(转)RocketMQ工作原理
原文:https://blog.csdn.net/lyly4413/article/details/80838716
1.消息中间件的发展:
第一代以ActiveMQ为代表,遵循JMS(java消息服务)规范 第二代以RabbitMQ为代表是一个有Erlang语言开发的AMQP(高级消息队列协议)的开源实现 第三代以kafka为代表,是一代高吞吐、高可用的消息中间件,以及RocketMQ
RocketMQ的特点:
1.RocketMQ 是一款分布式、队列模型的消息中间件,具有以下特点:
2.能够保证严格的消息顺序
3.提供丰富的消息拉取模式
4.高效的订阅者水平扩展能力
5.实时的消息订阅机制
6.亿级消息堆积能力
7.分布式高可用的部署架构,满足至少一次消息传递语义
8.提供 docker 镜像用于隔离测试和云集群部署
9.提供配置、指标和监控等功能丰富的 Dashboard
选用理由:
a.强调集群无单点,可扩展,任意一点高可用,水平可扩展。
b.海量消息堆积能力,消息堆积后,写入低延迟。
c.支持上万个队列
d.消息失败重试机制
e.消息可查询
f.开源社区活跃
g.成熟度(经过双十一考验)
RocketMQ物理部署结构:

rocketMQ几个概念:
producer:消息生产者,生产者的作用就是将消息发送到 MQ,生产者本身既可以产生消息,如读取文本信息等。也可以对外提供接口,由外部应用来调用接口,再由生产者将收到的消息发送到 MQ
producer group: 生产者组,简单来说就是多个发送同一类消息的生产者称之为一个生产者组。在这里可以不用关心,只要知道有这么一个概念即可,Producer实例可以是多机器、单机器多进程、单进程中的多对象。Producer可以发送多个Topic。处理分布式事务时,也需要Producer集群提高可靠性
consumer : 消息消费者,简单来说,消费 MQ 上的消息的应用程序就是消费者,至于消息是否进行逻辑处理,还是直接存储到数据库等取决于业务需要
consumer group : 消费者组,和生产者类似,消费同一类消息的多个 consumer 实例组成一个消费者组.Consumer实例 的集合。Consumer 实例可以是多机器、但机器多进程、单进程中的多对象。同一个Group中的实例,在集群模式下,以均摊的方式消费;在广播模式下,每个实例都全部消费。
Topic : Topic 是一种消息的逻辑分类,比如说你有订单类的消息,也有库存类的消息,那么就需要进行分类,一个是订单 Topic 存放订单相关的消息,一个是库存 Topic 存储库存相关的消息
Message : Message 是消息的载体。一个 Message 必须指定 topic,相当于寄信的地址。Message 还有一个可选的 tag 设置,以便消费端可以基于 tag 进行过滤消息。也可以添加额外的键值对,例如你需要一个业务 key 来查找 broker 上的消息,方便在开发过程中诊断问题
Tag : 标签可以被认为是对 Topic 进一步细化。一般在相同业务模块中通过引入标签来标记不同用途的消息
Broker : Broker 是 RocketMQ 系统的主要角色,其实就是前面一直说的 MQ。Broker 接收来自生产者的消息,储存以及为消费者拉取消息的请求做好准备
Name Server : Name Server 为 producer 和 consumer 提供路由信息
Push Consumer : 应用通常向Consumer对象注册一个Listener接口,一旦收到消息,Consumer对象立刻回调Listener接口方法。所以,所谓Push指的是客户端内部的回调机制,并不是与服务端之间的机制
Pull Consumer : 应用通常主动调用Consumer从服务端拉消息,然后处理。这用的就是短轮询方式了,在不同情况下,与长轮询各有优点
Broker 的搭建方式:
1.单个Master模式 : 这种方式风险较大,一旦 Broker 重启或者宕机时,会导致整个服务不可用,不建议线上环境使用
2.多个Master模式: 一个集群无 Slave,全是 Master,例如 2 个 Master 戒者 3 个 Master
优点:配置简单,单个 Master 宕机或重启维护对应用无影响,在磁盘配置为 RAID10 时,即使机器宕机不可恢复情况下,由于 RAID10 磁盘非常可靠,消息也不会丢(异步刷盘丢失少量消息,同步刷盘一条会丢)。性能最高。
缺点:单台机器宕机期间,这台机器上未被消费的消息在机器恢复之前不可订阅,消息实时性会受到影响。
3.多Msater多slave模式,异步复制 : 每个 Master 配置一个 Slave,有多对 Master-Slave,HA 采用异步复制方式,主备有短暂消息延迟,毫秒级。
优点:即使磁盘损坏,消息丢失的非常少,且消息实时性不会受影响,因为 Master 宕机后,消费者仍然可以从 Slave 消费,此过程对应用透明。不需要人工干预。性能同多 Master 模式几乎一样。
缺点:Master 宕机,磁盘损坏情况,会丢失少量消息
4.多Master多slave模式,同步双写 : 每个 Master 配置一个 Slave,有多对 Master-Slave,HA 采用同步双写方式,主备都写成功,向应用返回成功。
优点:数据不服务都无单点,Master 宕机情况下,消息无延迟,服务可用性与数据可用性都非常高
缺点:性能比异步复制模式略低,大约低 10%左右,发送单个消息的 RT 会略高。目前主宕机后,备机不能能自动切换为主机,后续会支持自动切换功能。
RocketMQ架构:
rocketmq-broker:整个mq的核心,他能够接受producer和consumer的请求,并调用store层服务对消息进行处理。HA服务的基本单元,支持同步双写,异步双写等模式。
rocketmq-client::mq客户端实现,目前官方仅仅开源了java版本的mq客户端,c++,go客户端有社区开源贡献。
rocketmq-common:一些模块间通用的功能类,比如一些配置文件、常量。
rocketmq-example:官方提供的例子,对典型的功能比如order message,push consumer,pull consumer的用法进行了示范。
rocketmq-filtersrv:消息过滤服务,相当于在broker和consumer中间加入了一个filter代理。
rocketmq-remoting:基于netty的底层通信实现,所有服务间的交互都基于此模块。
rocketmq-srvut:解析命令行的工具类。
rocketmq-store:存储层实现,同时包括了索引服务,高可用HA服务实现。
rocketmq-tools:mq集群管理工具,提供了消息查询等功能。
RocketMQ存储方式:
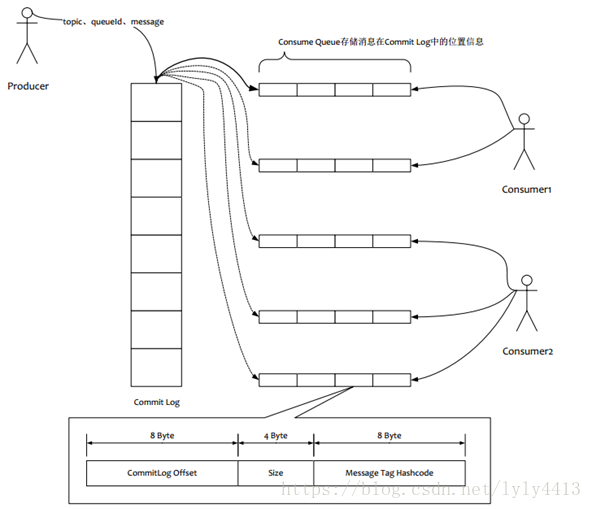
如上图所示:
(1)所有数据单独储存到commit Log ,完全顺序写,随机读
(2)对最终用户展现的队列实际只储存消息在Commit Log 的位置信息,并且串行方式刷盘
这样做的好处:
(1)队列轻量化,单个队列数据量非常少
(2)对磁盘的访问串行话,避免磁盘竞争,不会因为队列增加导致IOWait增高
每个方案都有优缺点,他的缺点是:
(1)写虽然是顺序写,但是读却变成了随机读
(2)读一条消息,会先读Consume Queue,再读Commit Log,增加了开销
(3)要保证Commit Log 与 Consume Queue完全的一致,增加了编程的复杂度
以上缺点如何克服:
(1)随机读,尽可能让读命中pagecache,减少IO操作,所以内存越大越好。如果系统中堆积的消息过多,读数据要访问硬盘会不会由于随机读导致系统性能急剧下降,答案是否定的。
a)访问pagecache时,即使只访问1K的消息,系统也会提前预读出更多的数据,在下次读时就可能命中pagecache
b)随机访问Commit Log 磁盘数据,系统IO调度算法设置为NOOP方式,会在一定程度上将完全的随机读变成顺序跳跃方式,而顺序跳跃方式读较完全的随机读性能高5倍
(2)由于Consume Queue存储数量极少,而且顺序读,在pagecache的与读取情况下,Consume Queue的读性能与内存几乎一直,即使堆积情况下。所以可以认为Consume Queue完全不会阻碍读性能
(3)Commit Log中存储了所有的元信息,包含消息体,类似于MySQl、Oracle的redolog,所以只要有Commit Log存在, Consume Queue即使丢失数据,仍可以恢复出来
(转)RocketMQ工作原理的更多相关文章
- RocketMQ架构原理解析(四):消息生产端(Producer)
RocketMQ架构原理解析(一):整体架构 RocketMQ架构原理解析(二):消息存储(CommitLog) RocketMQ架构原理解析(三):消息索引(ConsumeQueue & I ...
- 菜鸟学Struts2——Struts工作原理
在完成Struts2的HelloWorld后,对Struts2的工作原理进行学习.Struts2框架可以按照模块来划分为Servlet Filters,Struts核心模块,拦截器和用户实现部分,其中 ...
- 【夯实Nginx基础】Nginx工作原理和优化、漏洞
本文地址 原文地址 本文提纲: 1. Nginx的模块与工作原理 2. Nginx的进程模型 3 . NginxFastCGI运行原理 3.1 什么是 FastCGI ...
- HashMap的工作原理
HashMap的工作原理 HashMap的工作原理是近年来常见的Java面试题.几乎每个Java程序员都知道HashMap,都知道哪里要用HashMap,知道HashTable和HashMap之间 ...
- 【Oracle 集群】ORACLE DATABASE 11G RAC 知识图文详细教程之RAC 工作原理和相关组件(三)
RAC 工作原理和相关组件(三) 概述:写下本文档的初衷和动力,来源于上篇的<oracle基本操作手册>.oracle基本操作手册是作者研一假期对oracle基础知识学习的汇总.然后形成体 ...
- ThreadLocal 工作原理、部分源码分析
1.大概去哪里看 ThreadLocal 其根本实现方法,是在Thread里面,有一个ThreadLocal.ThreadLocalMap属性 ThreadLocal.ThreadLocalMap t ...
- Servlet的生命周期及工作原理
Servlet生命周期分为三个阶段: 1,初始化阶段 调用init()方法 2,响应客户请求阶段 调用service()方法 3,终止阶段 调用destroy()方法 Servlet初始化阶段: 在 ...
- 代码管理工具 --- git的学习笔记二《git的工作原理》
通过几个问题来学习代码管理工具之git 一.git是什么?为什么要用它?使用它的好处?它与svn的区别,在Mac上,比较好用的git图形界面客户端有 git 是分布式的代码管理工具,使用它是因为,它便 ...
- 【原】Learning Spark (Python版) 学习笔记(三)----工作原理、调优与Spark SQL
周末的任务是更新Learning Spark系列第三篇,以为自己写不完了,但为了改正拖延症,还是得完成给自己定的任务啊 = =.这三章主要讲Spark的运行过程(本地+集群),性能调优以及Spark ...
随机推荐
- 安卓逆向基础(002)-android虚拟机
一, android分两种 1.Android 5.0以下(不含5.0) dalvik字节码 为dalvik虚拟机(jit机制) 基于寄存器架构 .dex=>dexopt=>.odex d ...
- VS2019 开发Django(一)------环境配置
导航:VS2019开发Django系列 缘起:学习是我一直在做的一件事情,但是,可怕的是不知道学习什么,然后止步不前,安于现状,曾经很长的一段时间,我是不知道学习什么,工作上的事情,其实是相对固定的, ...
- 脚本批量执行Redis命令
1.将命令写在文件中 数据量比较大的话,建议用程序去生成文件.例如: List<String> planIdList = planDao.findAll().parallelStream( ...
- ASP.NET CORE 使用Consul实现服务治理与健康检查(2)——源码篇
题外话 笔者有个习惯,就是在接触新的东西时,一定要先搞清楚新事物的基本概念和背景,对之有个相对全面的了解之后再开始进入实际的编码,这样做最主要的原因是尽量避免由于对新事物的认知误区导致更大的缺陷,Bu ...
- MySQL基础-存储过程
存储过程 定义:将一批为了完成特定功能的SQL语句集,根据传入的参数(也可没有),调用,完成单个sql语句更复杂的功能 存储过程思想很简单,就是SQL语句层面上的代码封装和重用 优点:1) 可封装,并 ...
- IT兄弟连 HTML5教程 和页面布局有关的CSS属性
使用DIV+CSS对网页进行标准化布局前,除了要掌握盒子模型,还要掌握定位和浮动两个比较重要的概念,它们可以控制在页面上排列和显示元素的方式.一个盒子是装内容的区块,如果多个盒子组合在一起使用,再通过 ...
- Ansible-下部
ansible-playbook playbook是由一个或多个模块组成的,使用多个不同的模块,完成一件事情. ansible软件特点 可以实现批量管理可以实现批量部署ad-hoc(批量执行命令)- ...
- react + typescript 学习
react,前端三大框架之一,也是非常受开发者追捧的一门技术.而 typescript 是 javascript 的超集,主要特点是对 类型 的检查.二者的结合必然是趋势,不,已经是趋势了.react ...
- Python高级特性——迭代器
可以直接用for循环的数据类型有: 集合数据类型,如:list.tuple.dict.set.str等: 生成器generator,包括生成器和带yield的generator function. 以 ...
- Python中:dict(或对象)与json之间的互相转化
在Python语言中,json数据与dict字典以及对象之间的转化,是必不可少的操作. 在Python中自带json库.通过import json导入. 在json模块有2个方法, loads():将 ...