Attention 和self-attention
1.Attention
最先出自于Bengio团队一篇论文:NEURAL MACHINE TRANSLATION BY JOINTLY LEARNING TO ALIGN AND TRANSLATE ,论文在2015年发表在ICLR。
encoder-decoder模型通常的做法是将一个输入的句子编码成一个固定大小的state,然后将这样的一个state输入到decoder中的每一个时刻,这种做法对处理长句子会很不利,尤其是随着句子长度的增加,效果急速下滑。
论文动机:是针对encoder-decoder长句子翻译效果不好的问题。
解决原理:仿造人脑结构,对一张图片或是一个句子,能够重点关注到不同部分。
论文解决思路:在生成当前词的时候,只要把上一个state与所有的input word作为融合,而后做一个权重计算。通过这种方式生成的词就会有针对性,在句子长度较长时效果尤其明显。
整体框架如下图:

2.Self-attention
出自于Google团队的论文:Attention Is All You Need ,2017年发表在NIPS。
论文动机:RNN本身的结构,阻碍了并行化;同时RNN对长距离依赖问题,效果会很差。
解决思路:通过不同词向量之间矩阵相乘,得到一个词与词之间的相似度,进而无距离限制。
整体结构:

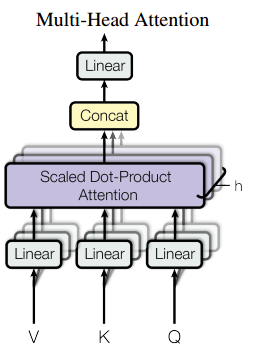
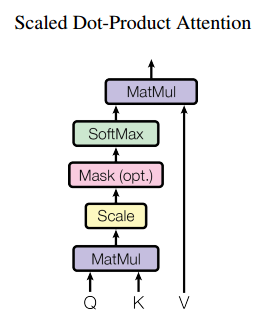
multi-head attention:
将一个词的vector切分成h个维度,求attention相似度时每个h维度计算。由于单词映射在高维空间作为向量形式,每一维空间都可以学到不同的特征,相邻空间所学结果更相似,相较于全体空间放到一起对应更加合理。比如对于vector-size=512的词向量,取h=8,每64个空间做一个attention,学到结果更细化。
self-attention:
每个词位的词都可以无视方向和距离,有机会直接和句子中的每个词encoding。比如下图这个句子,每个单词和同句其他单词之间都有一条边作为联系,边的颜色越深表明联系越强,而一般意义模糊的词语所连的边都比较深。比如:law,application,missing,opinion。

Attention 和self-attention的更多相关文章
- 注意力机制---Attention、local Attention、self Attention、Hierarchical attention
一.编码-解码架构 目的:解决语音识别.机器翻译.知识问答等输出输入序列长度不相等的任务. C是输入的一个表达(representation),包含了输入序列的有效信息. 它可能是一个向量,也可能是一 ...
- 可视化展示attention(seq2seq with attention in tensorflow)
目前实现了基于tensorflow的支持的带attention的seq2seq.基于tf 1.0官网contrib路径下seq2seq 由于后续版本不再支持attention,迁移到melt并做了进一 ...
- (转)注意力机制(Attention Mechanism)在自然语言处理中的应用
注意力机制(Attention Mechanism)在自然语言处理中的应用 本文转自:http://www.cnblogs.com/robert-dlut/p/5952032.html 近年来,深度 ...
- 注意力机制(Attention Mechanism)在自然语言处理中的应用
注意力机制(Attention Mechanism)在自然语言处理中的应用 近年来,深度学习的研究越来越深入,在各个领域也都获得了不少突破性的进展.基于注意力(attention)机制的神经网络成为了 ...
- Attention and Augmented Recurrent Neural Networks
Attention and Augmented Recurrent Neural Networks CHRIS OLAHGoogle Brain SHAN CARTERGoogle Brain Sep ...
- (转)Attention
本文转自:http://www.cosmosshadow.com/ml/%E7%A5%9E%E7%BB%8F%E7%BD%91%E7%BB%9C/2016/03/08/Attention.ht ...
- Multimodal —— 看图说话(Image Caption)任务的论文笔记(二)引入attention机制
在上一篇博客中介绍的论文"Show and tell"所提出的NIC模型采用的是最"简单"的encoder-decoder框架,模型上没有什么新花样,使用CNN ...
- 深度学习之seq2seq模型以及Attention机制
RNN,LSTM,seq2seq等模型广泛用于自然语言处理以及回归预测,本期详解seq2seq模型以及attention机制的原理以及在回归预测方向的运用. 1. seq2seq模型介绍 seq2se ...
- Attention Model(注意力模型)思想初探
1. Attention model简介 0x1:AM是什么 深度学习里的Attention model其实模拟的是人脑的注意力模型,举个例子来说,当我们观赏一幅画时,虽然我们可以看到整幅画的全貌,但 ...
- 【NLP】Attention Model(注意力模型)学习总结
最近一直在研究深度语义匹配算法,搭建了个模型,跑起来效果并不是很理想,在分析原因的过程中,发现注意力模型在解决这个问题上还是很有帮助的,所以花了两天研究了一下. 此文大部分参考深度学习中的注意力机制( ...
随机推荐
- Python之数据分析工具包介绍以及安装【入门必学】
前言本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 首先我们来看 Mac版 按照需求大家依次安装,如果你还没学到数据分析,建议你 ...
- usb2.0高速视频采集之68013A寄存器配置说明
任何的固件编程离不开与与原理图参考,图纸中所采用的是USB的Slave_fifo传输方式,具体配置与图纸对应即可. •USB_IFCLK:同步Slave_FIFO模式,输入频率范围5M-48M,在FP ...
- hdu 6298 Maximum Multiple (简单数论)
Maximum Multiple Time Limit: 4000/2000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Others) ...
- 基于TCP协议之socket编程
#服务端 #导入一个socket模块 import socket #想象成买手机打电话:socket.SOCK_STREAM 表示建立tcp连接 ,udp连接socket.SOCK_DGRAM #买了 ...
- cookie与session django中间件
目录 一.什么是cookie 二.django中操作cookie 2.1 如何操作cookie 2.2 操作cookie 三.什么是session 四.django中操作session 4.1 创建c ...
- webpack构建原理和实现简单webpack
webpack打包原理分析 基础配置,webpack会读取配置 (找到入口模块) 如:读取webpack.config.js配置文件: const path = require("path& ...
- 下载Abook 高等教育出版社网站资料
一.背景 又快到了期末复习周,这个学期学了一门操作系统,老师没有给课本习题的答案,说是配套网站上有,我看了一下,确实有,是高等教育出版社的数字课程网站Abookl http://abook.hep.c ...
- Hack the Zico2 VM (CTF Challenge)
下载链接: Download this VM here: https://download.vulnhub.com/zico/zico2.ova 端口扫描: ╰─ nmap -p1-65535 -sV ...
- java 获取当前年份 月份,当月第一天和最后一天
获取当前年份 月份,当月第一天和最后一天,工作中会经常用到,下面是代码: package basic.day01; import java.text.SimpleDateFormat; import ...
- Linux Zookeeper 安装, 带视频
疯狂创客圈 Java 高并发[ 亿级流量聊天室实战]实战系列 [博客园总入口 ] 面试必备+面试必备之 高并发基础书籍 [Netty Zookeeper Redis 高并发实战 ] 疯狂创客圈 高并发 ...