安装配置elasticsearch、安装elasticsearch-analysis-ik插件、mysql导入数据到elasticsearch、安装yii2-elasticsearch及使用
一、安装elasticsearch
获取elasticsearch的rpm:wget https://download.elastic.co/elasticsearch/release/org/elasticsearch/distribution/rpm/elasticsearch/2.4.1/elasticsearch-2.4.1.rpm
具体版本在es官网获取:https://www.elastic.co/downloads/past-releases
二、yum安装
yum -y install elasticsearch-2.4.1.rpm
三、配置
vim /etc/elasticsearch/elasticsearch.yml
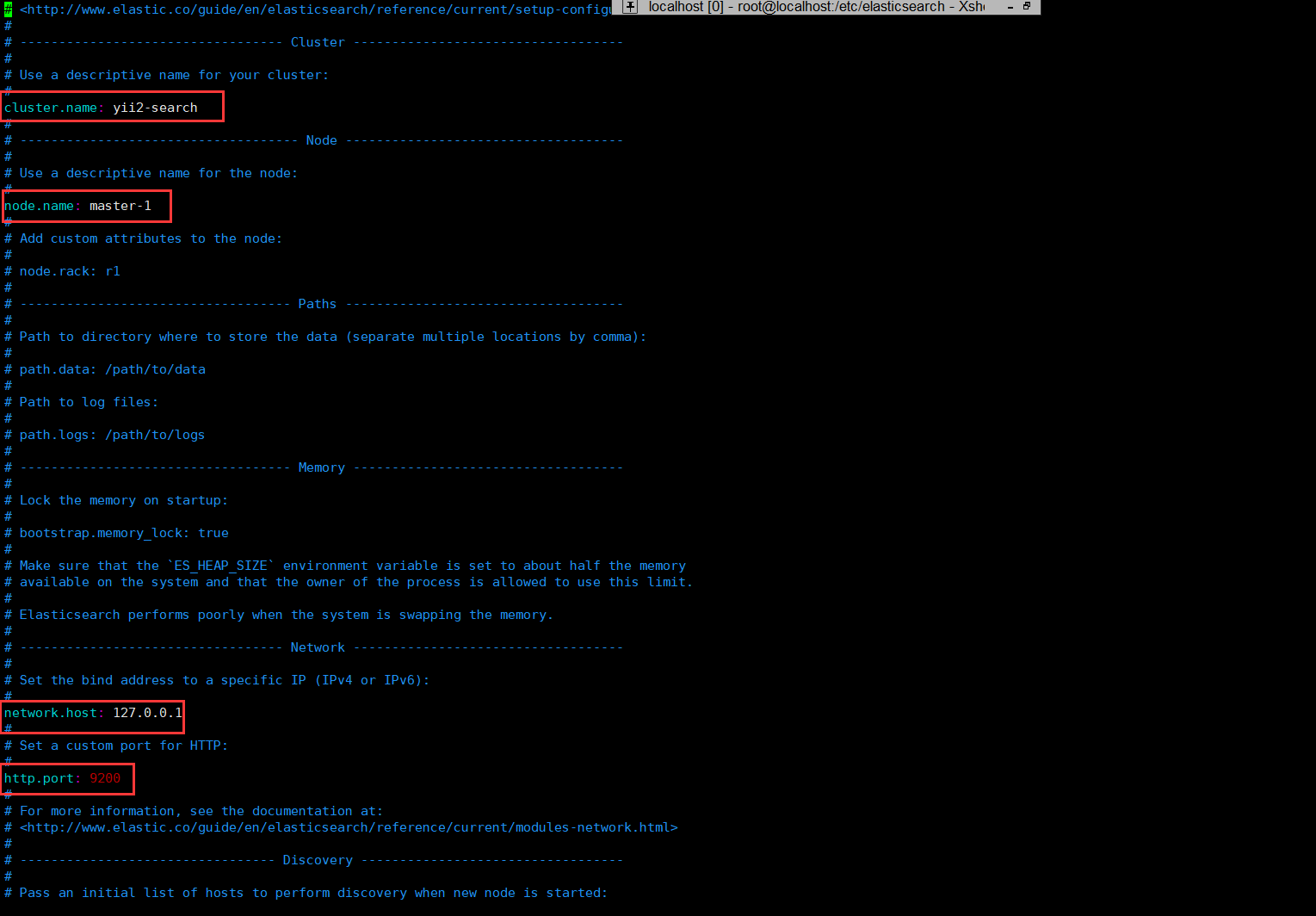
具体配置项可以参考es文档:https://www.elastic.co/guide/en/elasticsearch/reference/current/index.html
四、如果安装在虚拟机上,本地机可通过网络转发访问es
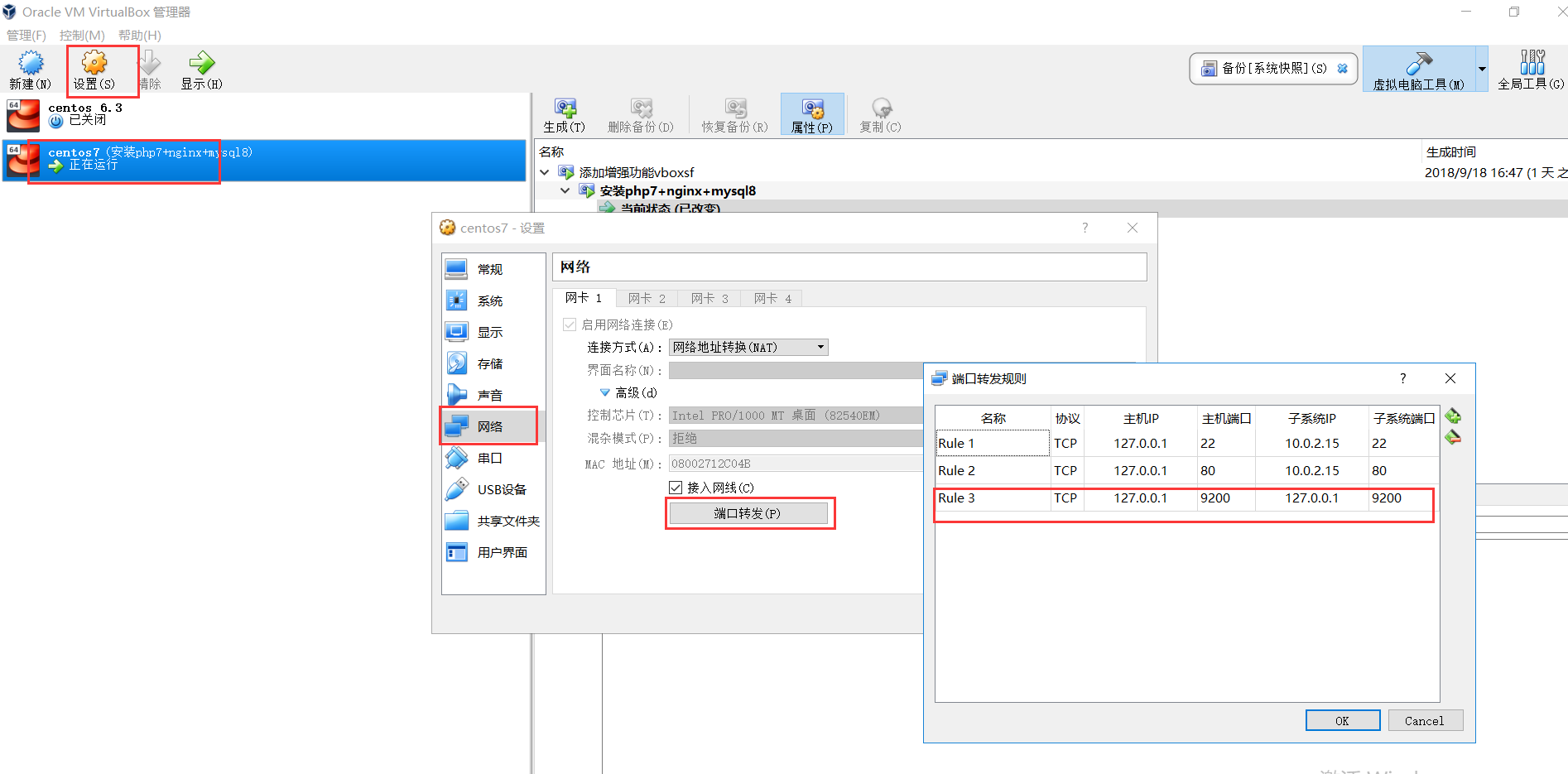
五、配置完后,开启es
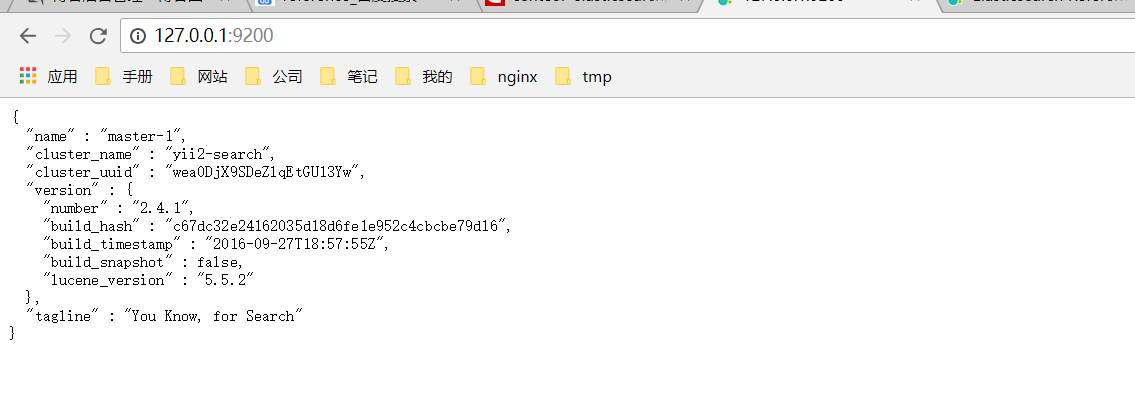
systemctl start elasticsearch,即可通过http://127.0.0.1:9200访问es
六、安装elasticsearch-analysis-ik插件(github路径:https://github.com/medcl/elasticsearch-analysis-ik),ik插件的作用是es的中文分词组件
1、git clone https://github.com/medcl/elasticsearch-analysis-ik.git(克隆到/usr/local/src下)
2、进入目录cd elasticsearch-analysis-ik/,然后执行git checkout tags/v1.10.1,具体要选择什么版本可查看github上的说明
3、执行mvn package(如果提示没有mvn命令,则执行yum -y install maven来下载)
下载后在/usr/local/src/elasticsearch-analysis-ik/target/releases下就会有elasticsearch-analysis-ik-1.10.1.zip包

4、在/usr/share/elasticsearch/plugins下创建ik文件夹,执行mkdir ik;
然后将/usr/local/src/elasticsearch-analysis-ik/target/releases/elasticsearch-analysis-ik-1.10.1.zip拷贝过来,
执行cp /usr/local/src/elasticsearch-analysis-ik/target/releases/elasticsearch-analysis-ik-1.10.1.zip /usr/share/elasticsearch/plugins/ik
5、进入/usr/share/elasticsearch/plugins/ik,执行cd /usr/share/elasticsearch/plugins/ik;
然后解压unzip elasticsearch-analysis-ik-1.10.1.zip
6、重启es,systemctl restart elasticsearch.service,到这里ik插件安装完成
7、测试ik组件,执行curl -XPOST "http://127.0.0.1:9200/_analyze?analyzer=ik&pretty" -d '这是一个商品标题'
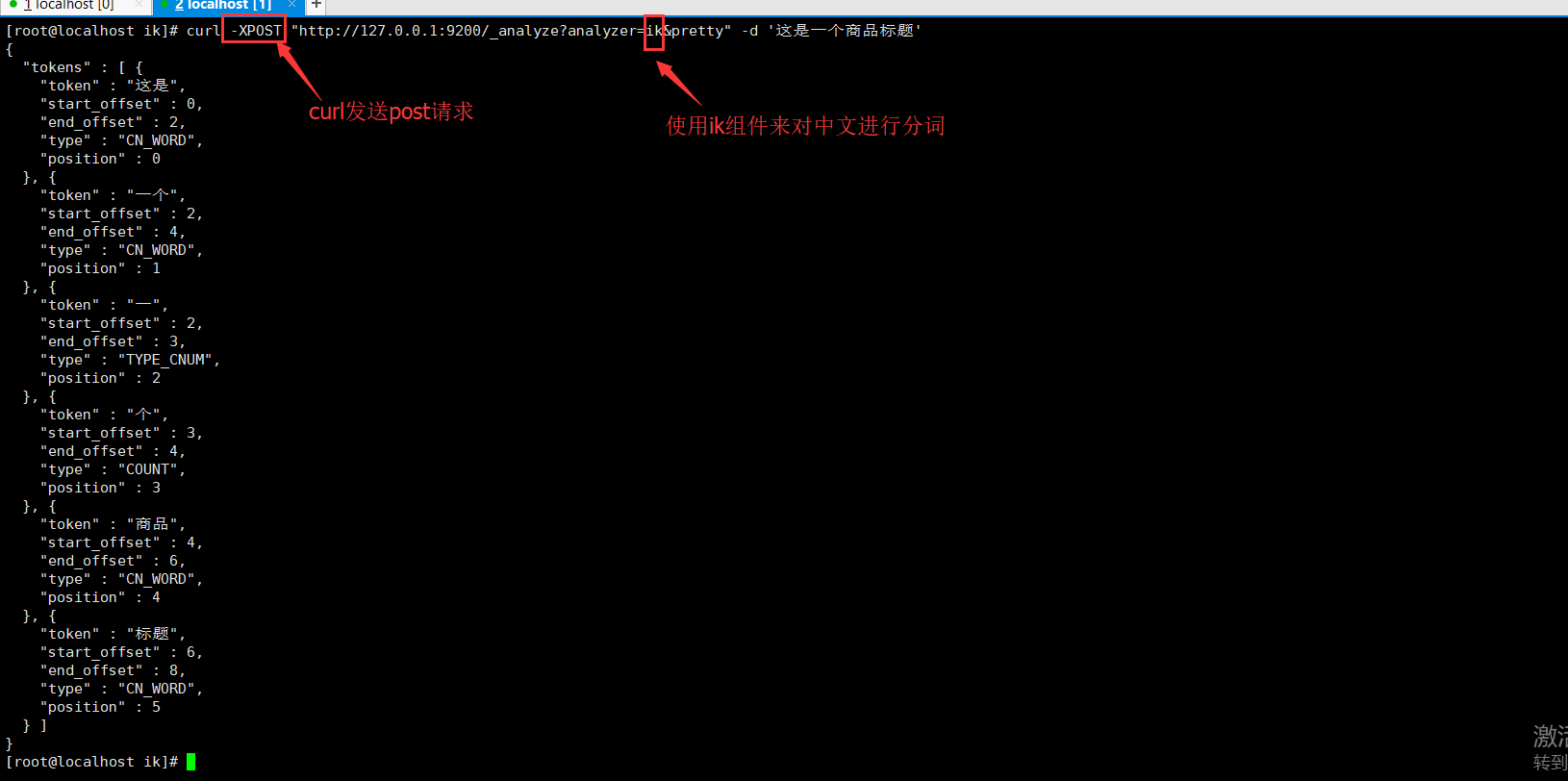
es默认分词格式为standard,执行curl -XPOST "http://127.0.0.1:9200/_analyze?analyzer=standard&pretty" -d '这是一个商品标题';即可和ik对比

七、mysql导入数据到elasticsearch,使用elasticsearch-jdbc,github路径:https://github.com/jprante/elasticsearch-jdbc
1、下载wget http://xbib.org/repository/org/xbib/elasticsearch/importer/elasticsearch-jdbc/2.3.4.0/elasticsearch-jdbc-2.3.4.0-dist.zip
2、解压unzip elasticsearch-jdbc-2.3.4.0-dist.zip
3、编辑配置文件
进入elasticsearch-jdbc-2.3.4.0,cd elasticsearch-jdbc-2.3.4.0
拷贝cp mysql-blog.sh mysql-import-product.sh
编辑mysql-import-product.sh
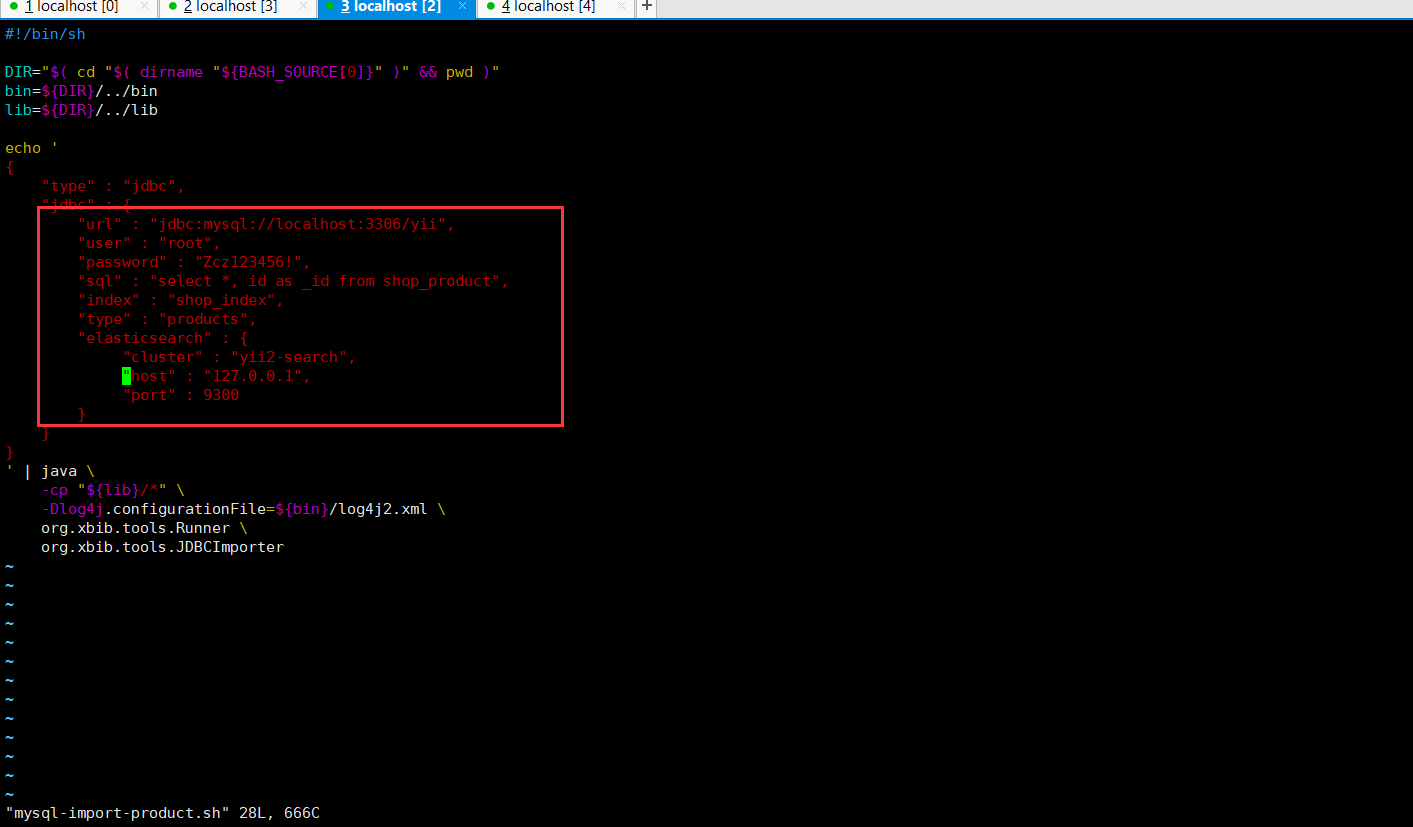
4、执行导入,./mysql-import-product.sh,如果没有报错,则数据导入elasticsearch成功
八、安装yii2-elasticsearch及使用
1、安装yii2-elasticsearch,yii2-elasticsearch在github路径:https://github.com/yiisoft/yii2-elasticsearch
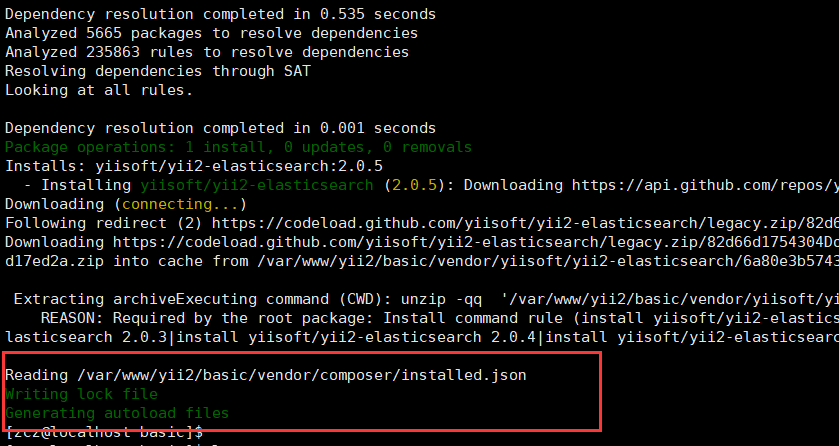
进入到yii2的basic目录,使用composer安装yii2-elasticsearch,执行composer require --prefer-dist yiisoft/yii2-elasticsearch:"~2.0.0" -vvv,成功返回如下内容:
2、编写model,继承的类改为yii\elasticsearch\ActiveRecord

3、在控制器中调用该model
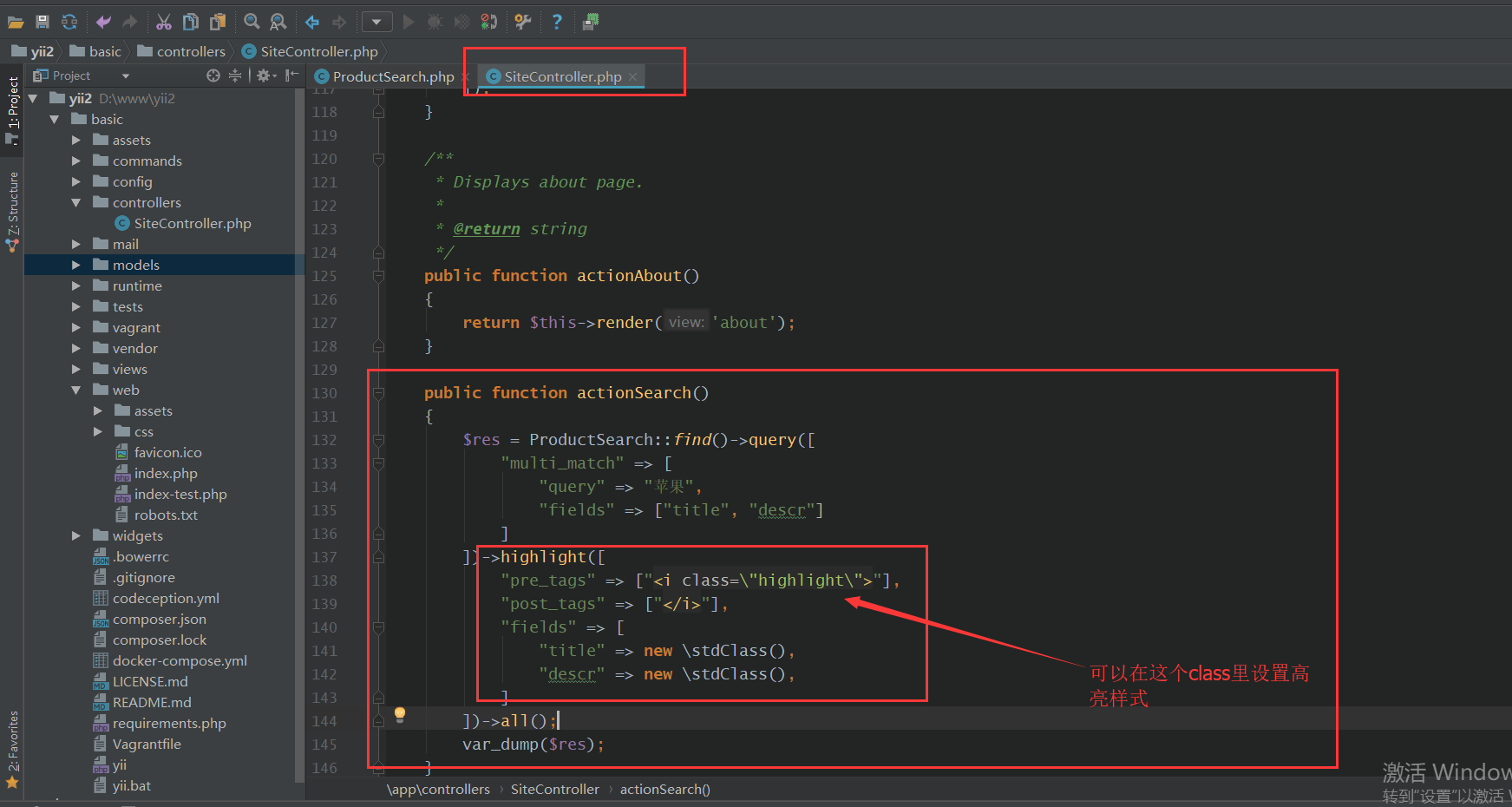
4、访问该方法,即可查询到elasticsearch中的内容

5、mysql增量导入es(即数据表有数据发生变动,增加数据或更改数据,都能对应将数据更新到es)
拷贝拷贝cp mysql-blog.sh mysql-delta-import-product.sh
编辑mysql-delta-import-product.sh如下:
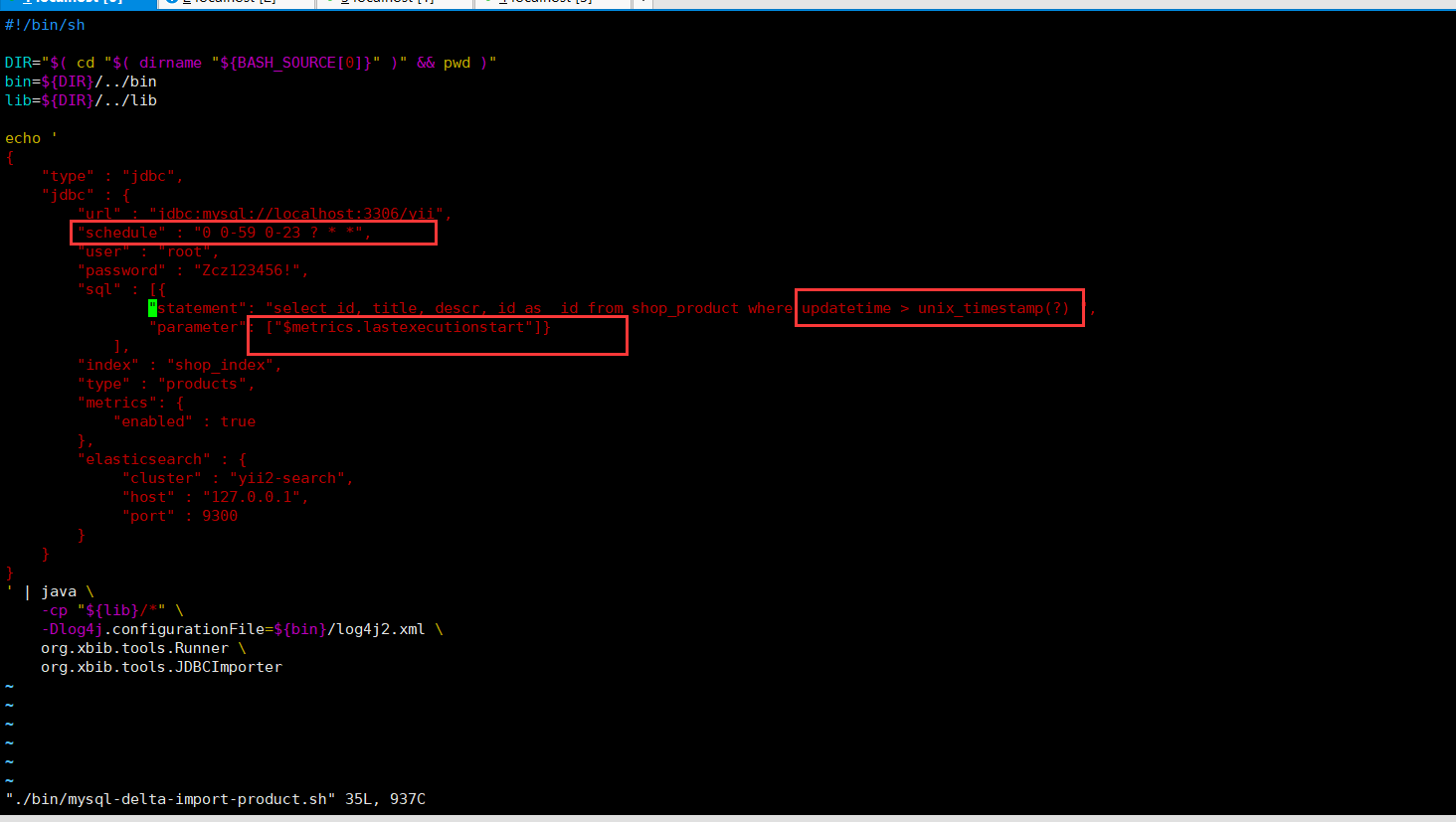
然后执行该sh文件,即可增量导入es
6、如果执行mysql-delta-import-product.sh时报错,错误提示为:Could not create connection to database server

查看lib文件夹下的文件可以找到mysql-connector-java-5.1.38.jar

因为我使用的是mysql-8.0.12,所以需要下载mysql-connector-java-8.0.12.jar,然后放置在lib下,重新执行mysql-delta-import-product.sh脚本即可解决问题
安装配置elasticsearch、安装elasticsearch-analysis-ik插件、mysql导入数据到elasticsearch、安装yii2-elasticsearch及使用的更多相关文章
- seata服务端和客户端配置(使用nacos进行注册发现,使用mysql进行数据持久化),以及过程中可能会出现的问题与解决方案
seata服务端和客户端配置(使用nacos进行注册发现,使用mysql进行数据持久化),以及过程中可能会出现的问题与解决方案 说明: 之所以只用nacos进行了注册与发现,因为seata使用naco ...
- Hive安装配置详解步骤以及hive使用mysql配置
Hive是一个数据仓库基础工具在Hadoop中用来处理结构化数据.它架构在Hadoop之上,总归为大数据,并使得查询和分析方便.并提供简单的sql查询功能,可以将sql语句转换为MapReduce任务 ...
- elasticsearch从mysql导入数据
详细:https://github.com/jprante/elasticsearch-jdbc(最下面有各数据库的导入方法说明) elasticsearch版本为1.5.2 1.下载 elastic ...
- [Linux] linux下安装配置 zookeeper/redis/solr/tomcat/IK分词器 详细实例.
今天 不知自己装的centos 出现了什么问题, 一直卡在 启动界面, 找了半天没找见原因(最后时刻还是发现原因, 只因自己手欠一怒之下将centos删除了, 而且选择的是在本地磁盘也删除. ..让我 ...
- CentOS和Ubuntu下安装配置Greenplum数据库集群(包括安装包和源码编译安装)
首先说一下,无论是CentOS/RedHat还是Ubuntu都可以按源码方式.安装包方式编译安装. 1. 规划 192.168.4.93(h93) 1个主master 2个主segm ...
- cdh版本的hue安装配置部署以及集成hadoop hbase hive mysql等权威指南
hue下载地址:https://github.com/cloudera/hue hue学习文档地址:http://archive.cloudera.com/cdh5/cdh/5/hue-3.7.0-c ...
- 关于MySQL导入数据到elasticsearch的小工具logstash
logstash核心配置文件pipelines.yml #注:此处的 - 必须顶格写必须!!! - pipeline.id: invitation #下面路径配置的是你同步数据是的字段映射关系 pat ...
- oracle12c:通过oracle客户端工具配置tns,并使用sqlldr进行批量导入数据
通过oracle客户端工具配置tns: 进入oracle配置工具“Net Configuration Assistant”-> 点击“下一步”,完成tns配置. 测试是否tns可用 命令:tns ...
- Linux系统中ElasticSearch搜索引擎安装配置Head插件
近几篇ElasticSearch系列: 1.阿里云服务器Linux系统安装配置ElasticSearch搜索引擎 2.Linux系统中ElasticSearch搜索引擎安装配置Head插件 3.Ela ...
随机推荐
- Linux下firefox安装flash player插件
下载插件 解压插件 使用命令tar -zxvf install_xxxxxx libflashplayer.so 拷贝目录 然后把切换到root用户,把文件夹拷贝到/usr/lib/mozilla/p ...
- 5位ID生成方案
最近在某微信技术群,有人问到如何生成5位唯一数字+字母字符串的算法,要保证生成的字符串唯一,且字符串内部也要唯一. 怎么样,这个需求是不是很简单,也有点特殊呢?简单是指需求简单,特殊是指,字符串长度要 ...
- iOS NSDictionary <--> NSString(JSON) in Objc
NSDictionary --> NSString + (NSString*)stringINJSONFormatForObject:(id)obj { NSData *jsonData = [ ...
- Caused by: java.lang.ClassNotFoundException: org.apache.log4j.Logger
myeclipse 新建web项目,报错Caused by: java.lang.ClassNotFoundException: org.apache.log4j.Logger,查看项目中已经有引入了 ...
- 题解报告:hdu 2059 龟兔赛跑
题目链接:http://acm.hdu.edu.cn/showproblem.php?pid=2059 Problem Description 据说在很久很久以前,可怜的兔子经历了人生中最大的打击—— ...
- HBase Region Assign流程详解
Hbase是kv存储,但是逻辑上我们可以把存储在hbase上的kv数据当成表,rowkey可以认为是表的主键.为了便于分布式操作,hbase会把表横向切分成一块一块的数据,而每块就是一个Region. ...
- AJPFX编写cmd界面下一键编译、执行java代码的bat脚本
此脚本适合刚接触java的同学,在cmd界面下用jc取代 复杂的 javac *.java + java main使用说明:把脚本内容复制到txt文本中,修改后缀名为.bat,运行一次即可完成配置, ...
- css3中content属性的应用
可以使用css3中content功能为html元素增减内容.content需要配合 E:before和E:after使用. 废话少说,看代码和效果说明: 第一种: css代码: #div1:befor ...
- uoj #15. 【NOIP2014】生活大爆炸版石头剪刀布
石头剪刀布是常见的猜拳游戏:石头胜剪刀,剪刀胜布,布胜石头.如果两个人出拳一 样,则不分胜负.在<生活大爆炸>第二季第 8 集中出现了一种石头剪刀布的升级版游戏. 升级版游戏在传统的石头剪 ...
- codevs 1082 线段树练习 3 --分块练习
时间限制: 3 s 空间限制: 128000 KB 题目等级 : 大师 Master 题目描述 Description 给你N个数,有两种操作: 1:给区间[a,b]的所有数增加X 2:询问区间[ ...