LSTM网络
http://colah.github.io/posts/2015-08-Understanding-LSTMs/
https://www.jianshu.com/p/9dc9f41f0b29
机器学习面试100题: https://blog.csdn.net/T7SFOKzorD1JAYMSFk4/article/details/78960039
RNN 是包含循环的网络,允许信息的持久化。

当相关信息和当前预测位置之间的间隔不断增大时,RNN 会丧失学习到连接如此远的信息的能力。
Long Short Term 网络(LSTM)是一种 RNN 特殊的类型,可以学习长期依赖信息。
所有 RNN 都具有一种重复神经网络模块的链式的形式。在标准的 RNN 中,这个重复的模块只有一个非常简单的结构,例如一个 tanh 层。
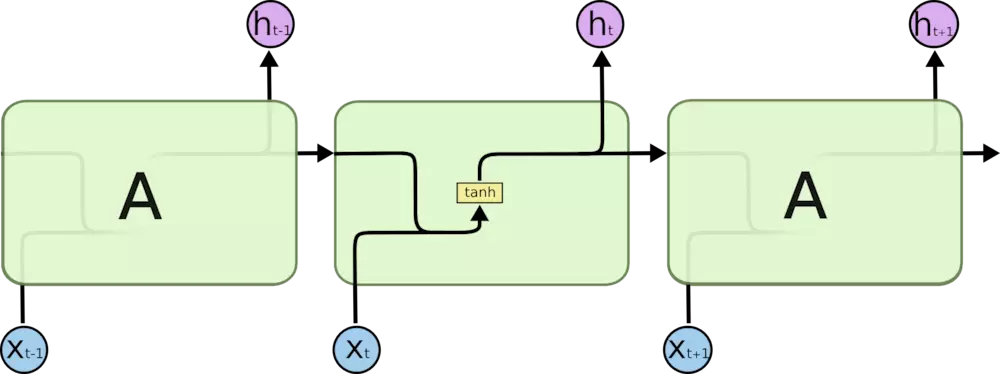
LSTM 同样是这样的结构,但是重复的模块拥有一个不同的结构。不同于 单一神经网络层,这里是有四个,以一种非常特殊的方式进行交互。
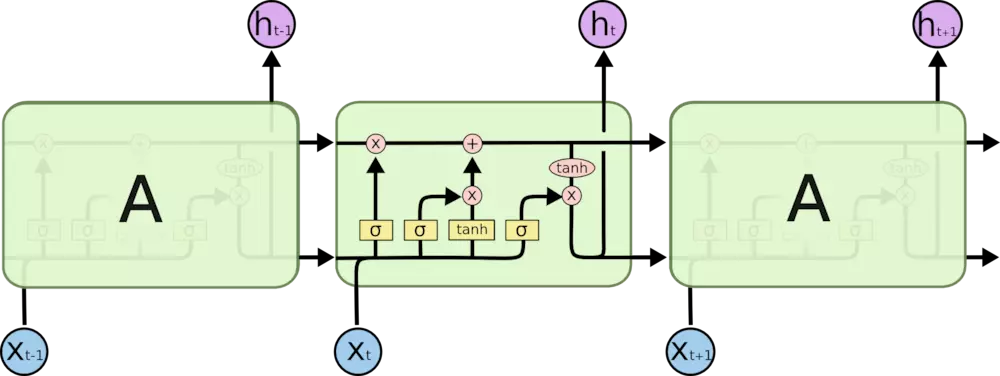
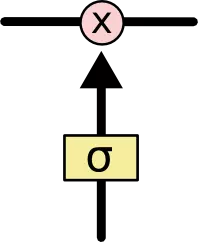
上图中相应图标的含义:

LSTM 的关键就是细胞状态,水平线在图上方贯穿运行。
细胞状态类似于传送带。直接在整个链上运行,只有一些少量的线性交互。信息在上面流传保持不变会很容易。
LSTM 有通过精心设计的称作为“门”的结构来去除或者增加信息到细胞状态的能力。门是一种让信息选择式通过的方法。他们包含一个 sigmoid 神经网络层和一个按位的乘法操作。
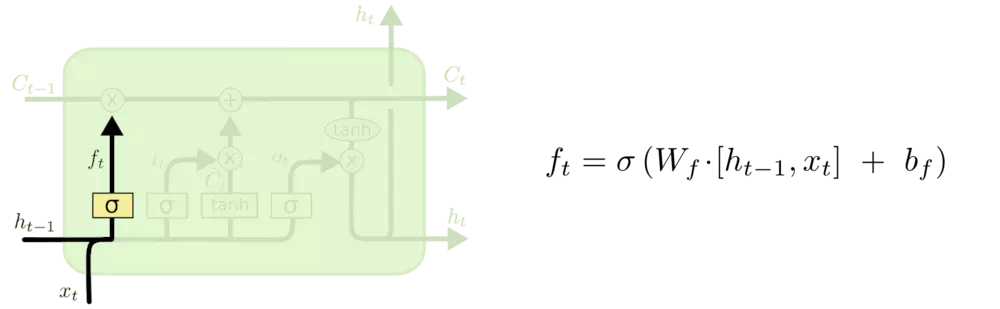
LSTM中结构分析:
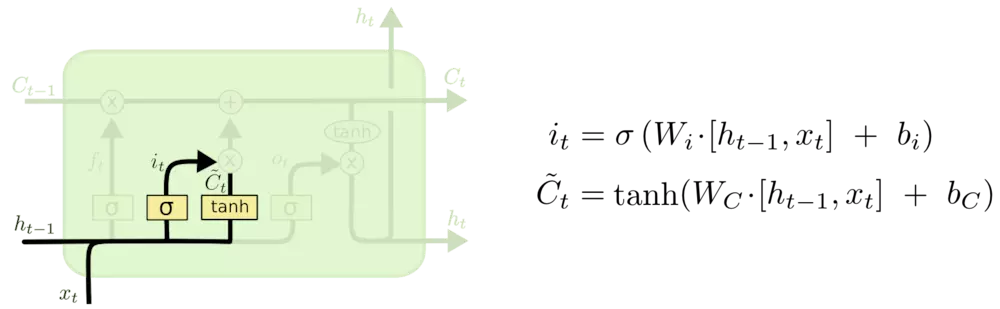
更新细胞状态:

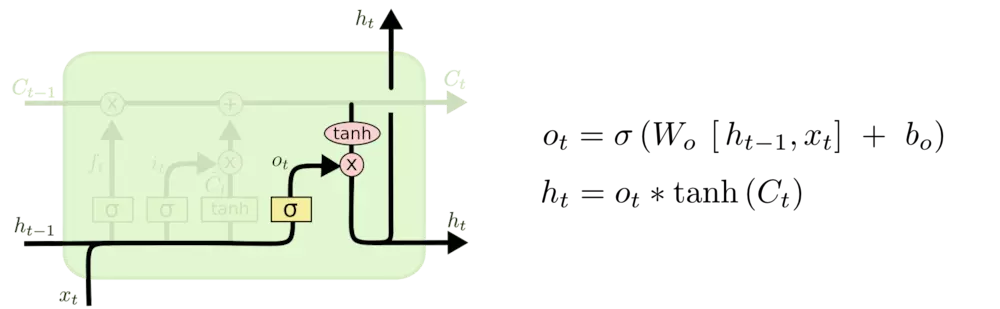
输出信息:
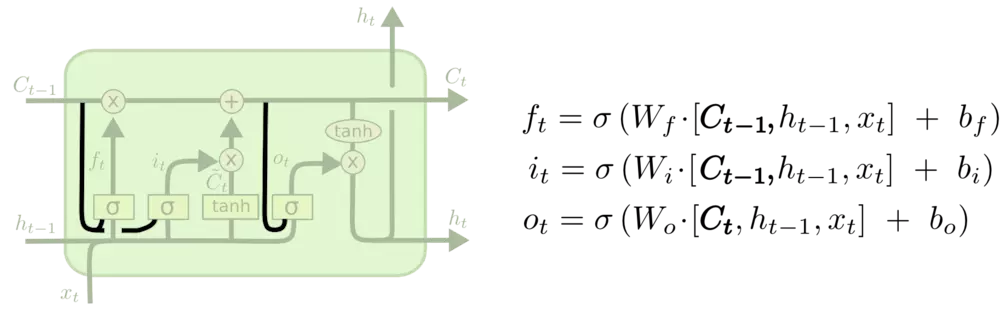
LSTM变体:
1、让门层也会接受细胞状态的输入
2、

3、Gated Recurrent Unit (GRU):

LSTM输入输出:https://mp.weixin.qq.com/s/aV9Rj-CnJZRXRm0rDOK6gg
1、input_shape=(13, 5), 在NLP中可以理解为一个句子是 13个词,所以LSTM神经网络在时间上展开是 13个框, 每个词对应的词向量是 5 维,即每个时刻的输入$X_t$是 5 维的向量.
2、keras中的model.add(LSTM(10))中, 10 代表LSTM的hidden state $h_t$ 是 10维,
sequence to sequence模型: https://zhuanlan.zhihu.com/p/25366912
RNN Encoder-Decoder结构,包含两部分,一个负责对输入的信息进行Encoding,将输入转换为向量形式。然后由Decoder对这个向量进行解码,还原为输出序列。
而RNN Encoder-Decoder结构就是编码器与解码器都是使用RNN算法,一般为LSTM。
LSTM的优势在于处理序列,它可以将上文包含的信息保存在隐藏状态(细胞状态)中,这样就提高了算法对于上下文的理解能力。
Encoder与Decoder各自可以算是单独的模型,一般是一层或多层的LSTM。
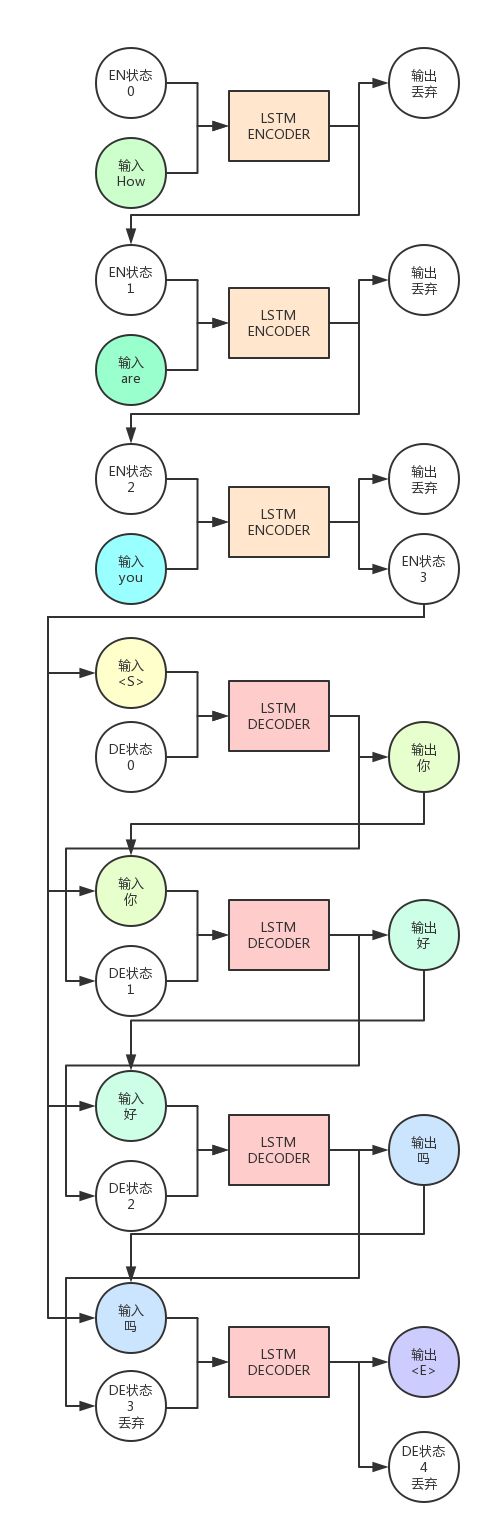
上图中,LSTM Encoder是一个LSTM神经元,Decoder是另一个,Encoder自身运行了`3`次,Decoder运行了`4`次。
可以看出,Encoder的输出会被抛弃,我们只需要保留隐藏状态(即图中EN状态)作为下一次ENCODER的状态输入。
Encoder的最后一轮输出状态会与Decoder的输入组合在一起,共同作为Decoder的输入。
而Decoder的输出会被保留,当做下一次的的输入。注意,这是在说预测时时的情况,一般在训练时一般会用真正正确的输出序列内容,而预测时会用上一轮Decoder的输出。
给Decoder的第一个输入是`<S>`,这是我们指定的一个特殊字符,它用来告诉Decoder,你该开始输出信息了。
而最末尾的`<E>`也是我们指定的特殊字符,它告诉我们,句子已经要结束了,不用再运行了。
Trick:
虽然LSTM能避免梯度弥散问题,但是不能对抗梯度爆炸问题(Exploding Gradient)。
为了对抗梯度爆炸,一般会对梯度进行裁剪。
梯度剪裁的方法一般有两种,一种是当梯度的某个维度绝对值大于某个上限的时候,就剪裁为上限。
另一种是梯度的L2范数大于上限后,让梯度除以范数,避免过大。
Bengio的原文中用的另一个trick是他们的输入序列是反向输入的,也就是说实际输入模型的顺序并不是
`How are you`而是`you are How`。至于为什么这样效果更好,还是一个迷。
进一步深入:
attention模型
LSTM网络的更多相关文章
- [译] 理解 LSTM 网络
原文链接:http://colah.github.io/posts/2015-08-Understanding-LSTMs/ 吴恩达版:http://www.ai-start.com/dl2017/h ...
- [译] 理解 LSTM(Long Short-Term Memory, LSTM) 网络
本文译自 Christopher Olah 的博文 Recurrent Neural Networks 人类并不是每时每刻都从一片空白的大脑开始他们的思考.在你阅读这篇文章时候,你都是基于自己已经拥有 ...
- [深度学习]理解RNN, GRU, LSTM 网络
Recurrent Neural Networks(RNN) 人类并不是每时每刻都从一片空白的大脑开始他们的思考.在你阅读这篇文章时候,你都是基于自己已经拥有的对先前所见词的理解来推断当前词的真实含义 ...
- (译)理解 LSTM 网络 (Understanding LSTM Networks by colah)
@翻译:huangyongye 原文链接: Understanding LSTM Networks 前言:其实之前就已经用过 LSTM 了,是在深度学习框架 keras 上直接用的,但是到现在对LST ...
- [转] 理解 LSTM 网络
[译] 理解 LSTM 网络 http://www.jianshu.com/p/9dc9f41f0b29 Recurrent Neural Networks 人类并不是每时每刻都从一片空白的大脑开始他 ...
- 『cs231n』RNN之理解LSTM网络
概述 LSTM是RNN的增强版,1.RNN能完成的工作LSTM也都能胜任且有更好的效果:2.LSTM解决了RNN梯度消失或爆炸的问题,进而可以具有比RNN更为长时的记忆能力.LSTM网络比较复杂,而恰 ...
- 理解 LSTM 网络
递归神经网络 人类并不是每时每刻都从头开始思考.正如你阅读这篇文章的时候,你是在理解前面词语的基础上来理解每个词.你不会丢弃所有已知的信息而从头开始思考.你的思想具有持续性. 传统的神经网络不能做到这 ...
- 基于 Keras 用 LSTM 网络做时间序列预测
目录 基于 Keras 用 LSTM 网络做时间序列预测 问题描述 长短记忆网络 LSTM 网络回归 LSTM 网络回归结合窗口法 基于时间步的 LSTM 网络回归 在批量训练之间保持 LSTM 的记 ...
- LSTM网络应用于DGA域名识别--文献翻译--更新中
原文献名称 Predicting Domain Generation Algorithms with Long Short-Term Memory Networks原文作者 Jonathan Wood ...
- 【翻译】理解 LSTM 网络
目录 理解 LSTM 网络 递归神经网络 长期依赖性问题 LSTM 网络 LSTM 的核心想法 逐步解析 LSTM 的流程 长短期记忆的变种 结论 鸣谢 本文翻译自 Christopher Olah ...
随机推荐
- (34)zabbix Queue队列
概述 queue(队列)显示监控项等待刷新的时间,可以看到每种agent类型刷新时间,通过queue可以更好的体现出监控的一个指标.正常情况下,是一片绿色. 如果出现过多红色,那么需要留意一下.我们也 ...
- axure笔记--内置变量
部件变量: This:当前变量名称 Target:目标变量的名称 x,y表示组件左上角的位置 name:获取当前组件标签命名 Top:获取组件上边界到x轴的距离 bottom:获取组件下边界到x轴的距 ...
- RESTful API批量操作的实现
要解决的问题 RESTful API对于批量操作存在一定的缺陷.例如资源的删除接口: DELETE /api/resourse/<id>/ 如果我们要删除100条数据怎么搞?难道要调用10 ...
- python面向对象(反射)(四)
1. isinstance, type, issubclass isinstance: 判断你给对象是否是xx类型的. (向上判断 type: 返回xxx对象的数据类型 issubclass: 判断x ...
- Day06for循环和字符串的内置方法
Day06 1.for循环(迭代器循环) while循环 条件循环,循环是否结束取决于条件的真假 for循环,迭代器循环,多用于循环取值,循环是否结束取决于被循环数据的元素个数 2.range(1,5 ...
- LeetCode(113) Path Sum II
题目 Given a binary tree and a sum, find all root-to-leaf paths where each path's sum equals the given ...
- gg mirror
https://gufen.ga/ (无广告,原guso.ml,ggso.ga,guge.ga) https://a.aiguso.tk (无广告,体验良好) https://a.freedo.gq/ ...
- shell 几中专用修饰符 :- :+ := ${variable:offset:length}
1.${variable:-word} ${variable:-word} 如果variable已经被设置了,且不为空,则代入它的值,否则代入word; $ fruit=peach $ echo ${ ...
- DDoS 攻击与防御:从原理到实践(上)
欢迎访问网易云社区,了解更多网易技术产品运营经验. 可怕的 DDoS 出于打击报复.敲诈勒索.政治需要等各种原因,加上攻击成本越来越低.效果特别明显等趋势,DDoS 攻击已经演变成全球性的网络安全威胁 ...
- 【原】缓存之 HttpRuntime.Cache
1.HttpRuntime.Cache HttpRuntime.Cache 相当于就是一个缓存具体实现类,这个类虽然被放在了 System.Web 命名空间下了.但是非 Web 应用也是可以拿来用的. ...