HBase 系列(二)—— HBase 系统架构及数据结构
一、基本概念
一个典型的 Hbase Table 表如下:
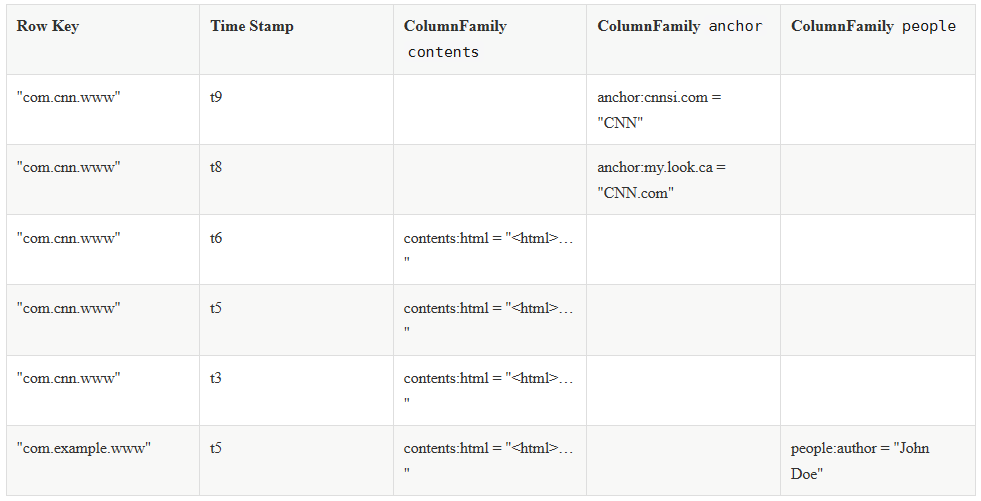
1.1 Row Key (行键)
Row Key 是用来检索记录的主键。想要访问 HBase Table 中的数据,只有以下三种方式:
通过指定的
Row Key进行访问;通过 Row Key 的 range 进行访问,即访问指定范围内的行;
进行全表扫描。
Row Key 可以是任意字符串,存储时数据按照 Row Key 的字典序进行排序。这里需要注意以下两点:
因为字典序对 Int 排序的结果是 1,10,100,11,12,13,14,15,16,17,18,19,2,20,21,…,9,91,92,93,94,95,96,97,98,99。如果你使用整型的字符串作为行键,那么为了保持整型的自然序,行键必须用 0 作左填充。
行的一次读写操作时原子性的 (不论一次读写多少列)。
1.2 Column Family(列族)
HBase 表中的每个列,都归属于某个列族。列族是表的 Schema 的一部分,所以列族需要在创建表时进行定义。列族的所有列都以列族名作为前缀,例如 courses:history,courses:math 都属于 courses 这个列族。
1.3 Column Qualifier (列限定符)
列限定符,你可以理解为是具体的列名,例如 courses:history,courses:math 都属于 courses 这个列族,它们的列限定符分别是 history 和 math。需要注意的是列限定符不是表 Schema 的一部分,你可以在插入数据的过程中动态创建列。
1.4 Column(列)
HBase 中的列由列族和列限定符组成,它们由 :(冒号) 进行分隔,即一个完整的列名应该表述为 列族名 :列限定符。
1.5 Cell
Cell 是行,列族和列限定符的组合,并包含值和时间戳。你可以等价理解为关系型数据库中由指定行和指定列确定的一个单元格,但不同的是 HBase 中的一个单元格是由多个版本的数据组成的,每个版本的数据用时间戳进行区分。
1.6 Timestamp(时间戳)
HBase 中通过 row key 和 column 确定的为一个存储单元称为 Cell。每个 Cell 都保存着同一份数据的多个版本。版本通过时间戳来索引,时间戳的类型是 64 位整型,时间戳可以由 HBase 在数据写入时自动赋值,也可以由客户显式指定。每个 Cell 中,不同版本的数据按照时间戳倒序排列,即最新的数据排在最前面。
二、存储结构
2.1 Regions
HBase Table 中的所有行按照 Row Key 的字典序排列。HBase Tables 通过行键的范围 (row key range) 被水平切分成多个 Region, 一个 Region 包含了在 start key 和 end key 之间的所有行。
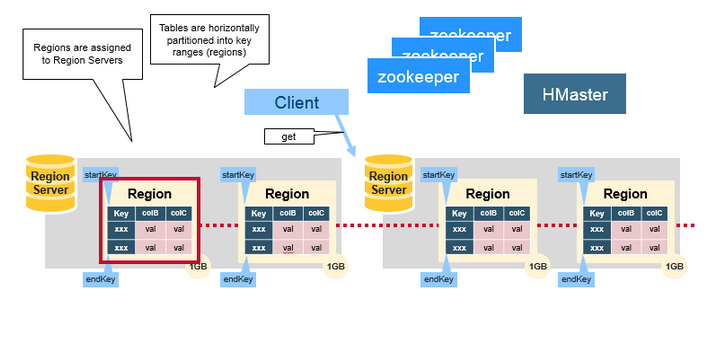
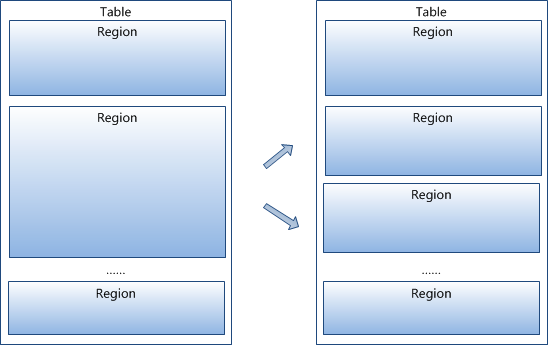
每个表一开始只有一个 Region,随着数据不断增加,Region 会不断增大,当增大到一个阀值的时候,Region 就会等分为两个新的 Region。当 Table 中的行不断增多,就会有越来越多的 Region。
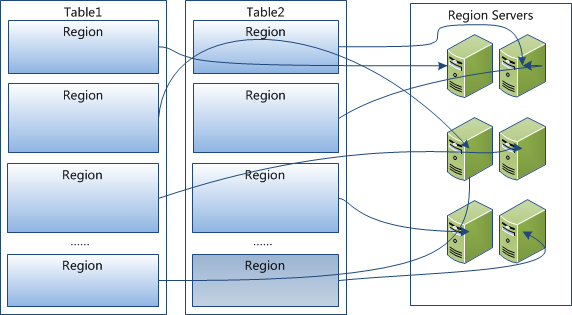
Region 是 HBase 中分布式存储和负载均衡的最小单元。这意味着不同的 Region 可以分布在不同的 Region Server 上。但一个 Region 是不会拆分到多个 Server 上的。
2.2 Region Server
Region Server 运行在 HDFS 的 DataNode 上。它具有以下组件:
- WAL(Write Ahead Log,预写日志):用于存储尚未进持久化存储的数据记录,以便在发生故障时进行恢复。
- BlockCache:读缓存。它将频繁读取的数据存储在内存中,如果存储不足,它将按照
最近最少使用原则清除多余的数据。 - MemStore:写缓存。它存储尚未写入磁盘的新数据,并会在数据写入磁盘之前对其进行排序。每个 Region 上的每个列族都有一个 MemStore。
- HFile :将行数据按照 Key\Values 的形式存储在文件系统上。
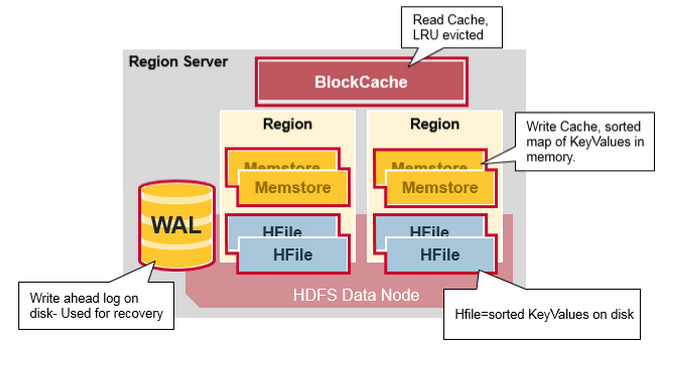
Region Server 存取一个子表时,会创建一个 Region 对象,然后对表的每个列族创建一个 Store 实例,每个 Store 会有 0 个或多个 StoreFile 与之对应,每个 StoreFile 则对应一个 HFile,HFile 就是实际存储在 HDFS 上的文件。
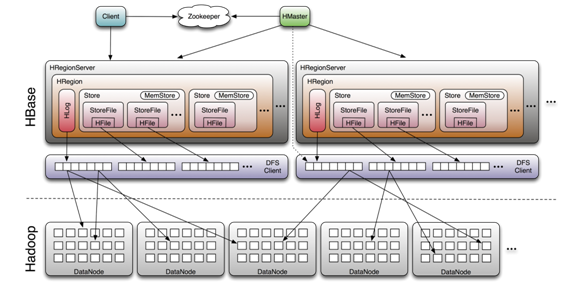
三、Hbase系统架构
3.1 系统架构
HBase 系统遵循 Master/Salve 架构,由三种不同类型的组件组成:
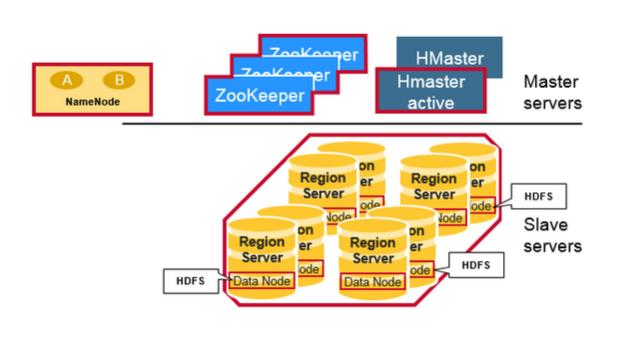
Zookeeper
保证任何时候,集群中只有一个 Master;
存贮所有 Region 的寻址入口;
实时监控 Region Server 的状态,将 Region Server 的上线和下线信息实时通知给 Master;
存储 HBase 的 Schema,包括有哪些 Table,每个 Table 有哪些 Column Family 等信息。
Master
为 Region Server 分配 Region ;
负责 Region Server 的负载均衡 ;
发现失效的 Region Server 并重新分配其上的 Region;
GFS 上的垃圾文件回收;
处理 Schema 的更新请求。
Region Server
Region Server 负责维护 Master 分配给它的 Region ,并处理发送到 Region 上的 IO 请求;
Region Server 负责切分在运行过程中变得过大的 Region。
3.2 组件间的协作
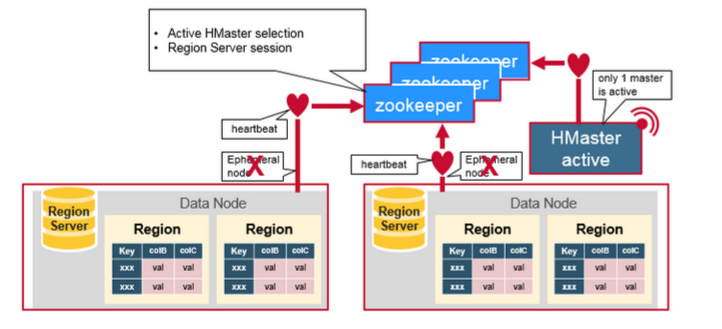
HBase 使用 ZooKeeper 作为分布式协调服务来维护集群中的服务器状态。 Zookeeper 负责维护可用服务列表,并提供服务故障通知等服务:
每个 Region Server 都会在 ZooKeeper 上创建一个临时节点,Master 通过 Zookeeper 的 Watcher 机制对节点进行监控,从而可以发现新加入的 Region Server 或故障退出的 Region Server;
所有 Masters 会竞争性地在 Zookeeper 上创建同一个临时节点,由于 Zookeeper 只能有一个同名节点,所以必然只有一个 Master 能够创建成功,此时该 Master 就是主 Master,主 Master 会定期向 Zookeeper 发送心跳。备用 Masters 则通过 Watcher 机制对主 HMaster 所在节点进行监听;
如果主 Master 未能定时发送心跳,则其持有的 Zookeeper 会话会过期,相应的临时节点也会被删除,这会触发定义在该节点上的 Watcher 事件,使得备用的 Master Servers 得到通知。所有备用的 Master Servers 在接到通知后,会再次去竞争性地创建临时节点,完成主 Master 的选举。
四、数据的读写流程简述
4.1 写入数据的流程
Client 向 Region Server 提交写请求;
Region Server 找到目标 Region;
Region 检查数据是否与 Schema 一致;
如果客户端没有指定版本,则获取当前系统时间作为数据版本;
将更新写入 WAL Log;
将更新写入 Memstore;
判断 Memstore 存储是否已满,如果存储已满则需要 flush 为 Store Hfile 文件。
更为详细写入流程可以参考:HBase - 数据写入流程解析
4.2 读取数据的流程
以下是客户端首次读写 HBase 上数据的流程:
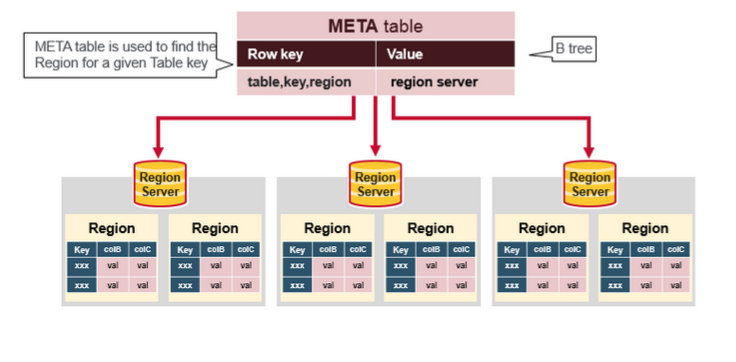
客户端从 Zookeeper 获取
META表所在的 Region Server;客户端访问
META表所在的 Region Server,从META表中查询到访问行键所在的 Region Server,之后客户端将缓存这些信息以及META表的位置;客户端从行键所在的 Region Server 上获取数据。
如果再次读取,客户端将从缓存中获取行键所在的 Region Server。这样客户端就不需要再次查询 META 表,除非 Region 移动导致缓存失效,这样的话,则将会重新查询并更新缓存。
注:META 表是 HBase 中一张特殊的表,它保存了所有 Region 的位置信息,META 表自己的位置信息则存储在 ZooKeeper 上。
更为详细读取数据流程参考:
参考资料
本篇文章内容主要参考自官方文档和以下两篇博客,图片也主要引用自以下两篇博客:
官方文档:
更多大数据系列文章可以参见 GitHub 开源项目: 大数据入门指南
HBase 系列(二)—— HBase 系统架构及数据结构的更多相关文章
- HBase 学习之路(二)—— HBase系统架构及数据结构
一.基本概念 一个典型的Hbase Table 表如下: 1.1 Row Key (行键) Row Key是用来检索记录的主键.想要访问HBase Table中的数据,只有以下三种方式: 通过指定的R ...
- HBase 系统架构及数据结构
一.基本概念 2.1 Row Key (行键) 2.2 Column Family(列族) 2.3 Column Qualifier (列限定符) 2.4 Column ...
- HBase系统架构及数据结构(转)
原文链接:Hbase系统架构及数据结构 HBase中的表一般有这样的特点: 1 大:一个表可以有上亿行,上百万列 2 面向列:面向列(族)的存储和权限控制,列(族)独立检索. 3 稀疏:对于为空(nu ...
- 【HBase】二、HBase实现原理及系统架构
整个Hadoop生态中大量使用了master-slave的主从式架构,如同HDFS中的namenode和datanode,MapReduce中的JobTracker和TaskTracker,YAR ...
- Windows Internals学习笔记(二)系统架构
参考资料: 1. <Windows Internals> 2. http://bestcbooks.com 3. Windows Drive Kit 4. Microsoft Window ...
- 深入理解Tomcat系列之一:系统架构(转)
前言 Tomcat是Apache基金组织下的开源项目,性质是一个Web服务器.下面这种情况很普遍:在eclipse床架一个web项目并部署到Tomcat中,启动tomcat,在浏览器中输入一个类似ht ...
- Zookeeper系列二:分布式架构详解、分布式技术详解、分布式事务
一.分布式架构详解 1.分布式发展历程 1.1 单点集中式 特点:App.DB.FileServer都部署在一台机器上.并且访问请求量较少 1.2 应用服务和数据服务拆分 特点:App.DB.Fi ...
- 软件架构系列二:Clean架构
外圈的层次可以依赖内层,反之不可以:内圈核心的实体代表业务,不可以依赖其所处的技术环境. 这是著名软件大师Bob大叔提出的一种架构,也是当前各种语言开发架构.干净架构提出了一种单向依赖关系,从而在逻辑 ...
- Hbase系列文章
Hbase系列文章 HBase(一): c#访问hbase组件开发 HBase(二): c#访问HBase之股票行情Demo HBase(三): Azure HDInsigt HBase表数据导入本地 ...
随机推荐
- jQuery - parents() 获得最近的祖先元素方法
答案 : parents()[0] <div class="pg-ins layer p_close"> <div class="sign_con&qu ...
- 如何入门 MySQL
如何入门MySQL 前言: 关于如何入门MySQL,后台有好多同学咨询我,可能部分读者刚开始学习MySQL,我前面发的文章对部分同学来说暂时接触不到.原本写技术文章的目的是记录自己的工作学习,没有考虑 ...
- HBaseCon Asia2019 会议总结
一.首先会议流程. 1. The current status of HBase 2.The advantage and technology trend of HBase on the cloud ...
- UVA10763 交换学生 Foreign Exchange 题解
题目链接: https://www.luogu.org/problemnew/show/UVA10763 题目分析: 本题我首先想到的做法是把每一个数都map一下,然后互相判断,例如a,b两人准备交换 ...
- EF简介及CRUD简单DEMO
一.实体框架(Entity FrameWork)简介 • 简称EF • 与Asp.Net MVC关系与ADO.NET关系 • ADO.NET Entity FrameWork是微软以ADO.NET为基 ...
- 个人永久性免费-Excel催化剂功能第38波-比Vlookup更好用的查找引用函数
谈起Excel的函数,有一个函数生来自带明星光环,在表哥表姐群体中无人不知,介绍它的教程更是铺天盖地,此乃VLOOKUP函数也.今天Excel催化剂在这里冒着被火喷的风险,大胆地宣布一个比VLOOKU ...
- 个人永久性免费-Excel催化剂功能第34波-提取中国身份证信息、农历日期转换相关功能
这两天又被刷朋友圈,又来了一个自主研发红芯浏览器,国产啊国产,这是谁的梦.就算国产了,自主了,无底线的夸大吹嘘无道德,企业如是,国家如是,大清已亡!再牛B的技术落在天天删敏感信息.无法治.无安全感可言 ...
- 搭建python环境
参考文章:https://blog.csdn.net/qq_33855133/article/details/73106176 对于配置环境变量,懂些技术的人来说,都是很简单. 变量是在操作系统中一个 ...
- 【Spring】org.springframework.web.context.ContextLoaderListen 报错
详细信息如下: org.apache.catalina.core.StandardContext.listenerStart Error configuring application listene ...
- Github上fork的项目如何merge原Git项目
问题场景 小明在Github上fork了一个大佬的项目,并clone到本地开发一段时间,再提交merge request到原Git项目,过了段时间,原作者联系小明,扔给他下面这幅截图并告知合并处理冲突 ...