Spark高级函数应用【combineByKey、transform】
一.combineByKey算子简介
功能:实现分组自定义求和及计数。
特点:用于处理(key,value)类型的数据。
实现步骤:
1.对要处理的数据进行初始化,以及一些转化操作
2.检测key是否是首次处理,首次处理则添加,否则则进行分区内合并【根据自定义逻辑】
3.分组合并,返回结果
二.combineByKey算子代码实战
package big.data.analyse.scala.arithmetic import org.apache.spark.sql.SparkSession
/**
* Created by zhen on 2019/9/7.
*/
object CombineByKey {
def main (args: Array[String]) {
val spark = SparkSession.builder().appName("CombineByKey").master("local[2]").getOrCreate()
val sc = spark.sparkContext
sc.setLogLevel("error") val initialScores = Array((("hadoop", "R"), 1), (("hadoop", "java"), 1),
(("spark", "scala"), 1), (("spark", "R"), 1), (("spark", "java"), 1)) val d1 = sc.parallelize(initialScores) val result = d1.map(x => (x._1._1, (x._1._2, x._2))).combineByKey(
(v : (String, Int)) => (v : (String, Int)), // 初始化操作,当key首次出现时初始化以及执行一些转化操作
(c : (String, Int), v : (String, Int)) => (c._1 + "," + v._1, c._2 + v._2), // 分区内合并,非首次出现时进行合并
(c1 : (String,Int),c2 : (String,Int)) => (c1._1 + "," + c2._1, c1._2 + c2._2)) // 分组合并
.collect() result.foreach(println)
}
}
三.combineByKey算子执行结果

四.transform算子简介
在spark streaming中使用,用于实现把一个DStream转化为另一个DStream。
五.transform算子代码实现
package big.data.analyse.streaming
import org.apache.log4j.{Level, Logger}
import org.apache.spark.SparkConf
import org.apache.spark.streaming.{Seconds, StreamingContext}
/**
* Created by zhen on 2019/09/21.
*/
object StreamingSocket {
def functionToCreateContext():StreamingContext = {
val conf = new SparkConf().setMaster("local[2]").setAppName("StreaingTest")
val ssc = new StreamingContext(conf, Seconds(10))
val lines = ssc.socketTextStream("192.168.245.137", 9999)
val words = lines.flatMap(_.split(" "))
val pairs = words.map(word=>(word,1))
/**
* 过滤内容
*/
val filter = ssc.sparkContext.parallelize(List("money","god","oh","very")).map(key => (key,true))
val result = pairs.transform(rdd => { // transform:把一个DStream转化为另一个SDtream
val leftRDD = rdd.leftOuterJoin(filter)
val word = leftRDD.filter( tuple =>{
val y = tuple._2
if(y._2.isEmpty){
true
}else{
false
}
})
word.map(tuple =>(tuple._1,1))
}).reduceByKey(_+_)
result.foreachRDD(rdd => {
if(!rdd.isEmpty()){
rdd.foreach(println)
}
})
ssc.checkpoint("D:\\checkpoint")
ssc
}
Logger.getLogger("org").setLevel(Level.WARN) // 设置日志级别
def main(args: Array[String]) {
val ssc = StreamingContext.getOrCreate("D:\\checkpoint", functionToCreateContext _)
ssc.start()
ssc.awaitTermination()
ssc.stop()
}
}
六.transform算子执行结果
输入:
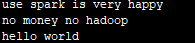
输出:

备注:若在执行流计算时报:Some blocks could not be recovered as they were not found in memory. To prevent such data loss, enable Write Ahead Log (see programming guide for more details.,可以清空checkpoint目录下对应的数据【当前执行生成的数据】,可以解决这个问题。
Spark高级函数应用【combineByKey、transform】的更多相关文章
- Spark核心RDD:combineByKey函数详解
https://blog.csdn.net/jiangpeng59/article/details/52538254 为什么单独讲解combineByKey? 因为combineByKey是Spark ...
- spark aggregate函数详解
aggregate算是spark中比较常用的一个函数,理解起来会比较费劲一些,现在通过几个详细的例子带大家来着重理解一下aggregate的用法. 1.先看看aggregate的函数签名在spark的 ...
- Spark高级数据分析——纽约出租车轨迹的空间和时间数据分析
Spark高级数据分析--纽约出租车轨迹的空间和时间数据分析 一.地理空间分析: 二.pom.xml 原文地址:https://www.jianshu.com/p/eb6f3e0c09b5 作者:II ...
- javascript高级函数
高级函数 安全的类型检测 js内置的类型检测并非完全可靠,typeof操作符难以判断某个值是否为函数 instanceof在多个frame的情况下,会出现问题. 例如:var isArray = va ...
- js 高级函数 之示例
js 高级函数作用域安全构造函数 function Person(name, age) { this.name = name; this.age = age; ...
- 浅谈JS中的高级函数
在JavaScript中,函数的功能十分强大.它们是第一类对象,也可以作为另一个对象的方法,还可以作为参数传入另一个函数,不仅如此,还能被一个函数返回!可以说,在JS中,函数无处不在,无所不能,堪比孙 ...
- php一些高级函数方法
PHP高级函数 1.call_user_func (http://php.net/manual/zh/function.call-user-func.php) 2.get_class (http:// ...
- Spark 用户自定义函数 Java 示例
Spark UDF Java 示例 在这篇文章中提到了用Spark做用户昵称文本聚类分析,聚类需要选定K个中心点,然后迭代计算其他样本点到中心点的距离.由于中文文字分词之后(n-gram)再加上昵称允 ...
- Python函数式编程(二):常见高级函数
一个函数的参数中有函数作为参数,这个函数就为高级函数. 下面学习几个常见高级函数. ---------------------------------------------------------- ...
随机推荐
- Scrapy笔记03- Spider详解
Scrapy笔记03- Spider详解 Spider是爬虫框架的核心,爬取流程如下: 先初始化请求URL列表,并指定下载后处理response的回调函数.初次请求URL通过start_urls指定, ...
- update Select 从查询的结果中更新表
UPDATE tbl_a a INNER JOIN tbl_b b ON a.arg=b.argSET a.arg2=b.arg2 这个语法即可实现
- es6 Class类的使用
es6新增了一种定义对象实例的方法,使用class关键字定义类,与class相关的知识点也逐步火热起来,但是部分理解起来相对抽象,简单对class相关的知识点进行总结,更好的使用class. 关于类有 ...
- 这里有一个url=https://www/.baidu.com/s?id=111&name=yourname,写一个函数获取query的参数和值存放在一个对象
console.log(getJson(url)); function getJson(url){ var obj={}; var arr=url.split("?")[1].sp ...
- 第02组 Alpha冲刺(2/6)
队名:無駄無駄 组长博客 作业博客 组员情况 张越洋 过去两天完成了哪些任务 任务分配.进度监督 提交记录(全组共用) 接下来的计划 沟通前后端成员,监督.提醒他们尽快完成各自的进度 还剩下哪些任务 ...
- CentOS 7搭建本地yum源和局域网yum源
这两天在部署公司的测试环境,在安装各种中间件的时候,发现各种依赖都没有:后来一检查,发现安装的操作系统是CentOS Mini版,好吧,我认了:为了完成测试环境的搭建,我就搭建了一个局域网的yum源. ...
- just the check 买单
今日焦点 Just the check 买单吧 split it 平分 leave a tip 留小费 词汇实践 hey. Can I get you anything else today? 您好. ...
- Alpha冲刺(11/10)——2019.5.3
作业描述 课程 软件工程1916|W(福州大学) 团队名称 修!咻咻! 作业要求 项目Alpha冲刺(团队) 团队目标 切实可行的计算机协会维修预约平台 开发工具 Eclipse 团队信息 队员学号 ...
- Mysql变量、存储过程、函数、流程控制
一.系统变量 系统变量: 全局变量 会话变量 自定义变量: 用户变量 局部变量 说明:变量由系统定义,不是用户定义,属于服务器层面 注意:全局变量需要添加global关键字,会话变量需要添加sessi ...
- redis的setIfAbsent
setIfAbsent(K key, V value) 如果键不存在则新增,存在则不改变已经有的值.