jmeter 参数化大数据取唯一值方式
jmeter 参数化大数据取唯一值方式
一、用时间函数:
# 以13位的时间戳作为 userID
nowTime = lambda: int(round(time.time() * 1000))
userID = str(nowTime())
print("userID--------" + userID)
输出结果:
userID--------1574172135349
每次输出的结果都不一样:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import time nowTime = lambda: int(round(time.time() * 1000))
userID = str(nowTime()) for i in range(0,10):
print("userID--------" + userID) 输出结果:
userID--------1574172365139
userID--------1574172365139
userID--------1574172365139
userID--------1574172365139
userID--------1574172365139
userID--------1574172365139
userID--------1574172365139
userID--------1574172365139
userID--------1574172365139
userID--------1574172365139
二、用UUID:
3F2504E0-4F89-11D3-9A0C-0305E82C3301
如下是分析在jmeter中如何使用:
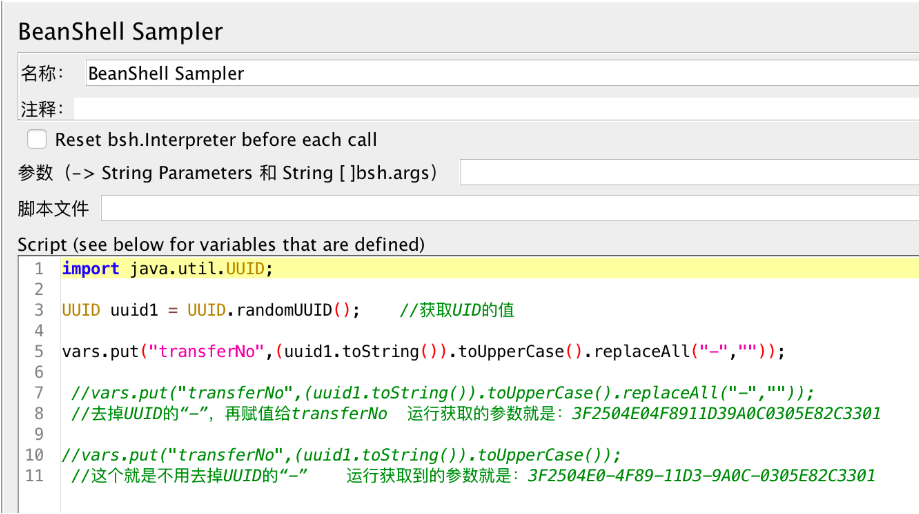
在BeanShell Sampler编写UUID的代码:
import java.util.UUID; UUID uuid1 = UUID.randomUUID(); //获取UID的值 vars.put("transferNo",(uuid1.toString()).toUpperCase().replaceAll("-","")); //去掉UUID的“-”,再赋值给transferNo 运行获取的参数就是:3F2504E04F8911D39A0C0305E82C3301
//vars.put("transferNo",(uuid1.toString()).toUpperCase());
//这个就是不用去掉UUID的“-” 运行获取到的参数就是:3F2504E0-4F89-11D3-9A0C-0305E82C3301
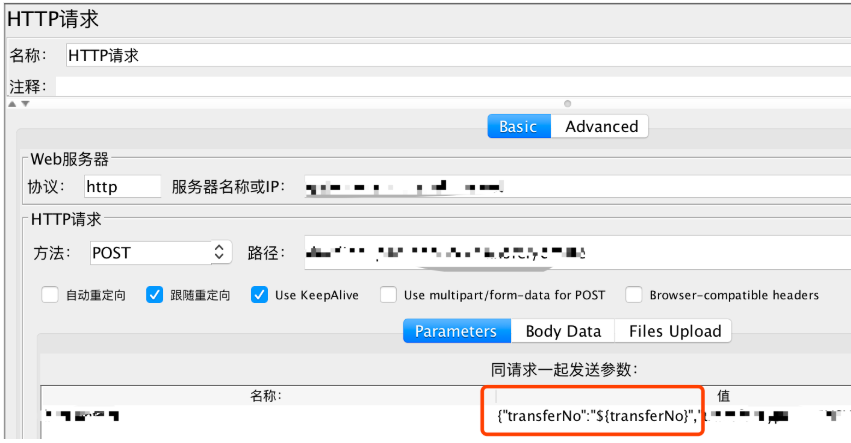
2,新建一个http请求;
三,直接写代码for循环生成大量唯一不重复的测试数据
#!/usr/bin/env python
# -*- coding: utf-8 -*-
for i in range(1000000, 9000000):
k = i + 1
q = '2018' + str(k)
print('q ========= ' + q) 输出结果:
.........
q ========= 20181145532
q ========= 20181145533
q ========= 20181145534
q ========= 20181145535
q ========= 20181145536
q ========= 20181145537
.........
最后用txt或者excel将生成的大量数据导入jmeter进行并发请求。
jmeter 参数化大数据取唯一值方式的更多相关文章
- LoadRunner参数化之数据取值和更新方式
其实看LR已经很久了,每次看到参数化的取值更新时,都没有看透,了解个大概就为止了,也确实挺搞脑子的. 现在理解下来 分成2部分 取值方式 Select next row 如何从数据列表中取值 Seq ...
- jmeter参数化读取数据进行多次运行
jmeter参数化数据,可以使用csv,还可以使用数据库的方式 1.使用csv读取数据 在线程组中,配置原件中,选择csv data set config 1.本地创建了16个数据,存为test.tx ...
- MATLAB 大数据剔除坏值
在用MATLAB进行数据分析的时候,坏点对正确结果的影响比较大, 因此,我么需要剔除野点,对于坏值的剔除,我们 利用 3σ准则 剔除无效数据: 3σ准则又称为拉依达准则,它是先假设一组检测数据只含有 ...
- TestNG参数化测试-数据提供程序 @DataProvider方式
在 testng.xml 中指定参数可能会有如下的不足: 1.如果你压根不用 testng.xml. 2.你需要传递复杂的参数,或者从Java中创建参数(复杂对象,对象从属性文件或者数据库中读取的et ...
- Js数组去重复取唯一值
function isBigEnough(element) { return element >= 10; } var filtered = [12, 5, 8, 130, 44].filter ...
- java大数据批量处理实现方式
1. 各批量方式对比 Mybatis与JDBC批量插入MySQL数据库性能测试及解决方案 2. 原理解析 1)MySql PreparedStatement executeBatch过慢问题 3. 工 ...
- Loadrunner中参数化取值方式分析
Loadrunner中参数化取值依赖两个维度: 1.取值顺序分为“顺序”“随机”“唯一”. select next row:Sequential , Random,unique 2.更新值时分为 ...
- Spark大数据针对性问题。
1.海量日志数据,提取出某日访问百度次数最多的那个IP. 解决方案:首先是将这一天,并且是访问百度的日志中的IP取出来,逐个写入到一个大文件中.注意到IP是32位的,最多有个2^32个IP.同样可以采 ...
- 免费大数据搜索引擎 xunsearch 实践
以前在IBM做后端开发时,也接触过关于缓存技术,当时给了n多文档来学习,后面由于其他紧急的项目,一直没有着手去仔细研究这个技术,即时后来做Commerce的时候,后台用了n多缓存技术,需要build ...
随机推荐
- MongoDB 基本概念
MongoDB和关系型数据库的对应关系 关系数据库 MongoDB 数据库 database 数据库 database 表格 table 集合 collection 行 row 文档 ...
- Linux 磁盘配额(XFS & EXT4)
若是在Linux中搭建了FTP服务器,为了安全性,就要考虑磁盘配额,以防服务器磁盘空间被恶意占满. 磁盘配额概述 1.作用范围:只在指定的分区有效. 2.限制对象:主要针对用户.组进行限制,对组账号限 ...
- 查看zookeeper版本
命令 echo stat|nc localhost 2181 zookeeper@kafka-zookeeper-0:/$ echo stat|nc localhost 2181 Zookeeper ...
- Codeforces Round #598 (Div. 3)- E. Yet Another Division Into Teams - 动态规划
Codeforces Round #598 (Div. 3)- E. Yet Another Division Into Teams - 动态规划 [Problem Description] 给你\( ...
- QA流程
一.测试人员的介入时间 1.当产品经理与业务人员制定需求的时候,测试人员不宜介入: 2.当下一期的需求原型出来以后,这个时候就进入了需求评审.需求分析阶段,此时,测试人员应该介入: 3.当开发人员在编 ...
- 划分土地(how many pieces of land)
题目描述: 给一个椭圆,上面有n个点,两两连接这n个点,得到的线段能把椭圆分为几个区域? 思路: 首先想想,n个点在椭圆边缘,每两个点两两连接有\(C^2_n\)条线段,这些线段交于很多点,求这些线段 ...
- django 进行语言的国际化及在后台进行中英文切换
项目的部署地为: 中国大陆与美国东海岸, 两个地区的服务器数据不进行同步, 中国地区的服务器页面展示中文, 美国地区的服务器页面展示成英文, 项目后台使用python编程语言进行开发, 并结合djan ...
- js数组操作 求最大值,最小值,正序、倒叙大小值排序,去重复
var arr = [1,5,2,56,12,34,21,3,5] Math.min.apply({},arr) Math.max.apply({},arr) arr.sort((m,n)=>m ...
- junit3和junit4的区别总结
先来看一个例子: 先用junit3来写测试用例,如下: junit3测试结果: 从上面可看出: 1.junit3必须要继承TestCase类 2.每次执行一个测试用例前,junit3执行一遍setup ...
- MySQL 开启远程链接(localhost 以外的主机)
1.在连接服务器后,操作mysql系统数据库 命令为: mysql -u root -p use mysql: 查询用户表命令:select User,authentication_string, ...