图示详解BERT模型的输入与输出
一、BERT整体结构
BERT主要用了Transformer的Encoder,而没有用其Decoder,我想是因为BERT是一个预训练模型,只要学到其中语义关系即可,不需要去解码完成具体的任务。整体架构如下图:
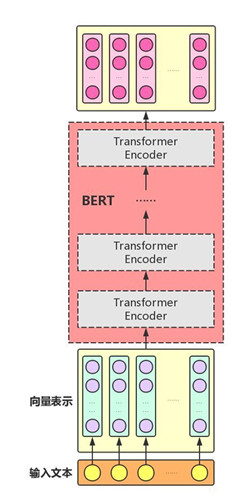
多个Transformer Encoder一层一层地堆叠起来,就组装成了BERT了,在论文中,作者分别用12层和24层Transformer Encoder组装了两套BERT模型,两套模型的参数总数分别为110M和340M。
二、再次理解Transformer中的Attention机制
Attention机制的中文名叫“注意力机制”,顾名思义,它的主要作用是让神经网络把“注意力”放在一部分输入上,即:区分输入的不同部分对输出的影响。这里,我们从增强字/词的语义表示这一角度来理解一下Attention机制。
我们知道,一个字/词在一篇文本中表达的意思通常与它的上下文有关。比如:光看“鹄”字,我们可能会觉得很陌生(甚至连读音是什么都不记得吧),而看到它的上下文“鸿鹄之志”后,就对它立马熟悉了起来。因此,字/词的上下文信息有助于增强其语义表示。同时,上下文中的不同字/词对增强语义表示所起的作用往往不同。比如在上面这个例子中,“鸿”字对理解“鹄”字的作用最大,而“之”字的作用则相对较小。为了有区分地利用上下文字信息增强目标字的语义表示,就可以用到Attention机制。
Attention机制主要涉及到三个概念:Query、Key和Value。在上面增强字的语义表示这个应用场景中,目标字及其上下文的字都有各自的原始Value,Attention机制将目标字作为Query、其上下文的各个字作为Key,并将Query与各个Key的相似性作为权重,把上下文各个字的Value融入目标字的原始Value中。如下图所示,Attention机制将目标字和上下文各个字的语义向量表示作为输入,首先通过线性变换获得目标字的Query向量表示、上下文各个字的Key向量表示以及目标字与上下文各个字的原始Value表示,然后计算Query向量与各个Key向量的相似度作为权重(最终形成每个目标字与其上下文的字的权重关系,权重和为1),加权融合目标字的Value向量和各个上下文字的Value向量(其实就是做了点乘),作为Attention的输出,即:目标字的增强语义向量表示。
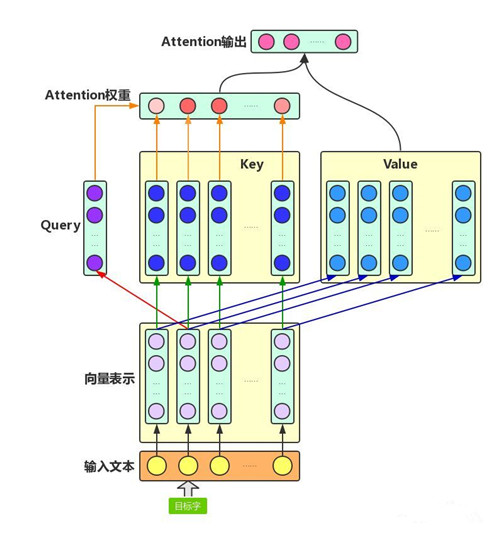
图示展示了第二个字,即目标字的整个Attention计算流程。
三、BERT的预训练结构
BERT实际上是一个语言模型。语言模型通常采用大规模、与特定NLP任务无关的文本语料进行训练,其目标是学习语言本身应该是什么样的。BERT模型其预训练过程就是逐渐调整模型参数,使得模型输出的文本语义表示能够刻画语言的本质,便于后续针对具体NLP任务作微调。
1、Masked LM
Masked LM的任务描述为:给定一句话,随机抹去这句话中的一个或几个词,要求根据剩余词汇预测被抹去的几个词分别是什么,如下图所示
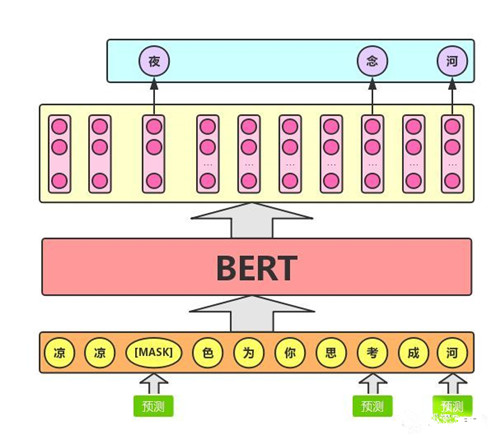
具体来说,文章作者在一句话中随机选择15%的词汇用于预测。对于在原句中被抹去的词汇,80%情况下采用一个特殊符号[MASK]替换,10%情况下采用一个任意词替换,剩余10%情况下保持原词汇不变。这么做的主要原因是:在后续微调任务中语句中并不会出现[MASK]标记,而且这么做的另一个好处是:预测一个词汇时,模型并不知道输入对应位置的词汇是否为正确的词汇(10%概率),这就迫使模型更多地依赖于上下文信息去预测词汇,并且赋予了模型一定的纠错能力。
2、NextSentence Prediction
任务描述为:给定一篇文章中的两句话,判断第二句话在文本中是否紧跟在第一句话之后,如下图所示:

四、BERT的整体输入/输出
BERT模型预训练文本语义表示的过程就好比我们在高中阶段学习语数英、物化生等各门基础学科,夯实基础知识;而模型在特定NLP任务中的参数微调就相当于我们在大学期间基于已有基础知识、针对所选专业作进一步强化,从而获得能够应用于实际场景的专业技能。
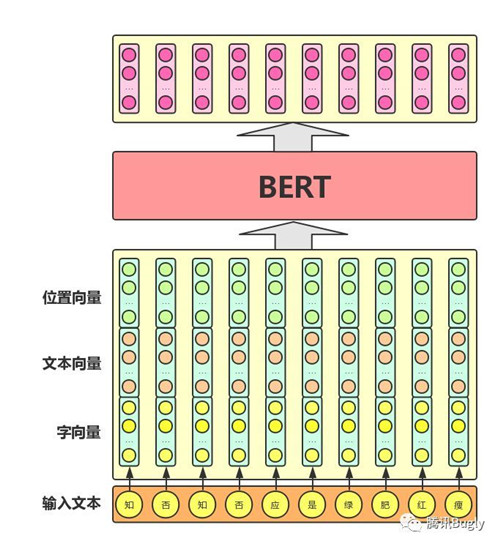
从上图中可以看出,BERT模型通过查询字向量表将文本中的每个字转换为一维向量,作为模型输入;模型输出则是输入各字对应的融合全文语义信息后的向量表示。此外,模型输入除了字向量,还包含另外两个部分:
1. 文本向量:该向量的取值在模型训练过程中自动学习,用于刻画文本的全局语义信息,并与单字/词的语义信息相融合
2. 位置向量:由于出现在文本不同位置的字/词所携带的语义信息存在差异(比如:“我爱你”和“你爱我”),因此,BERT模型对不同位置的字/词分别附加一个不同的向量以作区分
最后,BERT模型将字向量、文本向量和位置向量的加和作为模型输入。特别地,在目前的BERT模型中,文章作者还将英文词汇作进一步切割,划分为更细粒度的语义单位(WordPiece),例如:将playing分割为play和##ing;此外,对于中文,目前作者尚未对输入文本进行分词,而是直接将单字作为构成文本的基本单位。
五、具体NLP任务上的fine-tune
在具体的NLP任务上,BERT模型的输入输出会有细微的差别。
1)文本分类任务
单文本分类任务:对于文本分类任务,BERT模型在文本前插入一个[CLS]符号,并将该符号对应的输出向量作为整篇文本的语义表示,用于文本分类,如下图所示。可以理解为:与文本中已有的其它字/词相比,这个无明显语义信息的符号会更“公平”地融合文本中各个字/词的语义信息。
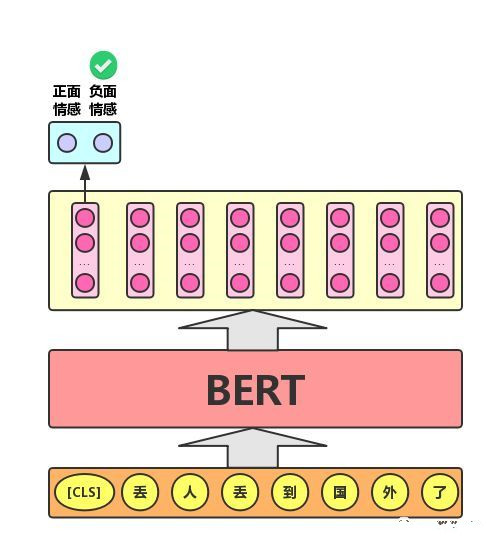
2)语句对分类任务
语句对分类任务:该任务的实际应用场景包括:问答(判断一个问题与一个答案是否匹配)、语句匹配(两句话是否表达同一个意思)等。对于该任务,BERT模型除了添加[CLS]符号并将对应的输出作为文本的语义表示,还对输入的两句话用一个[SEP]符号作分割,并分别对两句话附加两个不同的文本向量以作区分,如下图所示:
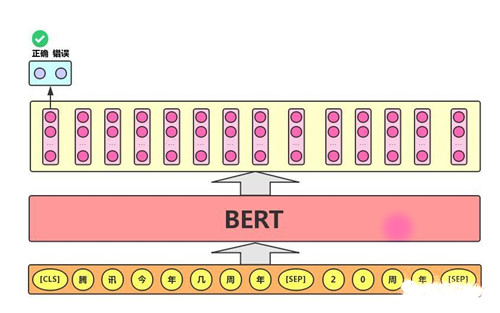
3)序列标注任务
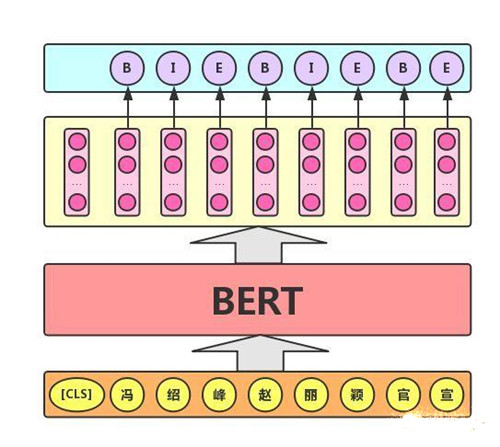
该任务的实际应用场景包括:中文分词&新词发现(标注每个字是词的首字、中间字或末字)、答案抽取(答案的起止位置)等。对于该任务,BERT模型利用文本中每个字对应的输出向量对该字进行标注,如下图所示(B、I、E分别表示一个词的第一个字、中间字和最后一个字)。
参考:
https://cloud.tencent.com/developer/article/1389555
作者:腾讯Bugly
图示详解BERT模型的输入与输出的更多相关文章
- IntelliJ IDEA 快捷键说明大全(中英对照、带图示详解)
因为觉得网络上的 idea 快捷键不够详尽,所以特别编写了此篇文章,方便大家使用 idea O(∩_∩)O~ 其中的英文说明来自于 idea 的官网资料,中文说明主要来自于自己的领会和理解,英文说明只 ...
- 广告行业中那些趣事系列8:详解BERT中分类器源码
最新最全的文章请关注我的微信公众号:数据拾光者. 摘要:BERT是近几年NLP领域中具有里程碑意义的存在.因为效果好和应用范围广所以被广泛应用于科学研究和工程项目中.广告系列中前几篇文章有从理论的方面 ...
- 详解Linux中的cat文本输出命令用法
作系统 > LINUX > 详解Linux中的cat文本输出命令用法 Linux命令手册 发布时间:2016-01-14 14:14:35 作者:张映 我要评论 这篇 ...
- 详解Transformer模型(Atention is all you need)
1 概述 在介绍Transformer模型之前,先来回顾Encoder-Decoder中的Attention.其实质上就是Encoder中隐层输出的加权和,公式如下: 将Attention机制从Enc ...
- HTTP协议图示详解
一.概念 协议是指计算机通信网络中两台计算机之间进行通信所必须共同遵守的规定或规则,超文本传输协议(HTTP)是一种通信协议,它允许将超文本标记语言(HTML)文档从Web服务器传送到客户端的浏览器. ...
- JMeter学习-023-JMeter 命令行(非GUI)模式详解(一)-执行、输出结果及日志、简单分布执行脚本
前文 讲述了JMeter分布式运行脚本,以更好的达到预设的性能测试(并发)场景.同时,在前文的第一章节中也提到了 JMeter 命令行(非GUI)模式,那么此文就继续前文,针对 JMeter 的命令行 ...
- 详解SVM模型——核函数是怎么回事
大家好,欢迎大家阅读周二机器学习专题,今天的这篇文章依然会讲SVM模型. 也许大家可能已经看腻了SVM模型了,觉得我是不是写不出新花样来,翻来覆去地炒冷饭.实际上也的确没什么新花样了,不出意外的话这是 ...
- 03.Django的MTV开发模式详解和模型关系构建
ORM:对象关系映射 一:MTV开发模式把数据存取逻辑.业务逻辑和表现逻辑组合在一起的概念有时被称为软件架构的 Model-View-Controller(MVC)模式. 在这个模式中,Model 代 ...
- 详解从浏览器地址栏输入URL到页面显示的步骤
版本1(基础版本) 步骤1:浏览器根据请求的 URL 交给 DNS 域名解析,找到真实 IP ,向服务器发起请求: 步骤2:服务器交给后台处理完成后返回数据,浏览器接收⽂件( HTML.JS.CSS ...
随机推荐
- BitTorrent协议与MagNet协议原理【转】
转自:https://blog.csdn.net/u012785382/article/details/70674875 版权声明:本文为博主原创文章,未经博主允许不得转载. https://blog ...
- lua 的 cjson 安装,使用
1. 背景: 虚拟机安装的luajit 没有 cjson 库,就不能对 table 进行 编码操作,手动安装一个. 2. 安装: cjson下载地址:http://www.kyne.com.au/~ ...
- torchline:让Pytorch使用的更加顺滑
torchline地址:https://github.com/marsggbo/torchline 相信大家平时在使用Pytorch搭建网络时,多少还是会觉得繁琐,因为我们需要搭建数据读取,模型,训练 ...
- ssh登录缓慢,输入账户密码等待时间长
vim /etc/ssh/sshd_config #取消ssh的反向dns解析 UseDNS no #关闭ssh的gssapi认证 GSSAPIAuthentication no #排查是否日志文件过 ...
- web-忘记密码了
题目 随便提交一个数据 点击确定依旧跳转到原来的网页,下面网页依旧跳转到原来的网页 http://ctf5.shiyanbar.com/10/upload/step1.php/step2.php?em ...
- Maven仓库与坐标(五)
一.Maven仓库 存放依赖的一个位置/文件夹/仓库,分为以下几种: 本地仓库 中央仓库 远程仓库 1. 本地仓库 第一次执行maven命令时被创建,maven运行时需要的构件都从本地仓库获取,本地仓 ...
- 新手Java在华为的几点建议?
随着互联网时代的飞速发展,越来越多的人投身于软件开发行业,大家都称他们为程序员,或者码农. 这些程序员的水平也是参差不齐的,有些人从比较好的学校毕业,水平却一般般:也有些人从一般搬的学校毕业,但是水平 ...
- centos7安装docker记录+命令补全
原本用centos6.6部署项目环境,突然想装docker ,使用uname -r 发现内核版本太低,更新内核完后重启起不来了~~~~~,还是用回7吧 21 yum -y install gcc 22 ...
- ESA2GJK1DH1K升级篇: 快速的移植升级程序到自己的项目(BootLoader程序制作)
前言 此代码兼容STM32F103全系列 为避免添加上升级程序造成内存不足,请使用128KB Flash及其以上的型号 这篇文章是为了能够让大家快速移植我的升级模板程序到自己的项目 BootLoade ...
- [Taro] Taro 环境安装 (一)
Taro 环境安装 Taro是一个前端小程序框架,通过这个框架写一套代码,再通过 Taro 的编译工具,就可以将源代码分别编译出可以在不同端(微信/百度/支付宝/字节跳动小程序.H5.React-N ...