torch_09_GAN
1.生成对抗网络
让两个网络相互竞争,通过生成网络来生成假的数据,对抗网络通过判别器判别真伪,最后希望生成网络生成的数据能够以假乱真骗过判别器
2.生成模型
就是‘生成’样本和‘真实’的样本尽可能的相似。生成模型的两个主要功能是学习一个概率分布Pmodel(X)和生成数据。
在生成对抗网络中,不再是将图片输入编码器得到隐含向量然后生成图片,而是随机初始化一个隐含向量,根据变分自动编码器的特点,初始化一个正态分布的隐含向量,通过类似解码的过程,将它映射到一个更高的维度,最后生成一个与输入数据相似的数据,这就是假的数据。生成对抗网络过程通过计算对抗过程来计算损失函数。
2.1 自动编码器(AutoEncoder)
编码器的结构:
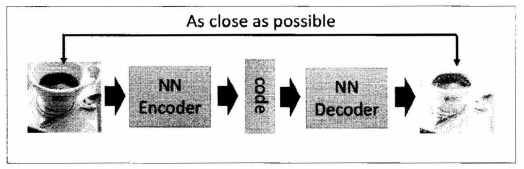
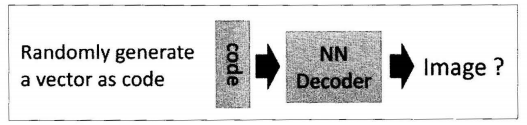
第一部分是编码器(Encoder),第二部分是解码器(Decoder),编码器和解码器都可以是任意的模型,通常使用神经网络模型作为编码器和解码器。输入的数据经过神经网络降维到一个编码(code),接着又通过另外一个神经网络去解码得到一个与输入数据一模一样的生成数据,然后通过比较这两个数据,最小化™之间的差异来训练这个网络中编码器和解码器的参数。当这个过程训练完之后,拿出这个解码器,随机传入一个编码,通过解码器能够生成一个和原数据差不多的数据。如下图:
2.2 变分自动编码器(Variational AutoEncoder-- VAE)
结构与自动编码器是相似的,也是由编码器和解码器构成的。
在自动编码器中只能输入一张图片,才能产生隐含向量,不能输入一个随机向量,虽然自动编码器能输出与原图很接近的图片,但是缺乏多样性。在变分自动编码器中,只需要在编码过程给它增加一些限制,迫使它生成的隐含向量能够粗略的遵循一个标准正态分布,这就是它与一般的自动编码器最大的不同。
在变分自动编码器中,只需要给它一个标准正态分布的随机向量,利用解码器就可以生成一张图片。不需要先给它一张原始图片。
模型的准确率:解码器生成的图片与原图片的相似程度。
loss的计算:解码器生成图片与原始图片的均方误差 + 隐含向量与标准正态分布之间的差异 (使用的是KL divergence)
在变分编码器中,使用了一个技巧-重新参数化,来解决KL divergence的计算问题
不再每次生成一个隐含向量,而是生成两个向量:一个表示均值,一个表示标准差,然后通过这两个统计量合成隐含向量,用一个标准正态分布先乘上标准差再加上均值。这里默认编码之后的隐含向量是服从一个正态分布的,这个时候要让均值尽可能接近0,
3.对抗过程
对抗过程是一个判断真假的判别器,相当于一个二分类问题。输入一张图片,如果是真的图片希望判别器输出为1,假的图片输出为0,这与图片的标签没有关系。
4.训练过程
先优化判别器,将真的图片和假的图片都输入给判别模型,让判别器计算损失,不断优化,让判别器能够区分出真的图片和假的图片,真的图片为1,假的为0.
然后优化生成器。固定判别器的参数,不断优化生成器,使生成器的生成的结果传递给判别器之后,尽可能的接近1,调整损失函数。
5.判别模型训练
开始需要自己创建label,真实的数据时1,生成的假的数据时0,然后将真实的数据输入给判别器,计算loss值,将假的数据输入判别器得到loss,将这两个loss加起来得到总的loss,然后反向传播更新参数能够得到一个优化好的判别器。
6.生成器训练
一个随机隐含向量通过生成网络得到了一个假的数据,然后希望假的数据经过判别模型尽可能和真实label接近,通过g_loss = criterion(output,real_label)实现,然后反向传播去优化生成器的参数,在这个过程中,判别器的参数不再发生变化,否则生成器永远无法骗过优化的判别器。
DCGAN,使用celeba数据集
训练过程:
第一批次(batch-size):
1.将随机生成的128*100*1*1给G网络,生成128*3*64*64的图片
2.将这些假图片给D网络,计算损失,并且把一批真图片(128*3*64*64,每次从Dataloder迭代器中拿出来一批作为真图片 )计算损失,两者损失相加,进行梯度优化
3.计算生成器损失,计算D(G(X)),把128张假图片,放入判别器,更新G的梯度,假图片标签为1
4.这就完成了一次一批(128张)的生成和判别
第二批次(batch-size):
1.又取出来一批真数据,假数据(重新生成一批假数据放入G网络中,生成128张假数据),放入D网络,真数据标签为1,假数据标签为0,放在一起计算损失,进行优化
2.然后把这些假数据放入D网络中,计算损失更新G网络的参数权重,注意的一点是,此时假数据的标签为1
3.规定训练到一定次数时,随机生成64*100*1*1的向量生成64张图片来查看生成假图片的效果
......
训练5个epochs
torch_09_GAN的更多相关文章
随机推荐
- 【C#夯实】我与接口二三事:IEnumerable、IQueryable 与 LINQ
序 学生时期,有过小组作业,当时分工一人做那么两三个页面,然而在前端差不多的时候,我和另一个同学发生了争执.当时用的是简单的三层架构(DLL.BLL.UI),我个人觉得各写各的吧,到时候合并,而他觉得 ...
- JavaScript的闭包特性如何给循环中的对象添加事件(一)
初学者经常碰到的,即获取HTML元素集合,循环给元素添加事件.在事件响应函数中(event handler)获取对应的索引.但每次获取的都是最后一次循环的索引.原因是初学者并未理解JavaScript ...
- pymysql 的简单使用
一.环境 Windows 7 x64 python 3.7.1 pymysql 0.9.3 mysql5.6.43 二.pymysql的简单使用 1.准备数据库demo_temp c ...
- Java面向对象——相关基本定义
Java面向对象——相关基本定义 摘要:本文简单介绍了面向对象的编程方式,以及与之有关的一些基本定义. 面向对象 什么是面向对象 面向对象编程是一种对现实世界建立计算机模型的一种编程方法.简称OOP( ...
- 腾讯WeTest亮相—腾讯全球数字生态大会现场
2019年5月21-23日腾讯全球数字生态大会在云南昆明滇池国际会展中心顺利召开. 此次大会上万人到场参与,大会由主峰会.分论坛.数字生态专题展会以及腾讯数字生态人物颁奖盛典四大板块构成.作为腾讯战略 ...
- PowerShell美化
转载自Powershell 美化 --oh-my-posh,作者Zvonimir. PowerShell默认的主题太丑了,用过OhMyZsh之后是无法忍受这种丑陋的,幸好PowerShell有对应的O ...
- 【转载】CMake 两种变量原理
原文地址:https://cslam.cn/archives/c9f565b5.html 摘要: 本文记录一下 CMake 变量的定义.原理及其使用.CMake 变量包含 Normal Variabl ...
- C++学习视频和资料
我在学习c++时,比较迷茫,而且当时学完c++primer时不知道该学习什么, 犹豫了好久,最后找到了一些关于c++学习路线的视频,包含源代码,我感觉还不错,分享给大家. 下载地址 https://d ...
- LVS(二):四种工作模型
面试的时候必问这个四种工作模式,因为这几乎是企业里面必用的内容,所以一定要将其理解通透. 一.lvs-nat模式 二.LVS-DR模式(默认) 三.LVS-tun模式 四.LVS-fullnat模式 ...
- 201871010106-丁宣元 《面向对象程序设计(java)》第十五周学习总结
201871010106-丁宣元 <面向对象程序设计(java)>第十五周学习总结 正文开头: 项目 内容 这个作业属于哪个课程 https://home.cnblogs.com/u/nw ...