原创:协同过滤之spark FP-Growth树应用示例
上一篇博客中,详细介绍了UserCF和ItemCF,ItemCF,就是通过用户的历史兴趣,把两个物品关联起来,这两个物品,可以有很高的相似度,也可以没有联系,比如经典的沃尔玛
的啤酒尿布案例。通过ItemCF,能能够真正实现个性化推荐,最大限度地挖掘用户的需求。在购物网站和电子商务,图书中,应用特别广泛。需要维护物品相似度表。spark的MLlib中,
有FP-Growth树挖掘物品的相关度,应用很多。关于FP-Growth树的介绍,有很多博文,不详细说了。他相对于Apriori算法,做了很大的改进,大大降低了时间复杂度。构建FP-Growth
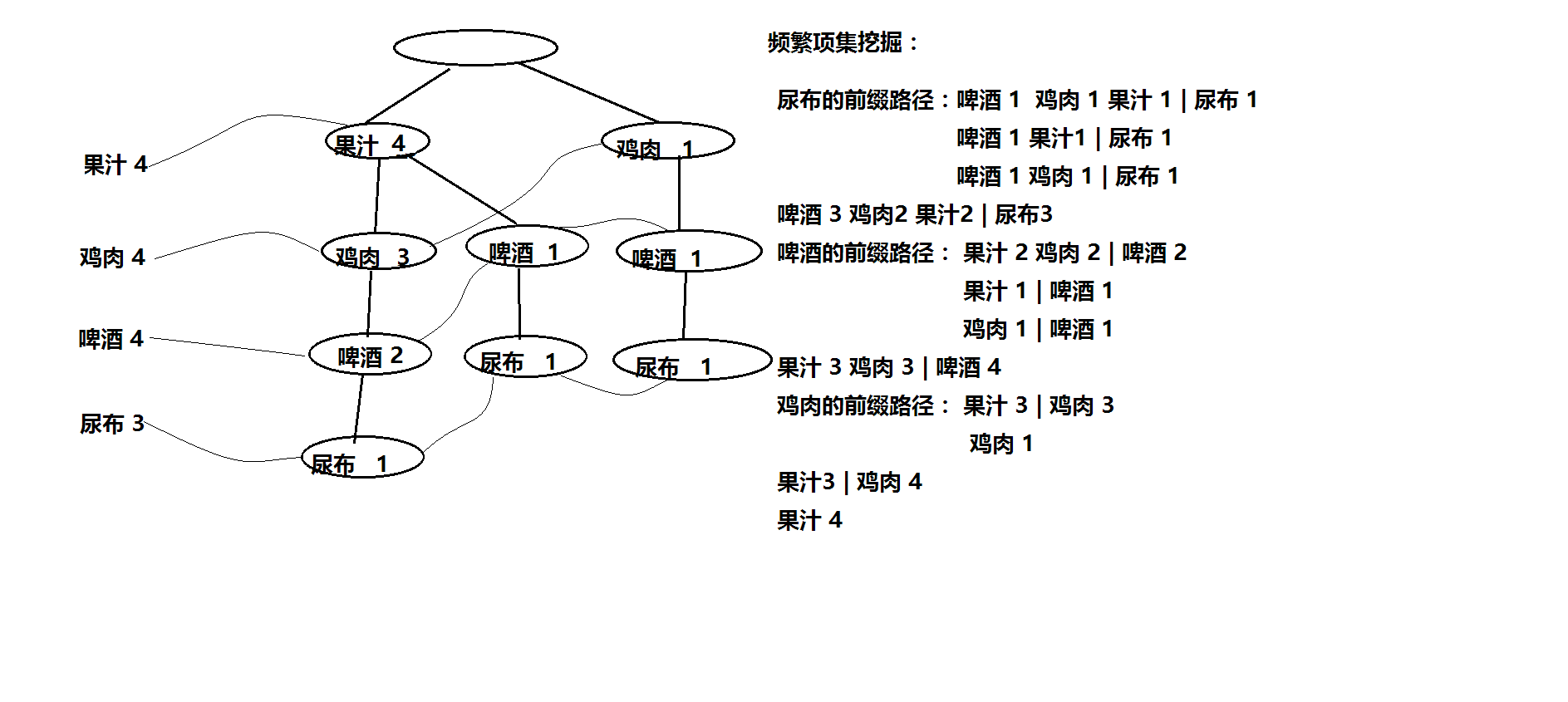
树的过程,还需要维护一个头表(链表),用来存储频繁项集的前缀路径。下面的一张图,可以说明:
从FP-Growth增长树中挖掘出频繁项集后,比如:啤酒3 鸡肉2 果汁2 | 尿布3,设置了minConf(最小置信度)后,当用户(或者是一个新用户)购买了尿布时,可以给他推荐啤酒,鸡肉。下面的代码,说明了这一原理:
package com.txq.spark.test /**
* Created by ACER on 2016/11/22.
*/
case class ItemFreq(val item:String,val freq:Double) { } package com.txq.spark.test import java.util.concurrent.ConcurrentHashMap
import org.apache.spark.mllib.fpm.FPGrowth
import org.apache.spark.{SparkConf, SparkContext}
import scala.collection._ /**
* Created by ACER on 2016/11/20.
*/
object Test1 {
System.setProperty("hadoop.home.dir", "D://hadoop-2.6.2");
val conf = new SparkConf().setMaster("local").setAppName("testFP-Growth");
val sc = new SparkContext(conf); var freqMap = new ConcurrentHashMap[mutable.ArrayBuffer[String],mutable.ArrayBuffer[ItemFreq]]();//捆绑推销(key值为用户购买的历史商品)
val items = new ConcurrentHashMap[Long,mutable.ArrayBuffer[String]]()//用户购买的历史商品
val minSupport = 0.5//最小支持度
val minConf = 0.75//最小置信度
var freq = 0L//用户历史商品出现的次数
var li = mutable.ArrayBuffer[ItemFreq]()
def main(args: Array[String]): Unit = {
//1.加载过去一段时间,大量用户购买的商品,数据源为商品列表,训练FP-Growth模型
val data = sc.textFile("D://fp.txt").map(_.split(" ")).cache()
val count = data.count()
val fpg = new FPGrowth().setMinSupport(minSupport).setNumPartitions(3)
val model = fpg.run(data) //2.输出所有频繁项集
val result = model.freqItemsets.filter(_.items.size >= 1)
result.foreach(f => println(f.items.mkString(" ")+"->"+f.freq)) //3.获取用户id,并得到历史商品
val userId = args(0).toLong
var bucket:mutable.ArrayBuffer[String] = items.get(userId.toLong)
if(bucket == null){
bucket = new mutable.ArrayBuffer[String]()
for(i <- 1 until args.length){
bucket += (args(i))
}
}
items.put(userId,bucket)//收集用户购买的历史商品
for(item <- result){
//4.在模型中找出与用户的历史商品相符合的频繁项集,得到频率
if(item.items.mkString == items.get(userId).mkString){
freq = item.freq
}
}
println("历史商品出现的次数:" + freq)//调试信息(输出用户历史商品的支持度)
//5.根据历史商品,找出置信度相对高的频繁项,推荐给用户 for(f <- result){
if(f.items.mkString.contains(items.get(userId).mkString) && f.items.size > items.get(userId).size) {
val conf:Double = f.freq.toDouble / freq.toDouble
if(conf >= minConf) {
//找出所有置信度大于minConf的项
var item = f.items
for (i <- 0 until items.get(userId).size) {
item = item.filter(_ != items.get(userId)(i)) //过滤掉用户历史商品,剩下的为推荐的商品
}
for (str <- item) {
li += ItemFreq(str, conf)
}
}
}
}
freqMap.put(items.get(userId),li);
println("推荐的商品为:")
freqMap.get(items.get(userId)).foreach(f =>println(f.item + "->" + f.freq))
}
}
挖掘出的频繁项集:
尿布->3
尿布 啤酒->3 果汁->4 鸡肉->4
鸡肉 果汁->3 啤酒->4
啤酒 鸡肉->3
啤酒 果汁->3 历史商品出现的次数:4 推荐的商品为:
鸡肉->0.75
啤酒->0.75 测试文件为:
果汁 鸡肉
鸡肉 啤酒 鸡蛋 尿布
果汁 啤酒 尿布 可乐
果汁 鸡肉 啤酒 尿布
鸡肉 果汁 啤酒 可乐
原创:协同过滤之spark FP-Growth树应用示例的更多相关文章
- 推荐系统-协同过滤在Spark中的实现
作者:vivo 互联网服务器团队-Tang Shutao 现如今推荐无处不在,例如抖音.淘宝.京东App均能见到推荐系统的身影,其背后涉及许多的技术.本文以经典的协同过滤为切入点,重点介绍了被工业界广 ...
- 原创:协同过滤之ALS
推荐系统的算法,在上个世纪90年代成型,最早应用于UserCF,基于用户的协同过滤算法,标志着推荐系统的形成.首先,要明白以下几个理论:①长尾理论②评判推荐系统的指标.之所以需要推荐系统,是要挖掘冷门 ...
- 协同过滤 CF & ALS 及在Spark上的实现
使用Spark进行ALS编程的例子可以看:http://www.cnblogs.com/charlesblc/p/6165201.html ALS:alternating least squares ...
- 【转载】协同过滤 & Spark机器学习实战
因为协同过滤内容比较多,就新开一篇文章啦~~ 聚类和线性回归的实战,可以看:http://www.cnblogs.com/charlesblc/p/6159187.html 协同过滤实战,仍然参考:h ...
- Spark MLlib之协同过滤
原文:http://blog.selfup.cn/1001.html 什么是协同过滤 协同过滤(Collaborative Filtering, 简称CF),wiki上的定义是:简单来说是利用某兴趣相 ...
- Spark机器学习之协同过滤算法
Spark机器学习之协同过滤算法 一).协同过滤 1.1 概念 协同过滤是一种借助"集体计算"的途径.它利用大量已有的用户偏好来估计用户对其未接触过的物品的喜好程度.其内在思想是相 ...
- Spark机器学习(11):协同过滤算法
协同过滤(Collaborative Filtering,CF)算法是一种常用的推荐算法,它的思想就是找出相似的用户或产品,向用户推荐相似的物品,或者把物品推荐给相似的用户.怎样评价用户对商品的偏好? ...
- 协同过滤 spark scala
1 http://www.cnblogs.com/charlesblc/p/6165201.html [转载]协同过滤 & Spark机器学习实战 2 基于Spark构建推荐引擎之一:基于物品 ...
- Spark 基于物品的协同过滤算法实现
J由于 Spark MLlib 中协同过滤算法只提供了基于模型的协同过滤算法,在网上也没有找到有很好的实现,所以尝试自己实现基于物品的协同过滤算法(使用余弦相似度距离) 算法介绍 基于物品的协同过滤算 ...
随机推荐
- sping boot/cloud配置文件 on 读取为true
sping boot/cloud配置文件 on 读取为true 原文地址:https://blog.csdn.net/hb9176070/article/details/82749771 最近在写sp ...
- 软件平台ThinkSNS+软件系统研发日记
NO.1: 实用开源软件安装部署是第一步, ThinkSNS+响应快速安装,易于二开基准,为大家录制了一份宝塔面板安装社交系统ThinkSNS+视频教程,点开观看视频一起吸一吸. 若无法播放,请直接打 ...
- kubernetes第十二章--监控
- 【开发工具】- Myeclipse10.7破解方法
1.下载myeclipse 10,如果没有,可以使用链接:https://pan.baidu.com/s/1l9juqD4ALMuepVL6e5kgjA 密码:kpx6:当然时间久了可能链接失效,如有 ...
- 【开发工具】- 推荐一款好用的文本编辑器[Sublime Text]
作为一个程序员除了IDE外,文本编辑器也是必不可少的一个开发工具.之前一直在用的是NotePad++.EditPlus,这两款编辑器,但是总感觉差点什么,昨天在知乎上看到有人推荐Sublime Tex ...
- 又一个秘密如何让浏览器访问最新的js,css等外部引用
在引用文件末尾加上一个参数,让浏览器知道这个文件跟上一个文件是不同的,让浏览器去服务器重新加载最新的,例如:<script type="text/javascript" sr ...
- 【转载】C#中Convert.ToDouble方法将字符串转换为double类型
在C#编程过程中,可以使用Convert.ToDouble方法将字符串或者其他可转换为数字的对象变量转换为double类型,Convert.ToDouble方法有多个重载方法,最常使用的一个方法将字符 ...
- 【转载】C#中List集合使用GetRange方法获取指定索引范围内的所有值
在C#的List集合中有时候需要获取指定索引位置范围的元素对象来组成一个新的List集合,此时就可使用到List集合的扩展方法GetRange方法,GetRange方法专门用于获取List集合指定范围 ...
- 反序列化之PHP原生类的利用
目录 基础知识 __call SoapClient __toString Error Exception 实例化任意类 正文 文章围绕着一个问题,如果在代码审计中有反序列化点,但是在原本的代码中找不到 ...
- 【DATAGUARD】物理dg的switchover切换(五)
[DATAGUARD]物理dg的switchover切换(五) 一.1 BLOG文档结构图 一.2 前言部分 一.2.1 导读 各位技术爱好者,看完本文后,你可以掌握如下的技能,也可以学到一些其 ...