Spark学习笔记--Spark在Windows下的环境搭建(转)
本文主要是讲解Spark在Windows环境是如何搭建的
一、JDK的安装
1、1 下载JDK
首先需要安装JDK,并且将环境变量配置好,如果已经安装了的老司机可以忽略。JDK(全称是JavaTM Platform Standard Edition Development Kit)的安装,去Oracle官网下载,下载地址是Java SE Downloads 。
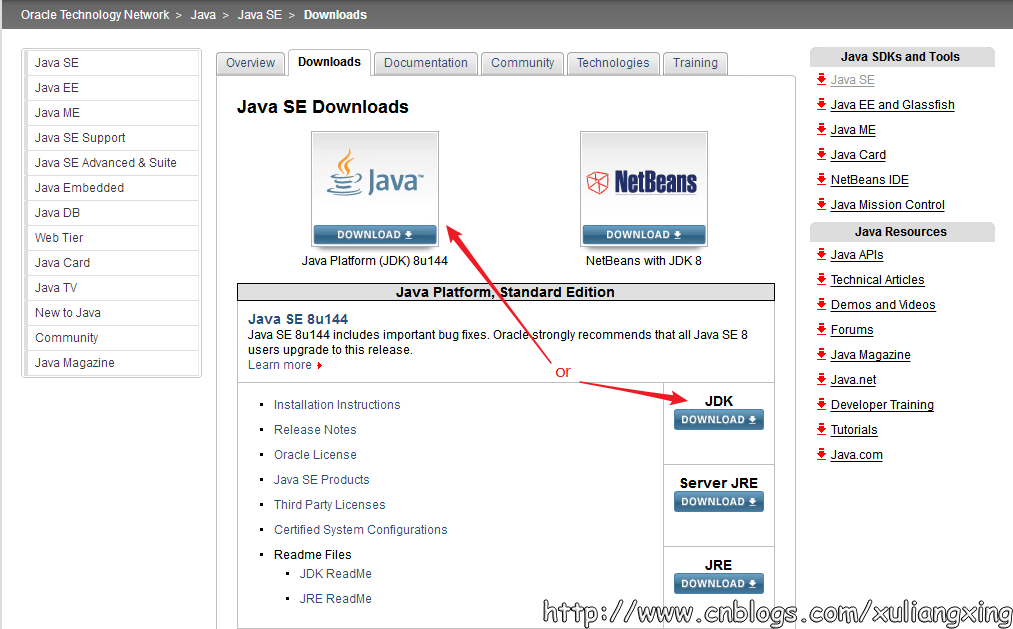
上图中两个用红色标记的地方都是可以点击的,点击进去之后可以看到这个最新版本的一些更为详细的信息,如下图所示:
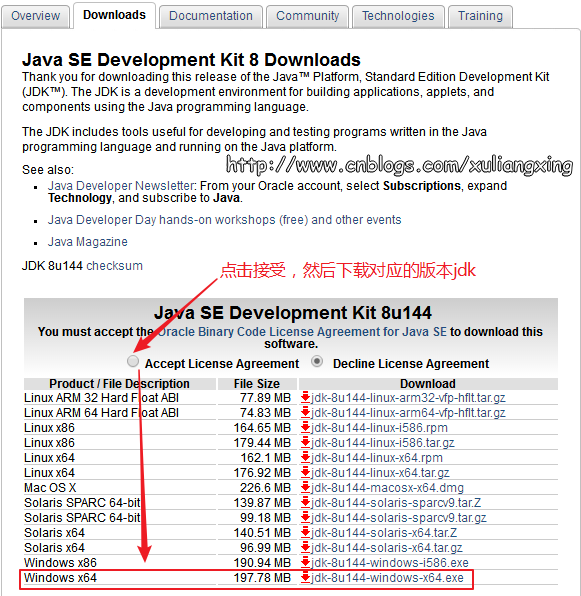
下载完之后,我们安装就可以直接JDK,JDK在windows下的安装非常简单,按照正常的软件安装思路去双击下载得到的exe文件,然后设定你自己的安装目录(这个安装目录在设置环境变量的时候需要用到)即可。
1、2 JDK环境变量设置
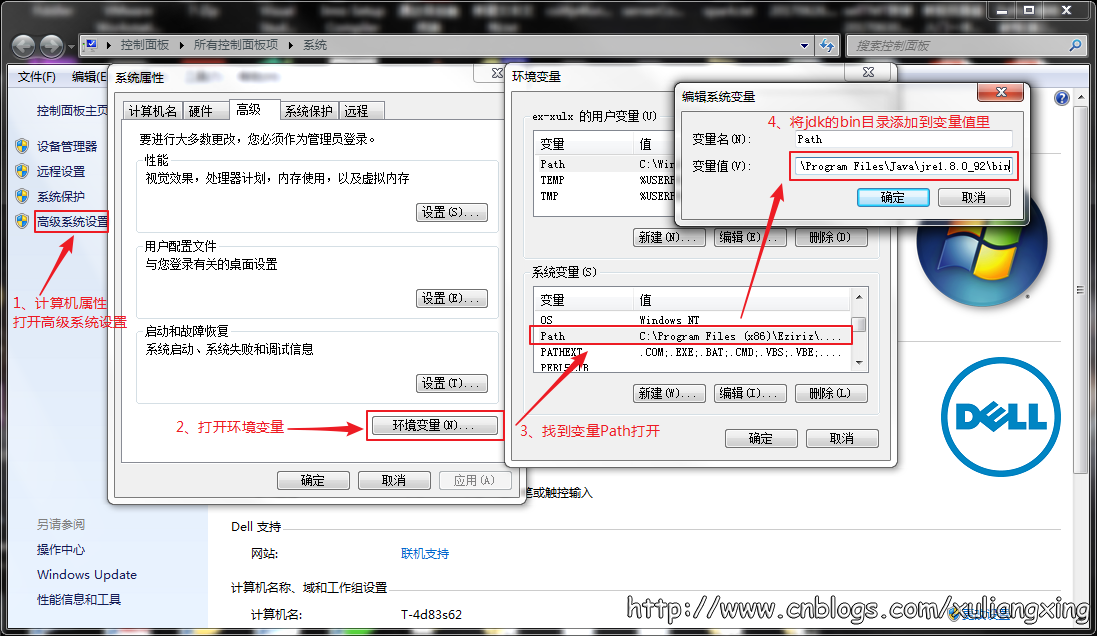
接下来设置相应的环境变量,设置方法为:在桌面右击【计算机】--【属性】--【高级系统设置】,然后在系统属性里选择【高级】--【环境变量】,然后在系统变量中找到“Path”变量,并选择“编辑”按钮后出来一个对话框,可以在里面添加上一步中所安装的JDK目录下的bin文件夹路径名,我这里的bin文件夹路径名是:C:\Program Files\Java\jre1.8.0_92\bin,所以将这个添加到path路径名下,注意用英文的分号“;”进行分割。如图所示:
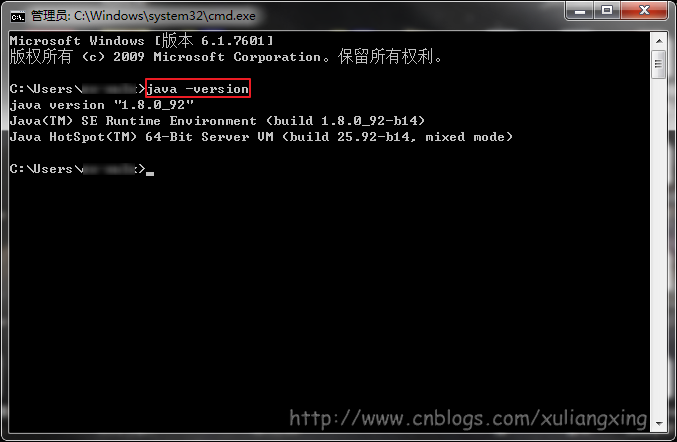
这样设置好后,便可以在任意目录下打开的cmd命令行窗口下运行下面命令。查看是否设置成功。
java -version
观察是否能够输出相关java的版本信息,如果能够输出,说明JDK安装这一步便全部结束了。如图所示:
二、Scala的安装
我们从官网:http://www.scala-lang.org/ 下载Scala,最新的版本为2.12.3,如图所示
因为我们是在Windows环境下,这也是本文的目的,我们选择对应的Windows版本下载,如图所示:
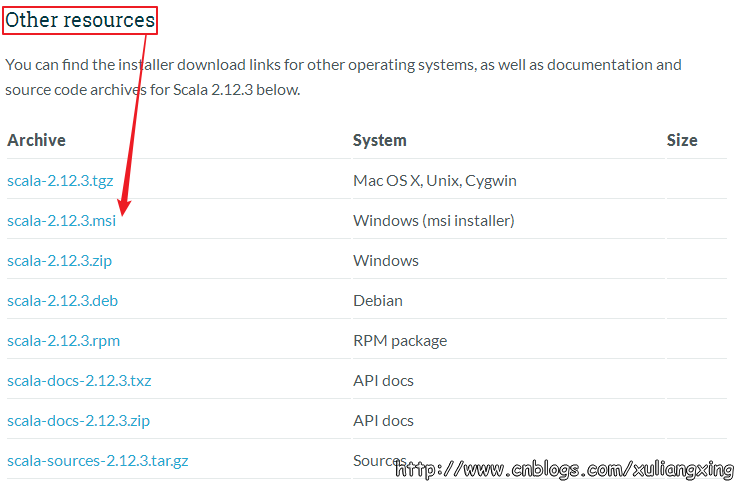
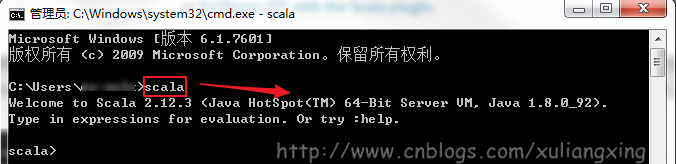
下载得到Scala的msi文件后,可以双击执行安装。安装成功后,默认会将Scala的bin目录添加到PATH系统变量中去(如果没有,和上面JDK安装步骤中类似,将Scala安装目录下的bin目录路径,添加到系统变量PATH中),为了验证是否安装成功,开启一个新的cmd窗口,输入scala然后回车,如果能够正常进入到Scala的交互命令环境则表明安装成功。如下图所示:
备注:如果不能显示版本信息,并且未能进入Scala的交互命令行,通常有两种可能性:
1、Path系统变量中未能正确添加Scala安装目录下的bin文件夹路径名,按照JDK安装中介绍的方法添加即可。
2、Scala未能够正确安装,重复上面的步骤即可。
三、Spark的安装
我们到Spark官网进行下载:http://spark.apache.org/ ,我们选择带有Hadoop版本的Spark,如图所示:
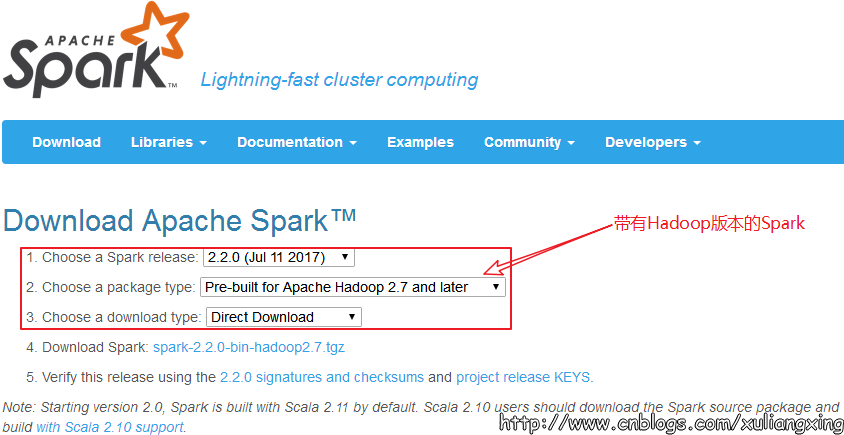
下载后得到了大约200M的文件: spark-2.2.0-bin-hadoop2.7
这里使用的是Pre-built的版本,意思就是已经编译了好了,下载来直接用就好,Spark也有源码可以下载,但是得自己去手动编译之后才能使用。下载完成后将文件进行解压(可能需要解压两次),最好解压到一个盘的根目录下,并重命名为Spark,简单不易出错。并且需要注意的是,在Spark的文件目录路径名中,不要出现空格,类似于“Program Files”这样的文件夹名是不被允许的。我们在C盘新建一个Spark文件夹存放,如图所示:
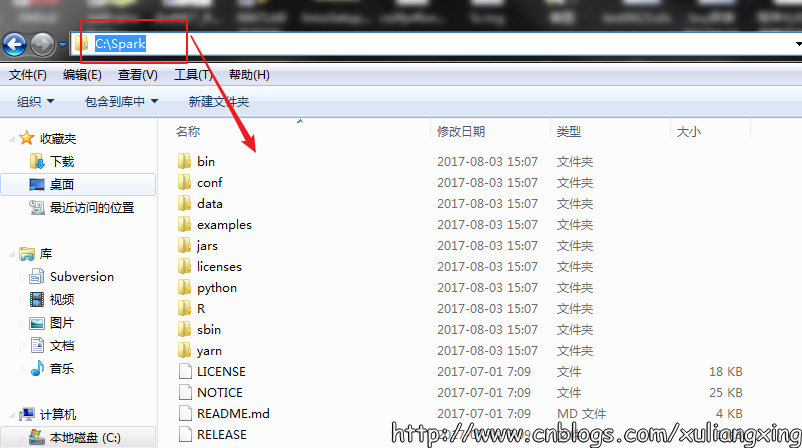
解压后基本上就差不多可以到cmd命令行下运行了。但这个时候每次运行spark-shell(spark的命令行交互窗口)的时候,都需要先cd到Spark的安装目录下,比较麻烦,因此可以将Spark的bin目录添加到系统变量PATH中。例如我这里的Spark的bin目录路径为D:\Spark\bin,那么就把这个路径名添加到系统变量的PATH中即可,方法和JDK安装过程中的环境变量设置一致,设置完系统变量后,在任意目录下的cmd命令行中,直接执行spark-shell命令,即可开启Spark的交互式命令行模式。
系统变量设置后,就可以在任意当前目录下的cmd中运行spark-shell,但这个时候很有可能会碰到各种错误,这里主要是因为Spark是基于hadoop的,所以这里也有必要配置一个Hadoop的运行环境。错误如图所示:
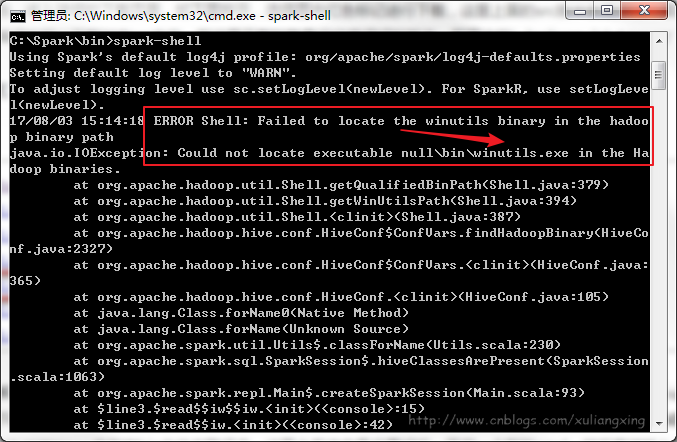
接下来,我们还需要安装Hadoop。
四、Hadoop的安装
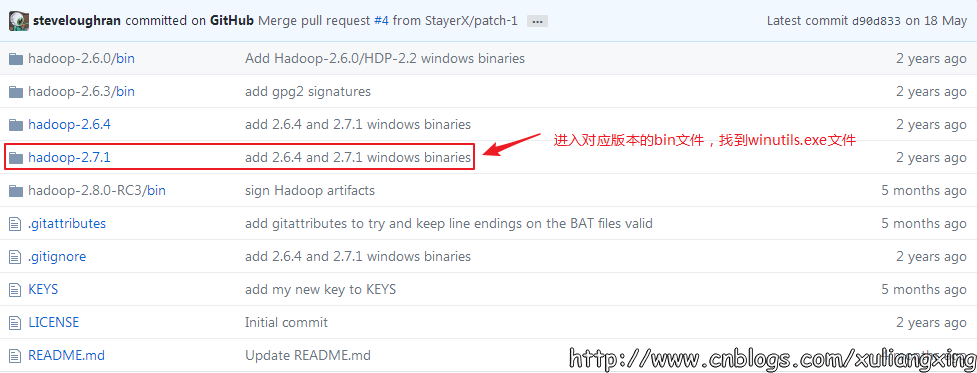
在Hadoop Releases里可以看到Hadoop的各个历史版本,这里由于下载的Spark是基于Hadoop 2.7的(在Spark安装的第一个步骤中,我们选择的是Pre-built for Hadoop 2.7),我这里选择2.7.1版本,选择好相应版本并点击后,进入详细的下载页面,如下图所示:

选择图中红色标记进行下载,这里上面的src版本就是源码,需要对Hadoop进行更改或者想自己进行编译的可以下载对应src文件,我这里下载的就是已经编译好的版本,即图中的“hadoop-2.7.1.tar.gz”文件。
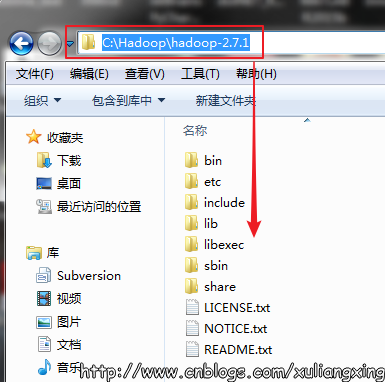
下载并解压到指定目录,,我这里是C:\Hadoop,如图所示:
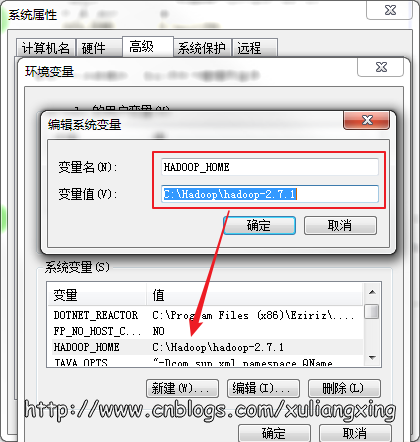
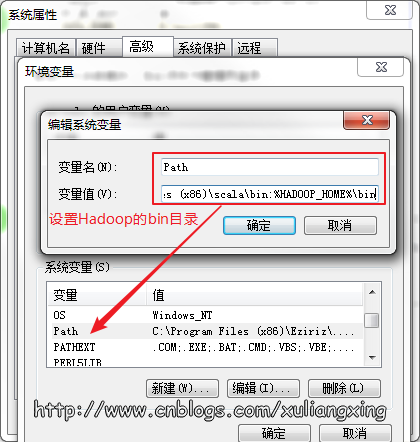
然后到环境变量部分设置HADOOP_HOME为Hadoop的解压目录,如图所示:
然后再设置该目录下的bin目录到系统变量的PATH下,我这里也就是C:\Hadoop\bin,如果已经添加了HADOOP_HOME系统变量,也可用%HADOOP_HOME%\bin来指定bin文件夹路径名。这两个系统变量设置好后,开启一个新的cmd窗口,然后直接输入spark-shell命令。如图所示:
正常情况下是可以运行成功并进入到Spark的命令行环境下的,但是对于有些用户可能会遇到空指针的错误。这个时候,主要是因为Hadoop的bin目录下没有winutils.exe文件的原因造成的。这里的解决办法是:
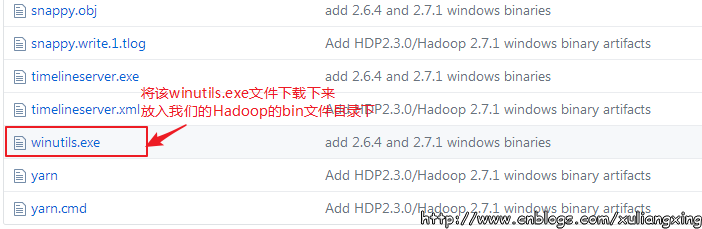
可以去 https://github.com/steveloughran/winutils 选择你安装的Hadoop版本号,然后进入到bin目录下,找到winutils.exe文件,下载方法是点击winutils.exe文件,进入之后在页面的右上方部分有一个Download按钮,点击下载即可。 如图所示:
下载winutils.exe文件
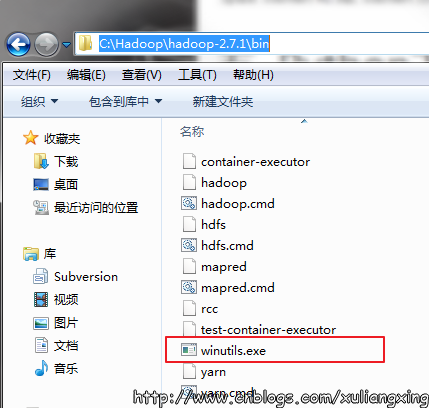
将下载好winutils.exe后,将这个文件放入到Hadoop的bin目录下,我这里是C:\Hadoop\hadoop-2.7.1\bin。
在打开的cmd中输入
C:\Hadoop\hadoop-2.7.1\bin\winutils.exe chmod 777 /tmp/Hive //修改权限,777是获取所有权限
但是我们发现报了一些其他的错(Linux环境下也是会出现这个错误)
1 <console>:14: error: not found: value spark
2 import spark.implicits._
3 ^
4 <console>:14: error: not found: value spark
5 import spark.sql
其原因是没有权限在spark中写入metastore_db 这个文件。
处理方法:我们授予777的权限
Linux环境,我们在root下操作:
1 sudo chmod 777 /home/hadoop/spark
2
3 #为了方便,可以给所有的权限
4 sudo chmod a+w /home/hadoop/spark
window环境下:
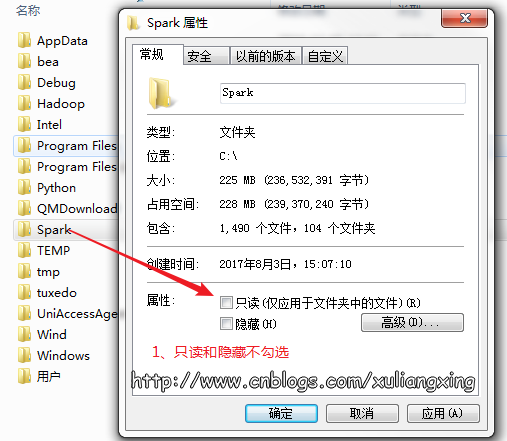
存放Spark的文件夹不能设为只读和隐藏,如图所示:
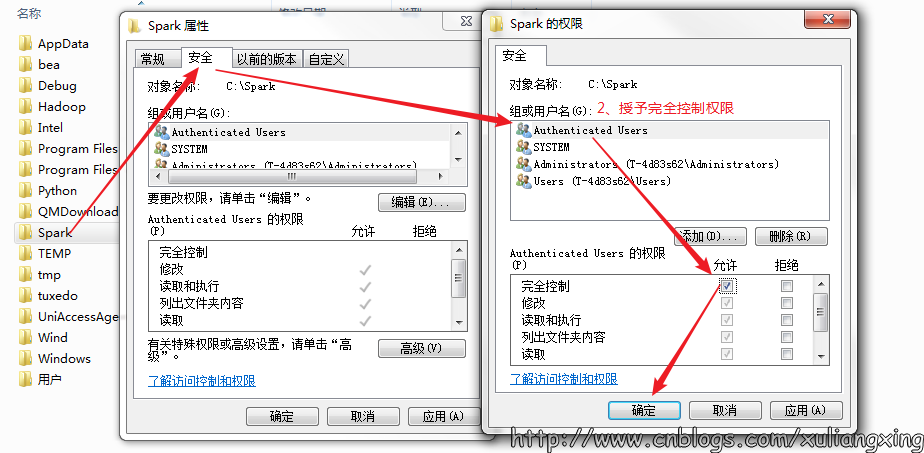
授予完全控制的权限,如图所示:
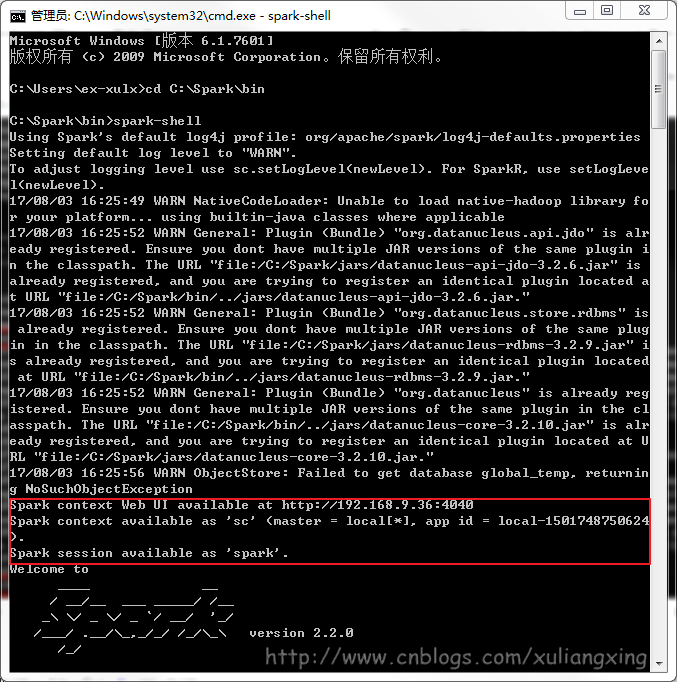
经过这几个步骤之后,然后再次开启一个新的cmd窗口,如果正常的话,应该就可以通过直接输入spark-shell来运行Spark了。正常的运行界面应该如下图所示:
Spark学习笔记--Spark在Windows下的环境搭建(转)的更多相关文章
- 【Spring学习笔记-1】Myeclipse下Spring环境搭建
*.hl_mark_KMSmartTagPinkImg{background-color:#ffaaff;}*.hl_mark_KMSmartTagBlueImg{background-color:# ...
- Spark学习笔记3——RDD(下)
目录 Spark学习笔记3--RDD(下) 向Spark传递函数 通过匿名内部类 通过具名类传递 通过带参数的 Java 函数类传递 通过 lambda 表达式传递(仅限于 Java 8 及以上) 常 ...
- (转)Lua学习笔记1:Windows7下使用VS2015搭建Lua开发环境
Lua学习笔记1:Windows7下使用VS2015搭建Lua开发环境(一)注意:工程必须添加两个宏:“配置属性”/“C或C++”/“预处理器”/“预处理器定义”,添加两个宏:_CRT_SECURE_ ...
- Windows下的环境搭建Erlang
Windows下的环境搭建 Erlang 一.安装编译器 在http://www.erlang.org/download.html下载R16B01 Windows Binary File并安装. 二. ...
- Redis在windows下的环境搭建
Redis在windows下的环境搭建 下载windows版本redis,,官方下载地址:http://redis.io/download, 不过官方没有Windows版本,官网只提供linux版本的 ...
- 2017.7.18 windows下ELK环境搭建
参考来自:Windows环境下ELK平台的搭建 另一篇博文:2017.7.18 linux下ELK环境搭建 0 版本说明 因为ELK从5.0开始只支持jdk 1.8,但是项目中使用的是JDK 1.7, ...
- Spark学习笔记--Spark在Windows下的环境搭建
本文主要是讲解Spark在Windows环境是如何搭建的 一.JDK的安装 1.1 下载JDK 首先需要安装JDK,并且将环境变量配置好,如果已经安装了的老司机可以忽略.JDK(全称是JavaTM P ...
- Spark在Windows下的环境搭建(转)
原作者:xuweimdm 原文网址:http://blog.csdn.net/u011513853/article/details/52865076 由于Spark是用Scala来写的,所以Spa ...
- Spark在Windows下的环境搭建
本文转载自:http://blog.csdn.net/u011513853/article/details/52865076 由于Spark是用Scala来写的,所以Spark对Scala肯定是原生态 ...
随机推荐
- web框架和Django框架的初识
1,web框架的原理 1.1>c/s架构和b/s架构 1>c/s客户端模式 2>B/S浏览器模式-----web开发(web开发开的是B/S架构) 1.2>web开发的本质 1 ...
- HashMap与HashTable的区别?
HashMap和Hashtable的比较是Java面试中的常见问题,用来考验程序员是否能够正确使用集合类以及是否可以随机应变使用多种思路解决问题.HashMap的工作原理.ArrayList与Vect ...
- 5.eclipse 自带的jdk没有源码,改了它
其实JDK源码在安装的时候已经放在了jdk所在的目录下,只是eclipse使用 了不带有源码的jre,导致没找到对应的源码,点击 Window->Perference->Java-> ...
- mybatis批量操作数据
批量查询语句: List<MoiraiProductResource> selectBatchInfo(List<Long> idList); <!-- 批量查询 --& ...
- Lightoj 1006 Hex-a-bonacci
Given a code (not optimized), and necessary inputs, you have to find the output of the code for the ...
- HDU1069 Monkey and Banana —— DP
题目链接:http://acm.split.hdu.edu.cn/showproblem.php?pid=1069 Monkey and Banana Time Limit: 2000/1000 MS ...
- python 判断是否为有效域名
import re pattern = re.compile( r'^(([a-zA-Z]{1})|([a-zA-Z]{1}[a-zA-Z]{1})|' r'([a-zA-Z]{1}[0-9]{1}) ...
- 转3xian之所在 (一位ACM大牛的博文)
3xian的经历和见解...我深思... 最后一天,漫天飘起了雪花,假装欢送我离去. 这次WF之战不太顺利,早期的C题大概花了1秒钟构思,然而由于输出格式多了一个空格直到两个半小时才逃脱Wrong A ...
- openStack 镜像制作,镜像裁剪一般步骤
镜像制作一般裁剪步骤 1, linux系统安装CentOs/RHEL Desktop桌面系统,分区划分但分区/挂载点.设置Selinux=disabled关闭iptables安装cloud-init[ ...
- TCP、UDP和HTTP关系
TCP/IP是个协议组,可分为三个层次:网络层.传输层和应用层.IP:网络层协议: TCP和UDP:传输层协议:TCP提供有保证的数据传输,UDP不提供. HTTP:应用层协议(超文本传输协议): 如 ...