=K-W3vxS8Y2o&list=PLPPUs6fCDKUdzfQWCkCRl1jDdvfZbn_AF"
yotubo = YoutubeVideoDownload(video_path,list_url)
res = p.map(yotubo.get_video_info, yotubo.get_video_list())
注:解析列表直接这样就可以,但是如果下载单条的话直接调第二个方法即可
python 抓取youtube教程的更多相关文章
- Python 抓取网页并提取信息(程序详解)
最近因项目需要用到python处理网页,因此学习相关知识.下面程序使用python抓取网页并提取信息,具体内容如下: #---------------------------------------- ...
- 使用 Python 抓取欧洲足球联赛数据
Web Scraping在大数据时代,一切都要用数据来说话,大数据处理的过程一般需要经过以下的几个步骤 数据的采集和获取 数据的清洗,抽取,变形和装载 数据的分析,探索和预测 ...
- python抓取性感尤物美女图
由于是只用标准库,装了python3运行本代码就能下载到多多的美女图... 写出代码前面部分的时候,我意识到自己的函数设计错了,强忍继续把代码写完. 测试发现速度一般,200K左右的下载速度,也没有很 ...
- python抓取网页例子
python抓取网页例子 最近在学习python,刚刚完成了一个网页抓取的例子,通过python抓取全世界所有的学校以及学院的数据,并存为xml文件.数据源是人人网. 因为刚学习python,写的代码 ...
- Python抓取页面中超链接(URL)的三中方法比较(HTMLParser、pyquery、正则表达式) <转>
Python抓取页面中超链接(URL)的3中方法比较(HTMLParser.pyquery.正则表达式) HTMLParser版: #!/usr/bin/python # -*- coding: UT ...
- 如何用python抓取js生成的数据 - SegmentFault
如何用python抓取js生成的数据 - SegmentFault 如何用python抓取js生成的数据 1赞 踩 收藏 想写一个爬虫,但是需要抓去的的数据是js生成的,在源代码里看不到,要怎么才能抓 ...
- 关于python抓取google搜索结果的若干问题
关于python抓取google搜索结果的若干问题 前一段时间一直在研究如何用python抓取搜索引擎结果,在实现的过程中遇到了很多的问题,我把我遇到的问题都记录下来,希望以后遇到同样问题的童 ...
- 用python抓取智联招聘信息并存入excel
用python抓取智联招聘信息并存入excel tags:python 智联招聘导出excel 引言:前一阵子是人们俗称的金三银四,跳槽的小朋友很多,我觉得每个人都应该给自己做一下规划,根据自己的进步 ...
- python抓取月光博客的全部文章而且依照标题分词存入mongodb中
猛击这里:python抓取月光博客的全部文章
随机推荐
- Cocos2d-x 学习笔记(11.4) ScaleTo ScaleBy
1. ScaleTo ScaleBy 对node进行缩放.ScaleBy是ScaleTo的子类. 1.1 成员变量 create方法 ScaleTo ScaleBy 成员变量一样: float _sc ...
- opencv实践::对象计数
问题描述 真实案例,农业领域经常需要计算对象个数 或者在其它领域拍照自动计数,可以提供效率,减低成本 解决思路 通过二值分割+形态学处理+距离变换+连通区域计算 #include <opencv ...
- phpstorm安装步骤是什么?
phpstorm的安装及其激活教程 1.phpstorm安装步骤: (1)下载地址:http://www.jetbrains.com/phpstorm/ 根据自己电脑的32or64位下载,下载完后就是 ...
- C# Halcon联合编程问题(二)
避免重复编辑同一篇随笔,有问题就开一个新的,哪怕会很短. 还是之前那个问题,halcon中的HObject转换为Bitmap的问题,在全网找相关的办法,三通道图像的HObject转换为C#中的Bitm ...
- 自定义的Spring Boot starter如何设置自动配置注解
本文首发于个人网站: 在Spring Boot实战之定制自己的starter一文最后提到,触发Spring Boot的配置过程有两种方法: spring.factories:由Spring Boot触 ...
- Java 中的 final、finally、finalize 有什么不同?
Java 中 final.finally.finalize 有什么不同?这是在 Java 面试中经常问到的问题,他们究竟有什么不同呢? 这三个看起来很相似,其实他们的关系就像卡巴斯基和巴基斯坦一样有基 ...
- ggstatsplot绘图|统计+可视化,学术科研神器
本文首发于“生信补给站”公众号,https://mp.weixin.qq.com/s/zdSit97SOEpbnR18ARzixw 更多关于R语言,ggplot2绘图,生信分析的内容,敬请关注小号. ...
- 个人记账app(一)需求设计
时间如流水,只能流去不流回. 学历代表你的过去,能力代表你的现在,学习能力代表你的将来. 学无止境,精益求精. 一.开发背景 Android应用市场记账的app那么多,我为什么还要再开发一个呢?重复造 ...
- 小白学 Python(10):基础数据结构(列表)(下)
人生苦短,我选Python 前文传送门 小白学 Python(1):开篇 小白学 Python(2):基础数据类型(上) 小白学 Python(3):基础数据类型(下) 小白学 Python(4):变 ...
- Connection activation failed Device not managed by NetworkManager
1)查看NetworkManager服务是否启动 ps aux |grep NetworkManager 使用service NetworkManager start 命令启动该网络管理程序 2) 一 ...