Attention 和self-attention
1.Attention
最先出自于Bengio团队一篇论文:NEURAL MACHINE TRANSLATION BY JOINTLY LEARNING TO ALIGN AND TRANSLATE ,论文在2015年发表在ICLR。
encoder-decoder模型通常的做法是将一个输入的句子编码成一个固定大小的state,然后将这样的一个state输入到decoder中的每一个时刻,这种做法对处理长句子会很不利,尤其是随着句子长度的增加,效果急速下滑。
论文动机:是针对encoder-decoder长句子翻译效果不好的问题。
解决原理:仿造人脑结构,对一张图片或是一个句子,能够重点关注到不同部分。
论文解决思路:在生成当前词的时候,只要把上一个state与所有的input word作为融合,而后做一个权重计算。通过这种方式生成的词就会有针对性,在句子长度较长时效果尤其明显。
整体框架如下图:

2.Self-attention
出自于Google团队的论文:Attention Is All You Need ,2017年发表在NIPS。
论文动机:RNN本身的结构,阻碍了并行化;同时RNN对长距离依赖问题,效果会很差。
解决思路:通过不同词向量之间矩阵相乘,得到一个词与词之间的相似度,进而无距离限制。
整体结构:

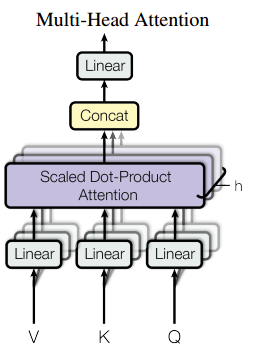
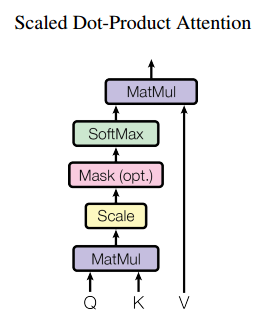
multi-head attention:
将一个词的vector切分成h个维度,求attention相似度时每个h维度计算。由于单词映射在高维空间作为向量形式,每一维空间都可以学到不同的特征,相邻空间所学结果更相似,相较于全体空间放到一起对应更加合理。比如对于vector-size=512的词向量,取h=8,每64个空间做一个attention,学到结果更细化。
self-attention:
每个词位的词都可以无视方向和距离,有机会直接和句子中的每个词encoding。比如下图这个句子,每个单词和同句其他单词之间都有一条边作为联系,边的颜色越深表明联系越强,而一般意义模糊的词语所连的边都比较深。比如:law,application,missing,opinion。

Attention 和self-attention的更多相关文章
- 注意力机制---Attention、local Attention、self Attention、Hierarchical attention
一.编码-解码架构 目的:解决语音识别.机器翻译.知识问答等输出输入序列长度不相等的任务. C是输入的一个表达(representation),包含了输入序列的有效信息. 它可能是一个向量,也可能是一 ...
- 可视化展示attention(seq2seq with attention in tensorflow)
目前实现了基于tensorflow的支持的带attention的seq2seq.基于tf 1.0官网contrib路径下seq2seq 由于后续版本不再支持attention,迁移到melt并做了进一 ...
- (转)注意力机制(Attention Mechanism)在自然语言处理中的应用
注意力机制(Attention Mechanism)在自然语言处理中的应用 本文转自:http://www.cnblogs.com/robert-dlut/p/5952032.html 近年来,深度 ...
- 注意力机制(Attention Mechanism)在自然语言处理中的应用
注意力机制(Attention Mechanism)在自然语言处理中的应用 近年来,深度学习的研究越来越深入,在各个领域也都获得了不少突破性的进展.基于注意力(attention)机制的神经网络成为了 ...
- Attention and Augmented Recurrent Neural Networks
Attention and Augmented Recurrent Neural Networks CHRIS OLAHGoogle Brain SHAN CARTERGoogle Brain Sep ...
- (转)Attention
本文转自:http://www.cosmosshadow.com/ml/%E7%A5%9E%E7%BB%8F%E7%BD%91%E7%BB%9C/2016/03/08/Attention.ht ...
- Multimodal —— 看图说话(Image Caption)任务的论文笔记(二)引入attention机制
在上一篇博客中介绍的论文"Show and tell"所提出的NIC模型采用的是最"简单"的encoder-decoder框架,模型上没有什么新花样,使用CNN ...
- 深度学习之seq2seq模型以及Attention机制
RNN,LSTM,seq2seq等模型广泛用于自然语言处理以及回归预测,本期详解seq2seq模型以及attention机制的原理以及在回归预测方向的运用. 1. seq2seq模型介绍 seq2se ...
- Attention Model(注意力模型)思想初探
1. Attention model简介 0x1:AM是什么 深度学习里的Attention model其实模拟的是人脑的注意力模型,举个例子来说,当我们观赏一幅画时,虽然我们可以看到整幅画的全貌,但 ...
- 【NLP】Attention Model(注意力模型)学习总结
最近一直在研究深度语义匹配算法,搭建了个模型,跑起来效果并不是很理想,在分析原因的过程中,发现注意力模型在解决这个问题上还是很有帮助的,所以花了两天研究了一下. 此文大部分参考深度学习中的注意力机制( ...
随机推荐
- springboot自动装配(3)---条件注解@Conditional
之前有说到springboot自动装配的时候,都是去寻找一个XXXAutoConfiguration的配置类,然而我们的springboot的spring.factories文件中有各种组件的自动装配 ...
- Vue 02
目录 表单指令v-model 条件指令v-if 循环指令v-for 分隔符delimiters 过滤器filters 计算属性computed 监听属性watch 前端数据库 表单指令v-model ...
- 【Java Web开发学习】Spring MVC文件上传
[Java Web开发学习]Spring MVC文件上传 转载:https://www.cnblogs.com/yangchongxing/p/9290489.html 文件上传有两种实现方式,都比较 ...
- 整理了2019年上千道Java面试题,近500页文档,用了1个月时间!
spring 面试题 1.一般问题 1.1.不同版本的 spring Framework 有哪些主要功能? 1.2.什么是 spring Framework? 1.3.列举 spring Framew ...
- Java虚拟机堆和栈详细解析,以后面试再也不怕问jvm了!
堆 Java堆是和Java应用程序关系最密切的内存空间,几乎所有的对象都放在其中,并且Java堆完全是自动化管理,通过垃圾收集机制,垃圾对象会自动清理,不需自己去释放. 根据垃圾回收机制的不同,Jav ...
- Spring Boot 打成的 jar 和普通的 jar 有什么区别 ?
Spring Boot 打成的 jar 和普通的 jar 有什么区别 ? Spring Boot 打成的 jar Spring Boot的项目终止以jar包的形式进行打包,这种jar包可以通过可以通过 ...
- leetcode-算法系列-两数之和
本系列的题目都是出自于"leetcode" 用博客记录是为了加强自己的记忆与理解,也希望能和大家交流更好更优的解题思路. 题目: 给定一个整数数组和一个目标值,找出数组中和为目标值 ...
- Java 判断密码是否是大小写字母、数字、特殊字符中的至少三种
public class CheckPassword { //数字 public static final String REG_NUMBER = ".*\\d+.*"; //小写 ...
- python基础知识第三篇(列表)
列表 list 类 中提供的方法 li=[1,5,dhud,dd,] 通过list类创建的对象 中括号括起来 逗号分隔每个元素 列表中的元素可以是数字,字符串,也可以是列表,也可以是布尔值 所有的都能 ...
- elementui移动dialog
1.在创建Vue对象时添加全局属性 Vue.directive('dialogDrag', { bind(el, binding, vnode, oldVnode) { const dialogHea ...