【Java源码】集合类-优先队列PriorityQueue
一、类继承关系
public class PriorityQueue<E> extends AbstractQueue<E>
implements java.io.Serializable {
PriorityQueue只实现了AbstractQueue抽象类也就是实现了Queue接口。
二、类属性
//默认初始化容量
private static final int DEFAULT_INITIAL_CAPACITY = 11;
//通过完全二叉树(complete binary tree)实现的小顶堆
transient Object[] queue;
private int size = 0;
//比较器
private final Comparator<? super E> comparator;
//队列结构被改变的次数
transient int modCount = 0;
根据transient Object[] queue; 的英文注释:
Priority queue represented as a balanced binary heap: the two children of queue[n] are queue[2n+1] and queue[2(n+1)].
我们可以知道PriorityQueue内部是通过完全二叉树(complete binary tree)实现的小顶堆(注意:这里我们定义的比较器为越小优先级越高)实现的。
三、数据结构
优先队列PriorityQueue内部是通过堆实现的。堆分为大顶堆和小顶堆:
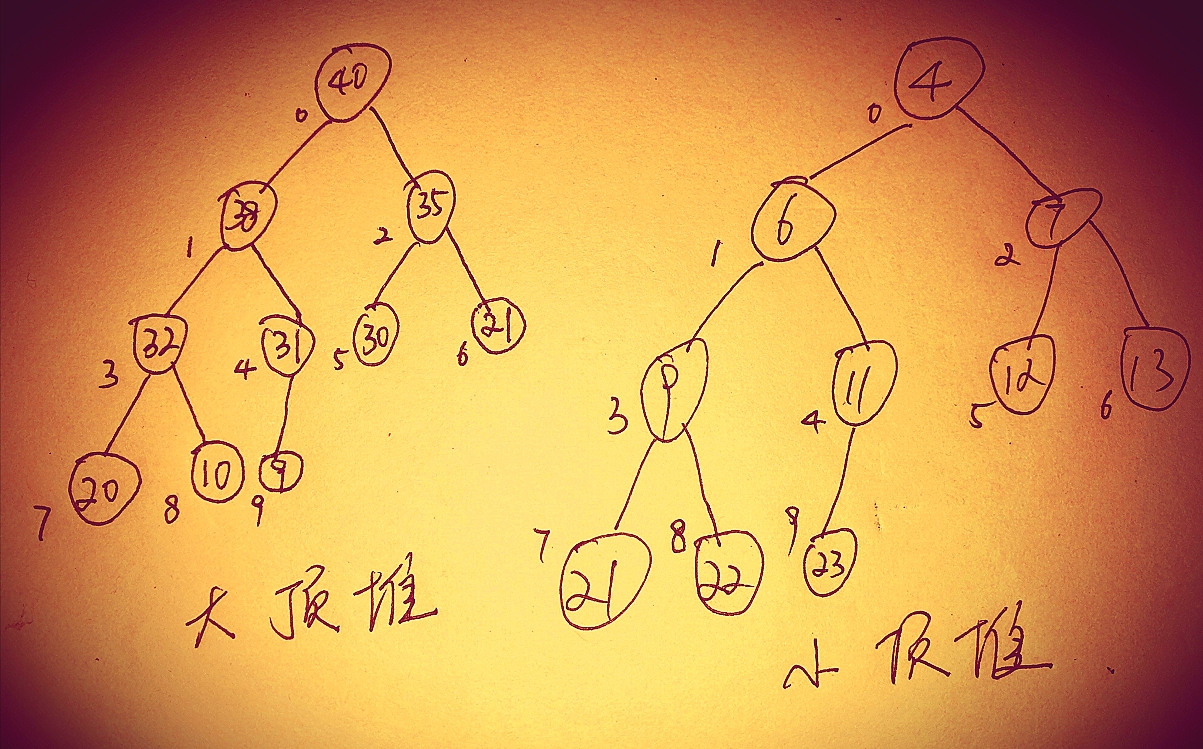
- 大顶堆:每个结点的值都大于或等于其左右孩子结点的值,称为大顶堆;
- 小顶堆:每个结点的值都小于或等于其左右孩子结点的值,称为小顶堆。
- 堆通过数组来实现。
- PriorityQueue内部是一颗完全二叉树实现的小顶堆。父子节点下表有如下关系:
leftNo = parentNo*2+1
rightNo = parentNo*2+2
parentNo = (nodeNo-1)/2
通过上面的公式可以很轻松的根据某个节点计算出父节点和左右孩子节点。
四、常用方法
add()/offer()
其实add()方法内部也是调用了offer().下面是offer()的源码:
public boolean offer(E e) {
//不允许空
if (e == null)
throw new NullPointerException();
//modCount记录队列的结构变化次数。
modCount++;
int i = size;
//判断
if (i >= queue.length)
//扩容
grow(i + 1);
//size加1
size = i + 1;
if (i == 0)
queue[0] = e;
else
//不是第一次添加,调整树结构
siftUp(i, e);
return true;
}
我们可以知道:
- add()和offer()是不允许空值的插入。
- 和List一样,有fail-fast机制,会有modCount来记录队列的结构变化,在迭代和删除的时候校验,不通过会报ConcurrentModificationException。
- 判断当前元素size大于等于queue数组的长度,进行扩容。如果queue的大小小于64扩容为原来的两倍再加2,反之扩容为原来的1.5倍。
扩容函数源码如下:
private void grow(int minCapacity) {
int oldCapacity = queue.length;
// Double size if small; else grow by 50%
//如果queue的大小小于64扩容为原来的两倍再加2,反之扩容为原来的1.5倍
int newCapacity = oldCapacity + ((oldCapacity < 64) ?
(oldCapacity + 2) :
//右移一位
(oldCapacity >> 1));
// overflow-conscious code
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
queue = Arrays.copyOf(queue, newCapacity);
}
- 加入第一个元素时,queue[0] = e;以后加入元素内部数据结构会进行二叉树调整,维持最小堆的特性:调用siftUp(i, e):
private void siftUp(int k, E x) {
//比较器非空情况
if (comparator != null)
siftUpUsingComparator(k, x);
else
siftUpComparable(k, x);
}
//比较器非空情况
@SuppressWarnings("unchecked")
private void siftUpUsingComparator(int k, E x) {
while (k > 0) {
//利用堆的特性:parentNo = (nodeNo-1)/2
int parent = (k - 1) >>> 1;
Object e = queue[parent];
if (comparator.compare(x, (E) e) >= 0)
break;
queue[k] = e;
k = parent;
}
queue[k] = x;
}
上面的源码中可知:
- 利用堆的特点:parentNo = (nodeNo-1)/2 计算出父节点的下标,由此得到父节点:queue[parent];
- 如果插入的元素x大于父节点e那么循环退出,不做结构调整,x就插入在队列尾:queue[k] = x;
- 否则 queue[k] = e; k = parent; 父节点和加入的位置元素互换,如此循环,以维持最小堆。
下面是画的是向一个优先队列中添加(offer)一个元素过程的草图,以便理解:

poll(),获取并删除队列第一个元素
public E poll() {
if (size == 0)
return null;
//
int s = --size;
modCount++;
//获取队头元素
E result = (E) queue[0];
E x = (E) queue[s];
//将最后一个元素置空
queue[s] = null;
if (s != 0)
//如果不止一个元素,调整结构
siftDown(0, x);
//返回队头元素
return result;
}
删除元素,也得调整结构以维持优先队列内部数据结构为:堆
五、简单用法
下面是一段简单的事列代码,演示了自然排序和自定义排序的情况:
package com.good.good.study.queue;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.util.Comparator;
import java.util.PriorityQueue;
import java.util.Random;
/**
* @author monkjavaer
* @version V1.0
* @date 2019/6/16 0016 10:22
*/
public class PriorityQueueTest {
/**日志记录*/
private static final Logger logger = LoggerFactory.getLogger(PriorityQueueTest.class);
public static void main(String[] args) {
naturalOrdering();
personOrdering();
}
/**
* 自然排序
*/
private static void naturalOrdering(){
PriorityQueue<Integer> priorityQueue = new PriorityQueue<>();
Random random = new Random();
int size = 10;
for (int i =0;i<size;i++){
priorityQueue.add(random.nextInt(100));
}
for (int i =0;i<size;i++){
logger.info("第 {} 次取出元素:{}",i,priorityQueue.poll());
}
}
/**
* 自定义排序规则,根据人的年龄排序
*/
private static void personOrdering(){
PriorityQueue<Person> priorityQueue = new PriorityQueue<>(new Comparator<Person>() {
@Override
public int compare(Person o1, Person o2) {
return o1.getAge()-o2.getAge();
}
});
Random random = new Random();
int size = 10;
for (int i =0;i<size;i++){
priorityQueue.add(new Person(random.nextInt(100)));
}
while (true){
Person person = priorityQueue.poll();
if (person == null){
break;
}
logger.info("取出Person:{}",person.getAge());
}
}
}
六、应用场景
优先队列PriorityQueue常用于调度系统优先处理VIP用户的请求。多线程环境下我们需要使用PriorityBlockingQueue来处理此种问题,以及需要考虑队列数据持久化。
【Java源码】集合类-优先队列PriorityQueue的更多相关文章
- 【java集合框架源码剖析系列】java源码剖析之TreeSet
本博客将从源码的角度带领大家学习TreeSet相关的知识. 一TreeSet类的定义: public class TreeSet<E> extends AbstractSet<E&g ...
- 【java集合框架源码剖析系列】java源码剖析之HashSet
注:博主java集合框架源码剖析系列的源码全部基于JDK1.8.0版本.本博客将从源码角度带领大家学习关于HashSet的知识. 一HashSet的定义: public class HashSet&l ...
- 【笔记0-开篇】面试官系统精讲Java源码及大厂真题
背景 开始阅读 Java 源码的契机,还是在第一年换工作的时候,被大厂的技术面虐的体无完肤,后来总结大厂的面试套路,发现很喜欢问 Java 底层实现,即 Java 源码,于是我花了半年时间,啃下了 J ...
- Java源码赏析(三)初识 String 类
由于String类比较复杂,现在采用多篇幅来讲述 这一期主要从String使用的关键字,实现的接口,属性以及覆盖的方法入手.省略了大部分的字符串操作,比如split().trim().replace( ...
- 如何阅读Java源码 阅读java的真实体会
刚才在论坛不经意间,看到有关源码阅读的帖子.回想自己前几年,阅读源码那种兴奋和成就感(1),不禁又有一种激动. 源码阅读,我觉得最核心有三点:技术基础+强烈的求知欲+耐心. 说到技术基础,我打个比 ...
- Android反编译(一)之反编译JAVA源码
Android反编译(一) 之反编译JAVA源码 [目录] 1.工具 2.反编译步骤 3.实例 4.装X技巧 1.工具 1).dex反编译JAR工具 dex2jar http://code.go ...
- 如何阅读Java源码
刚才在论坛不经意间,看到有关源码阅读的帖子.回想自己前几年,阅读源码那种兴奋和成就感(1),不禁又有一种激动.源码阅读,我觉得最核心有三点:技术基础+强烈的求知欲+耐心. 说到技术基础,我打个比方吧, ...
- Java 源码学习线路————_先JDK工具包集合_再core包,也就是String、StringBuffer等_Java IO类库
http://www.iteye.com/topic/1113732 原则网址 Java源码初接触 如果你进行过一年左右的开发,喜欢用eclipse的debug功能.好了,你现在就有阅读源码的技术基础 ...
- Programming a Spider in Java 源码帖
Programming a Spider in Java 源码帖 Listing 1: Finding the bad links (CheckLinks.java) import java.awt. ...
- 解密随机数生成器(二)——从java源码看线性同余算法
Random Java中的Random类生成的是伪随机数,使用的是48-bit的种子,然后调用一个linear congruential formula线性同余方程(Donald Knuth的编程艺术 ...
随机推荐
- Junit测试集锦
Junit测试集锦 前言: 一个程序从设计很好的状态开始,随着新的功能不断地加入,程序逐渐地失去了原有的结构,最终变成了一团乱麻.所以在开发过程中,对于程序员来说,测试是非常重要的.言归正传,开始Ju ...
- IP地址 子网掩码 默认网关和DNS服务器的关系
在过去,男人是需要能够上房揭瓦的,是要能够修水管的.现在的男人是需要会装系统的,会设置路由器的.世界变化太快! 废话不多说,本文来讨论一下电脑上最为常见的几个网络参数:IP地址.子网掩码.默认网关和D ...
- Linux服务器用iotop命令分析服务器磁盘IO情况
Linux下的IO统计工具如iostat, nmon等大多数是只能统计到per设备的读写情况, 如果你想知道每个进程是如何使用IO的就比较麻烦.如果会systemtap, 或者blktrace这些事情 ...
- Ubuntu14.04 LTS安装 OpenCV-3.0.0-rc1 + QT5.4.1
I 安装配置工作前的准备 2 II 安装 OpenCV 2 III 安装QT 3 IV 使QT能够使用OpenCV 3 如果顺利,整个过程应该3个小时左右能够完成. 我整个过程用了一早上,配置过程中有 ...
- 小知识~VS2012的xamarin加载失败解决
1 由于Nuget版本过低导致的,工具->扩展和更新->在线更新->对nuget程序包程序器进行升级即可 错误代码: 错误 4 错误: 缺少来自类“NuGet.Visua ...
- Devops 技术图谱
- CortexA7工业级迅为-iMX6UL开发板硬件和资料介绍
商业级核心板 ARM Cortex-A7架构 主频高达528 MHz 核心板512M DDR内存 8G EMMC 存储 运行温度:-20℃ ~ +80℃ CPU集成电源管理 核心板尺寸仅:42mm*3 ...
- Spring AOP源码解析——专治你不会看源码的坏毛病!
昨天有个大牛说我啰嗦,眼光比较细碎,看不到重点.太他爷爷的有道理了!要说看人品,还是女孩子强一些. 原来记得看到一个男孩子的抱怨,说怎么两人刚刚开始在一起,女孩子在心里就已经和他过完了一辈子.哥哥们, ...
- Python基础2 列表 元祖 字符串 字典 集合 文件操作 -DAY2
本节内容 列表.元组操作 字符串操作 字典操作 集合操作 文件操作 字符编码与转码 1. 列表.元组操作 列表是我们最以后最常用的数据类型之一,通过列表可以对数据实现最方便的存储.修改等操作 定义列表 ...
- centos7 install vim8
centos7 install vim8 Git and dependency Git: https://github.com/vim/vim # yum install -y perl-devel ...