使用python脚本批量设置nginx站点的rewrite规则
一般情况下,配置rewrite重写规则使用shell脚本即可:
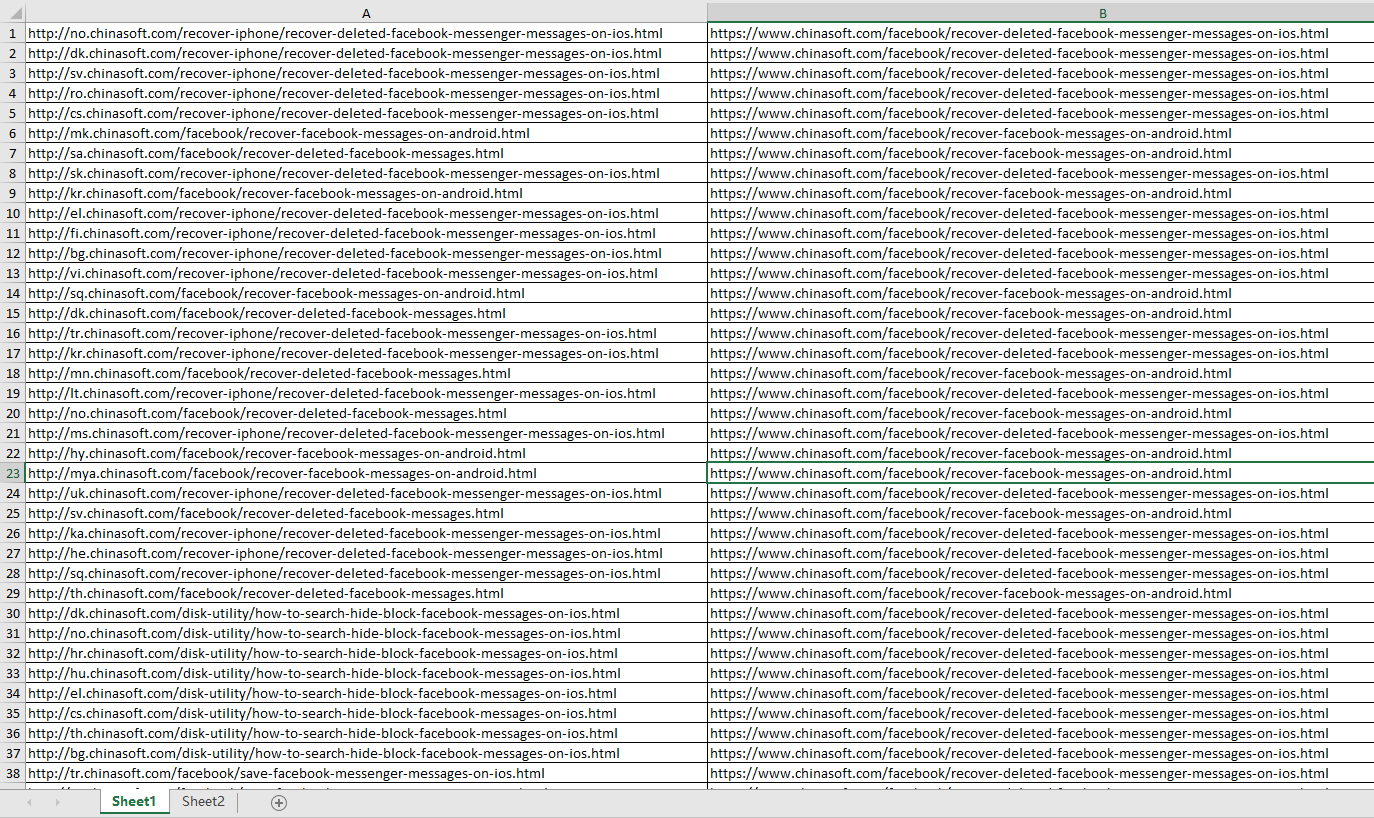
把url拼凑成1,2文件中中的格式,运行 chongxie.sh 即可生成我们需要的rewrite规则
[root@web01:/opt/rewrite]# more
^/facebook/recover-facebook-messages-on-android.html [root@web01:/opt/rewrite]# more
https://www.chinasoft.com/facebook/recover-facebook-messages-on-android.html [root@web01:/opt/rewrite]# more chongxie.sh
#!/bin/bash
> ./temp;
cat -n >;cat -n >;join -o 1.2,2.2 >301temp; # 按行读取拼凑的内容,并且拼凑成我们需要的规则写入到temp中
while read line
do
a=`echo $line|awk '{print "if (\$request_uri ~ " $1 ") { rewrite ^ " $2 " permanent; }"}'`
echo $a >> temp;
done < 301temp
sed -i 's/.html\$/.html/' temp;sed -i 's/.php\$/.php/' temp;
[root@web01:/opt/rewrite]# more temp
if ($request_uri ~ ^/facebook/recover-facebook-messages-on-android.html) { rewrite ^ https://www.chinasoft.com/facebook/recover-facebook-messages-on-android.html permanent; }
如下配置:
rewrite规则写在 rewrite_web.d 目录中
# cat /usr/local/nginx/conf/web.d/no.chinasoft.com.conf
server {
listen ;
server_name no.chinasoft.com ;
access_log /data/www/logs/nginx_log/access/no.chinasoft.com_access.log main ;
error_log /data/www/logs/nginx_log/error/no.chinasoft.com_error.log ;
root /data/www/web/no.chinasoft.com/httpdocs ;
index index.html index.shtml index.php ;
include rewrite_web.d/no.chinasoft.com.conf ;
error_page /.html; location ~ \.php$ {
proxy_pass http://php_pool;
include proxy_params;
} location / {
include proxy_params;
if (!-d $request_filename){
set $flag $flag;
}
if (!-f $request_filename){
set $flag $flag;
}
if ($flag = ""){
proxy_pass http://php_pool;
} } }
python脚本:
excel的插件下载地址:
https://files.pythonhosted.org/packages/b0/16/63576a1a001752e34bf8ea62e367997530dc553b689356b9879339cf45a4/xlrd-1.2.0-py2.py3-none-any.whl
pip install xlrd-1.2.0-py2.py3-none-any.whl 安装
# coding:utf-8
# 读取excel的每一行,获取host信息列表
import xlrd
import os
import sys
import datetime workbook = xlrd.open_workbook('web01.xlsx')
for row in xrange(workbook.sheets()[0].nrows):
src_url=workbook.sheets()[0].cell(row,0).value
dst_url=workbook.sheets()[0].cell(row,1).value # 获取原始域名和path
from urlparse import urlparse
parsed_uri = urlparse(src_url)
domain = '{src_url.netloc}'.format(src_url=parsed_uri)
src_path = parsed_uri.path rewrite_url = "if ($request_uri ~ ^" + src_path +") { rewrite ^ " + dst_url + " permanent; }" time = datetime.datetime.now().strftime('%Y%m%d')
today = "# "+time # 判断rewrite.d文件是否存在,存在就写入
dst_file = "/usr/local/nginx/conf/rewrite_web.d/"+domain+".conf"
if os.path.isfile(dst_file):
# cmd_addtime = 'echo ' + today + '>>' + dst_file
# print cmd_addtime
# res1 = os.system(cmd_addtime)
# if res1 != 0:
# print 'write today fail'
# cmd_addurl = 'echo ' + rewrite_url + '>>' + dst_file
# print cmd_addurl # res2 = os.system(cmd_addurl)
# if res2 != 0:
# print 'write url %s failed' % rewrite_url
with open(dst_file, mode='a+') as f:
f.write('\n')
f.write(today)
f.write('\n')
f.write(rewrite_url)
f.write('\n')
else:
print "file %s is not exists" % dst_file
excel的规则,要编辑太多文件内容了,如果手动会浪费大量时间,于是写成了python脚本
注意,源url需要带 http://
使用python脚本批量设置nginx站点的rewrite规则的更多相关文章
- python脚本批量生成数据
在平时的工作中,经常会遇到造数据,特别是性能测试的时候更是需要大量的数据.如果一条条的插入数据库或者一条条的创建数据,效率未免有点低.如何快速的造大量的测试数据呢?在不熟悉存储过程的情况下,今天给大家 ...
- 使用Python脚本批量裁切栅格
对栅格的裁切,我们通常使用裁切(数据管理-栅格-栅格处理)或按掩膜提取(空间分析-提取分析)来裁切,裁切的矢量要素通常是一个要素图层或Shape文件.如果要进行批量处理,可以使用ToolBox中的批量 ...
- 在linux系统中如何通过shell脚本批量设置redis键值对
业务逻辑:批量设置redis中手机号的验证码为888888: 准备shell脚本如下:将18888888100~18888888110的手机号验证码设置为888888: #!/bin/bash ;i& ...
- 关于python脚本头部设置#!/usr/bin/python
今天又是贼几把菜的一天0.0 读别人程序的时候看到在python文件头部设置签名,感觉贼几把酷,自己也试着在文件前段设置了一下. 设置还是蛮简单的,设置过程如图所示. 设置后如图所示: 当然你也可能看 ...
- 在python脚本中设置环境变量,并运行相关应用
1. 问题 在自动化应用的时候 ,有时候环境变量与运行需要不一致.这时候有两种选择: 改变节点环境变量,使得其和运行需求保持一致: 在自动化脚本中设置环境变量,其范围只在脚本运行环境中有效. 显然,当 ...
- python redis 批量设置过期key
在使用 Redis.Codis 时,我们经常需要做一些批量操作,通过连接数据库批量对 key 进行操作: 关于未过期: 1.常有大批量的key未设置过期,导致内存一直暴增 2.rd需求 扫描出这些ke ...
- 实例讲解Nginx下的rewrite规则
一.正则表达式匹配,其中:* ~ 为区分大小写匹配* ~* 为不区分大小写匹配* !~和!~*分别为区分大小写不匹配及不区分大小写不匹配二.文件及目录匹配,其中:* -f和!-f用来判断是否存在文件* ...
- 实例讲解Nginx下的rewrite规则(转)
一.正则表达式匹配,其中:* ~ 为区分大小写匹配* ~* 为不区分大小写匹配* !~和!~*分别为区分大小写不匹配及不区分大小写不匹配二.文件及目录匹配,其中:* -f和!-f用来判断是否存在文件* ...
- 实例讲解Nginx下的rewrite规则 来源:Linux社区
一.正则表达式匹配,其中:* ~ 为区分大小写匹配* ~* 为不区分大小写匹配* !~和!~*分别为区分大小写不匹配及不区分大小写不匹配二.文件及目录匹配,其中:* -f和!-f用来判断是否存在文件* ...
随机推荐
- 解决vant-weapp组件库的example的导入问题
最近在学习小程序,看到了vant-weapp这个组件库,我比较喜欢边看示例边来敲代码.刚好这个组件库下载下来有 example的文件夹.废话不多说,现在来看看怎么在开发工具里面导入吧! 步骤: 1.下 ...
- c#: WebBrowser控件注入js代码的三种方案
聊做备忘. 假设js代码为: string jsCode = @"function showAlert(s) {{ alert('hello, world! ' + s);}}; showA ...
- Httpd服务入门知识-Httpd服务常见配置案例之DSO( Dynamic Shared Object)加载动态模块配置
Httpd服务入门知识-Httpd服务常见配置案例之DSO( Dynamic Shared Object)加载动态模块配置 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.加载动 ...
- M × N Puzzle
http://poj.org/problem?id=2893 来自逆序对的强大力量 #include<iostream> #include<stdio.h> #include& ...
- 如何显示隐藏的文件在win7系统中
点左下角“开始”菜单,再点击“计算机”. 点击窗口顶部靠左位置的“组织”菜单,选择其中的“文件夹和搜索选项”. 在弹出的窗口里点击切换到“查看”选项卡. 在窗口中部位置下拉滚动条,找到“显示隐藏的 ...
- 2019牛客暑期多校训练营(第九场)B:Quadratic equation (二次剩余求mod意义下二元一次方程)
题意:给定p=1e9+7,A,B. 求一对X,Y,满足(X+Y)%P=A; 且(X*Y)%P=B: 思路:即,X^2-BX+CΞ0; 那么X=[B+-sqrt(B^2-4C)]/2: 全部部分都要 ...
- 开启了wpjam以后网站语言不能设置英文的解决方法
一位网友问ytkah开启了wpjam以后网站语言不能设置英文了这是什么情况?选择English保存以后还是简体中文,禁用插件再设置语言是可以设为English,好几个站点都是这样 其实很简单,只要把这 ...
- 别名alias永久生效别名alias永久生效;虚拟机的NAT模式,进行静态IP配置,并A、B的实现免密访问
别名alias永久生效 1.打开cd /etc/profile.d 目录 新建文件my_alias.sh 2.my_alias.sh里面添加 alias p=’poweroff -h’ alias r ...
- Objective-C Classes Are also Objects
https://developer.apple.com/library/content/documentation/Cocoa/Conceptual/ProgrammingWithObjectiveC ...
- vue cli 常见问题汇总
以下是本人在用vue cli 开发项目里遇到的最基本的问题及解决方案汇总.没啥很多技术性的东西,各位看个乐呵就行~ 1.vue-cli 创建的项目各文件夹的含义 注意:通过vue-cli 4 创建的项 ...