python bs4库
Beautiful Soup parses anything you give it, and does the tree traversal stuff for you.
BeautifulSoup库是解析、遍历、维护 “标签树” 的功能库(遍历,是指沿着某条搜索路线,依次对树中每个结点均做一次且仅做一次访问)。https://www.crummy.com/software/BeautifulSoup
BeautifulSoup库我们常称之为bs4,导入该库为:from bs4 import BeautifulSoup。其中,import BeautifulSoup即主要用bs4中的BeautifulSoup类。
bs4库解析器
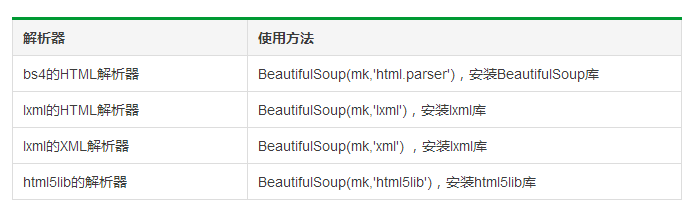
BeautifulSoup类的基本元素
1 import requests
2 from bs4 import BeautifulSoup
3
4 res = requests.get('http://www.pmcaff.com/site/selection')
5 soup = BeautifulSoup(res.text,'lxml')
6 print(soup.a)
7 # 任何存在于HTML语法中的标签都可以用soup.<tag>访问获得,当HTML文档中存在多个相同<tag>对应内容时,soup.<tag>返回第一个。
8
9 print(soup.a.name)
10 # 每个<tag>都有自己的名字,可以通过<tag>.name获取,字符串类型
11
12 print(soup.a.attrs)
13 print(soup.a.attrs['class'])
14 # 一个<tag>可能有一个或多个属性,是字典类型
15
16 print(soup.a.string)
17 # <tag>.string可以取到标签内非属性字符串
18
19 soup1 = BeautifulSoup('<p><!--这里是注释--></p>','lxml')
20 print(soup1.p.string)
21 print(type(soup1.p.string))
22 # comment是一种特殊类型,也可以通过<tag>.string取到
运行结果:
<a class="no-login" href="">登录</a>
a
{'href': '', 'class': ['no-login']} ['no-login']
登录
这里是注释
<class 'bs4.element.Comment'>
bs4库的HTML内容遍历
HTML的基本结构

标签树的下行遍历
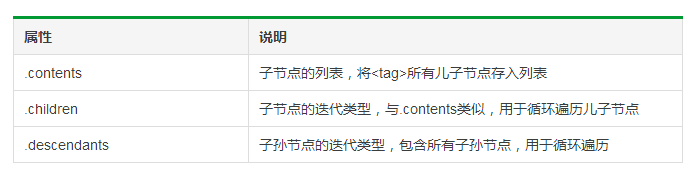
其中,BeautifulSoup类型是标签树的根节点。
1 # 遍历儿子节点
2 for child in soup.body.children:
3 print(child.name)
4
5 # 遍历子孙节点
6 for child in soup.body.descendants:
7 print(child.name)
标签树的上行遍历

1 # 遍历所有先辈节点时,包括soup本身,所以要if...else...判断
2 for parent in soup.a.parents:
3 if parent is None:
4 print(parent)
5 else:
6 print(parent.name)
运行结果:
div
div
body
html
[document]
标签树的平行遍历
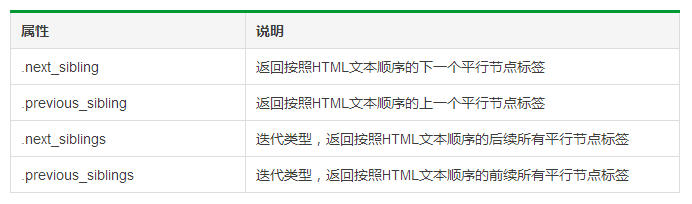
1 # 遍历后续节点
2 for sibling in soup.a.next_sibling:
3 print(sibling)
4
5 # 遍历前续节点
6 for sibling in soup.a.previous_sibling:
7 print(sibling)
bs4库的prettify()方法
prettify()方法可以将代码格式搞的标准一些,用soup.prettify()表示。在PyCharm中,用print(soup.prettify())来输出。
python bs4库的更多相关文章
- Python 每日提醒写博客小程序,使用pywin32、bs4库
死循环延迟调用方法,使用bs4库检索博客首页文章的日期是否与今天日期匹配,不匹配则说明今天没写文章,调用pywin32库进行弹窗提醒我写博客.
- python标准库Beautiful Soup与MongoDb爬喜马拉雅电台的总结
Beautiful Soup标准库是一个可以从HTML/XML文件中提取数据的Python库,它能够通过你喜欢的转换器实现惯用的文档导航,查找,修改文档的方式,Beautiful Soup将会节省数小 ...
- python BeautifulSoup库的基本使用
Beautiful Soup 是用Python写的一个HTML/XML的解析器,它可以很好的处理不规范标记并生成剖析树(parse tree). 它提供简单又常用的导航(navigating),搜索以 ...
- python BeautifulSoup库用法总结
1. Beautiful Soup 简介 简单来说,Beautiful Soup是python的一个库,最主要的功能是从网页抓取数据.官方解释如下: Beautiful Soup提供一些简单的.pyt ...
- python3.4学习笔记(八) Python第三方库安装与使用,包管理工具解惑
python3.4学习笔记(八) Python第三方库安装与使用,包管理工具解惑 许多人在安装Python第三方库的时候, 经常会为一个问题困扰:到底应该下载什么格式的文件?当我们点开下载页时, 一般 ...
- Python BeautifulSoup库的用法
BeautifulSoup是一个可以从HTML或者XML文件中提取数据的Python库,它通过解析器把文档解析为利于人们理解的文档导航模式,有利于查找和修改文档. BeautifulSoup3目前已经 ...
- python第三方库地址
python第三方库的地址: requests: http://docs.python-requests.org/zh_CN/latest/user/quickstart.html beautifus ...
- windows下python常用库的安装
windows下python常用库的安装,前提安装了annaconda 的python开发环境.只要已经安装了anaconda,要安装别的库就很简单了.只要使用pip即可,正常安装好python,都会 ...
- Python:requests库、BeautifulSoup4库的基本使用(实现简单的网络爬虫)
Python:requests库.BeautifulSoup4库的基本使用(实现简单的网络爬虫) 一.requests库的基本使用 requests是python语言编写的简单易用的HTTP库,使用起 ...
随机推荐
- 2.eclipse 插件安装烦死人(2)
安装插件的实际结果是:(烦死人),要不是很多插件找不到,要不就是版本不对,要不就是下载了装上没有效果,要不就是在线安装(速度爆慢),好不容易等到结果了,结果是些错…… 最后我的eclipse 3.5. ...
- GeHost powershell
PS C:\Users\clu\Desktop> [System.Net.Dns] | Get-Member -Static | Format-Table -AutoSize TypeName: ...
- 今天要查一下,如果没有密保手机的号码在使用,怎么更换qq的密保手机
本来我是想是使用284来作为foxmail的一个记事本账号,但是需要验证130的手机,这是以前使用的手机,现在不能接受该短信了,得反馈下.
- easyui 生成tas方式
1.采用<a>标签形式 <div id="tabs" style="width:100%;"> <ul> <li id ...
- Django day 37 网站视频的播放,购物车接口,优惠券表分析
一:网站视频的播放, 二:购物车接口, 三:优惠券表分析
- vue用户登录状态判断
之前项目中用来判断是否登录我写了多种方案,但是最终只有一个方案是比较好的,这篇博客就是分享该方案; 先说基本要求: 项目中的登录状态是依据服务器里的状态来作为判断依据; 每一个需要登录后才能操作的接口 ...
- BADI FCODE(菜单) 增强
菜单增强功能只能用于非依赖于过滤器的一次性BADI(不是多用途的). 目前,菜单增强功能只能与程序增强功能(界面)一起创建. 定义一个没有过滤器的一次性增强 2.Classic Badi在FCODE ...
- tomcat 参数调优
JAVA_OPTS="-Xms2g -Xmx2g -XX:+PrintGCDetails -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath= ...
- SQL 经典语句大全
原地址:http://www.cnblogs.com/yubinfeng/archive/2010/11/02/1867386.html 一.基础 1.说明:创建数据库 CREATE DATABASE ...
- Android项目模块化遇到的问题
1.问题背景 gradle 4 MacOs 10.14.3 Android Studio 3 在android模块化的时候,例如,有两个模块,一个是usercenter,另一个是common. 其中u ...