TensorFlow文本与序列的深度模型
TensorFlow深度学习笔记 文本与序列的深度模型
Deep Models for Text and Sequence
转载请注明作者:梦里风林
Github工程地址:https://github.com/ahangchen/GDLnotes
欢迎star,有问题可以到Issue区讨论
官方教程地址
视频/字幕下载
Rare Event
与其他机器学习不同,在文本分析里,陌生的东西(rare event)往往是最重要的,而最常见的东西往往是最不重要的。
语法多义性
- 一个东西可能有多个名字,对这种related文本能够做参数共享是最好的
- 需要识别单词,还要识别其关系,就需要过量label数据
无监督学习
- 不用label进行训练,训练文本是非常多的,关键是要找到训练的内容
- 遵循这样一个思想:相似的词汇出现在相似的场景中
- 不需要知道一个词真实的含义,词的含义由它所处的历史环境决定
Embeddings
- 将单词映射到一个向量(Word2Vec),越相似的单词的向量会越接近
- 新的词可以由语境得到共享参数
Word2Vec
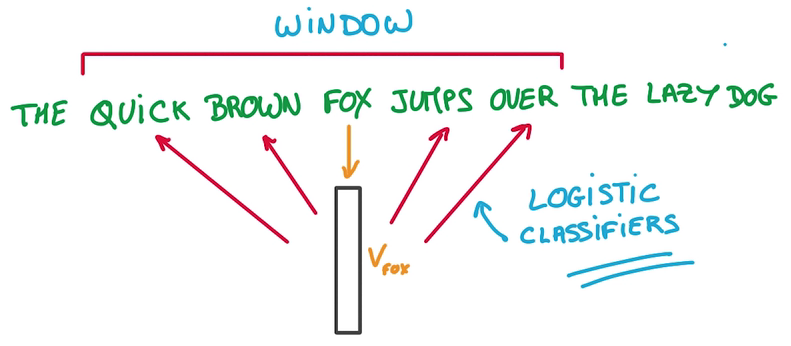
- 将每个词映射到一个Vector列表(就是一个Embeddings)里,一开始随机,用这个Embedding进行预测
- Context即Vector列表里的邻居
- 目标是让Window里相近的词放在相邻的位置,即预测一个词的邻居
用来预测这些相邻位置单词的模型只是一个Logistics Regression, just a simple Linear model
Comparing embeddings
比较两个vector之间的夹角大小来判断接近程度,用cos值而非L2计算,因为vector的长度和分类是不相关的:
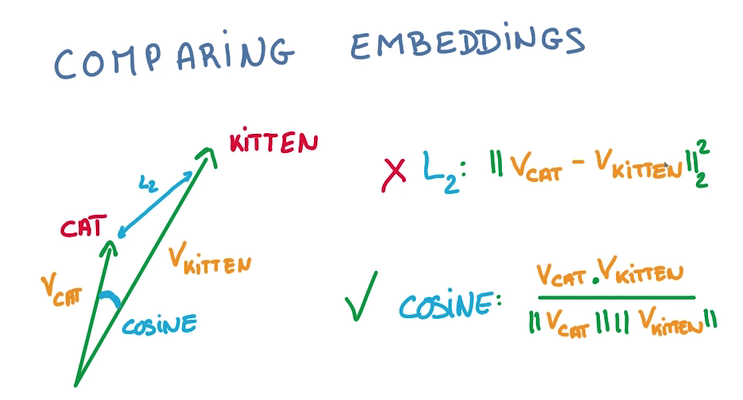
- 最好将要计算的vector都归一化
Predict Words
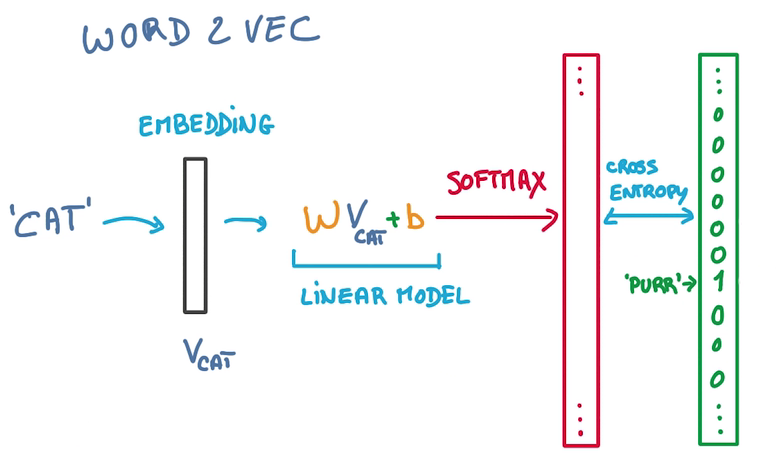
- 单词经过embedding变成一个vector
- 然后输入一个WX+b,做一个线性模型
- 输出的label概率为输入文本中的词汇
- 问题在于WX+b输出时,label太多了,计算这种softmax很低效
- 解决方法是,筛掉不可能是目标的label,只计算某个label在某个局部的概率,sample softmax
t-SNE
- 查看某个词在embedding里的最近邻居可以看到单词间的语义接近关系
- 将vector构成的空间降维,可以更高效地查找最近单词,但降维过程中要保持邻居关系(原来接近的降维后还要接近)
- t-SNE就是这样一种有效的方法
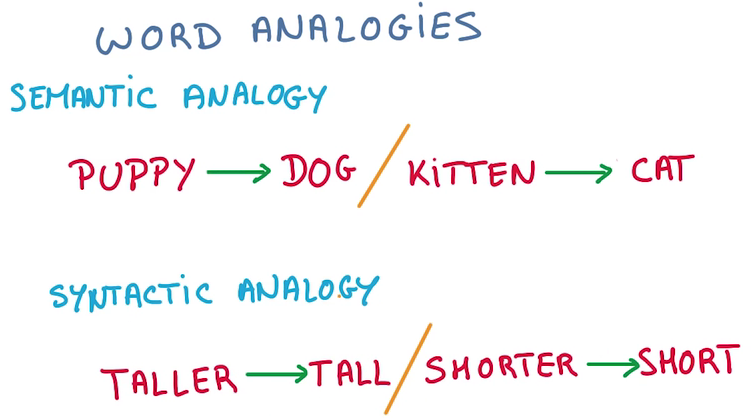
类比
- 实际上我们能得到的不仅是单词的邻接关系,由于将单词向量化,可以对单词进行计算
- 可以通过计算进行语义加减,语法加减

Sequence
文本(Text)是单词(word)的序列,一个关键特点是长度可变,就不能直接变为vector
CNN and RNN
CNN 在空间上共享参数,RNN在时间上(顺序上)共享参数
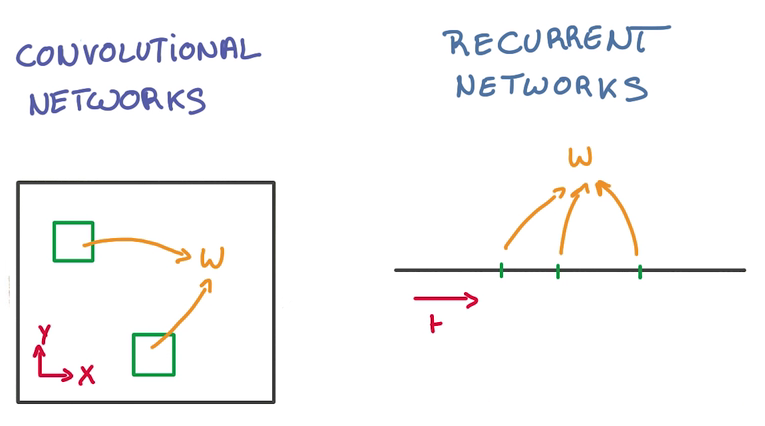
- 在每轮训练中,需要判断至今为之发生了什么,过去输入的所有数据都对当下的分类造成影响
- 一种思路是记忆之前的分类器的状态,在这个基础上训练新的分类器,从而结合历史影响
- 这样需要大量历史分类器
- 重用分类器,只用一个分类器总结状态,其他分类器接受对应时间的训练,然后传递状态
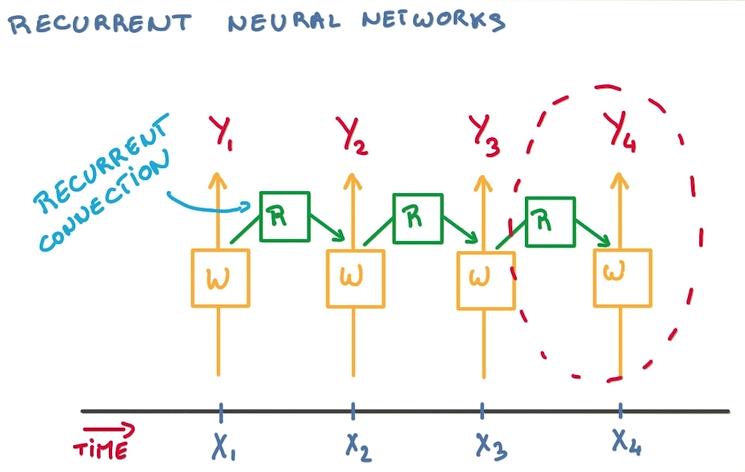
RNN Derivatives
- BackPropagation Through time
- 对同一个weight参数,会有许多求导操作同时更新之
- 对SGD不友好,因为SGD是用许多不相关的求导更新参数,以保证训练的稳定性
- 由于梯度之间的相关性,导致梯度爆炸或者梯度消失
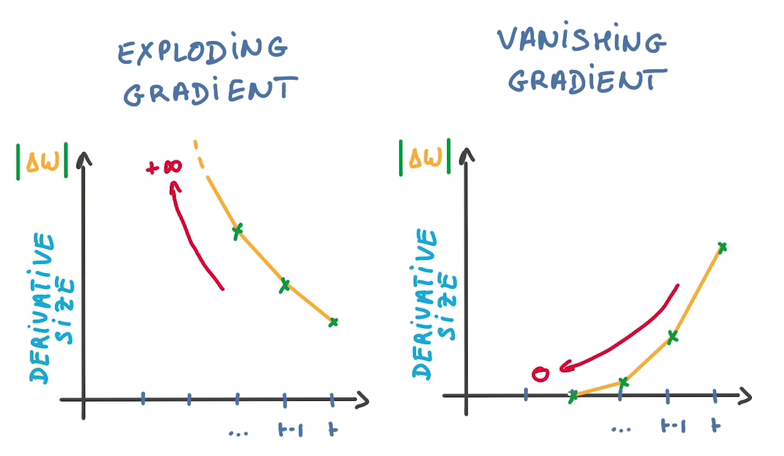
- 使得训练时找不到优化方向,训练失败
Clip Gradient
计算到梯度爆炸的时候,使用一个比值来代替△W(梯度是回流计算的,横坐标从右往左看)
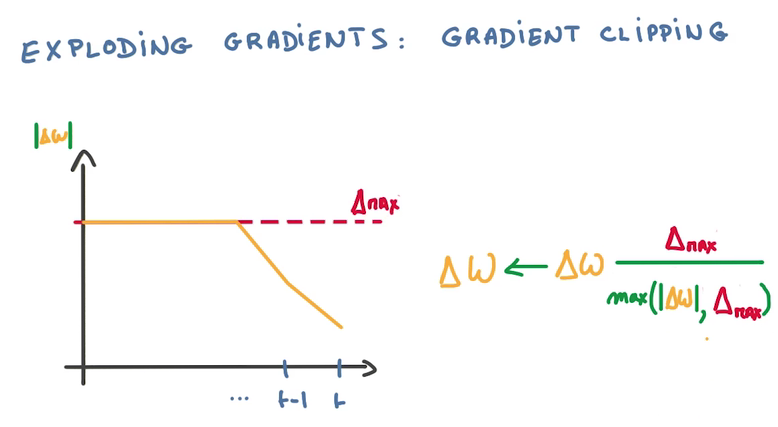
- Hack but cheap and effective
LSTM(Long Short-Term Memory)
梯度消失会导致分类器只对最近的消息的变化有反应,淡化以前训练的参数,也不能用比值的方法来解决
- 一个RNN的model包含两个输入,一个是过去状态,一个是新的数据,两个输出,一个是预测,一个是将来状态
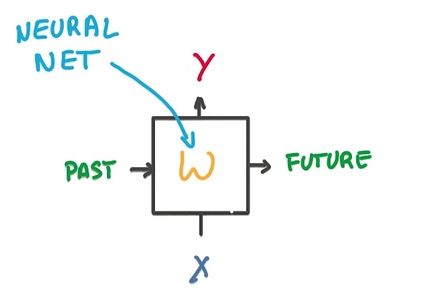
- 中间是一个简单的神经网络
- 将中间的部分换成LSTM-cell就能解决梯度消失问题
- 我们的目的是提高RNN的记忆能力
- Memory Cell

三个门,决定是否写/读/遗忘/写回
- 在每个门上,不单纯做yes/no的判断,而是使用一个权重,决定对输入的接收程度
- 这个权重是一个连续的函数,可以求导,也就可以进行训练,这是LSTM的核心

- 用一个逻辑回归训练这些门,在输出进行归一化
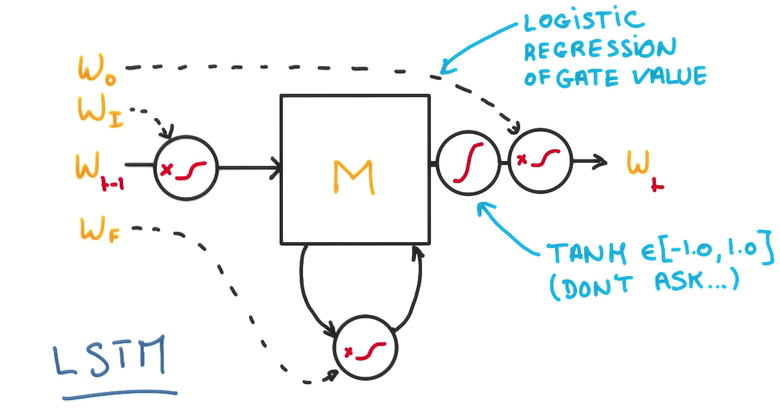
- 这样的模型能让整个cell更好地记忆与遗忘
- 由于整个模型都是线性的,所以可以方便地求导和训练
LSTM Regularization
- L2, works
- Dropout on the input or output of data, works
Beam Search
有了上面的模型之后,我们可以根据上文来推测下文,甚至创造下文,预测,筛选最大概率的词,喂回,继续预测……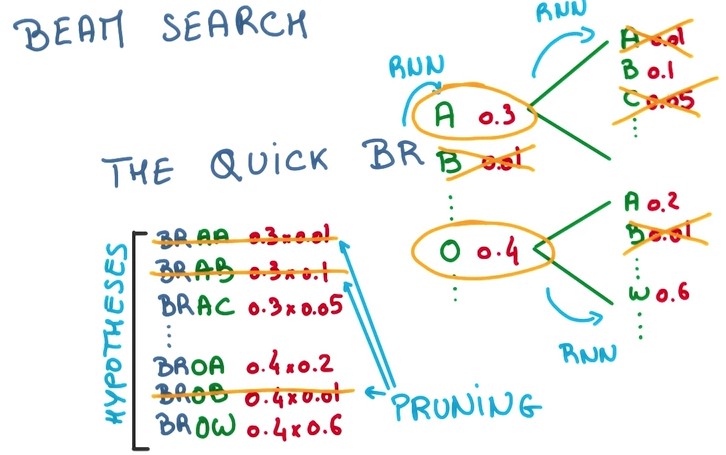
- 我们可以每次只预测一个字母,but this is greedy,每次都挑最好的那个
- 也可以每次多预测几步,然后挑整体概率较高的那个,以减少偶然因素的影响
- 但这样需要生成的sequence会指数增长
- 因此我们在多预测几步的时候,只为概率比较高的几个候选项做预测,that's beam search.
翻译与识图
RNN将variable length sequence问题变成了fixed length vector问题,同时因为实际上我们能利用vector进行预测,我们也可以将vector变成sequence
- 我们可以利用这一点,输入一个序列,到一个RNN里,将输出输入到另一个逆RNN序列,形成另一种序列,比如,语言翻译
如果我们将CNN的输出接到一个RNN,就可以做一种识图系统
循环神经网络实践
TensorFlow文本与序列的深度模型的更多相关文章
- TensorFlow深度学习笔记 文本与序列的深度模型
Deep Models for Text and Sequence 转载请注明作者:梦里风林 Github工程地址:https://github.com/ahangchen/GDLnotes 欢迎st ...
- TensorFlow文本情感分析实现
TensorFlow文本情感分析实现 前面介绍了如何将卷积网络应用于图像.本文将把相似的想法应用于文本. 文本和图像有什么共同之处?乍一看很少.但是,如果将句子或文档表示为矩阵,则该矩阵与其中每个单元 ...
- 代码详解:TensorFlow Core带你探索深度神经网络“黑匣子”
来源商业新知网,原标题:代码详解:TensorFlow Core带你探索深度神经网络“黑匣子” 想学TensorFlow?先从低阶API开始吧~某种程度而言,它能够帮助我们更好地理解Tensorflo ...
- [重磅]Deep Forest,非神经网络的深度模型,周志华老师最新之作,三十分钟理解!
欢迎转载,转载请注明:本文出自Bin的专栏blog.csdn.net/xbinworld. 技术交流QQ群:433250724,欢迎对算法.技术感兴趣的同学加入. 深度学习最大的贡献,个人认为就是表征 ...
- 从TensorFlow 到 Caffe2:盘点深度学习框架
机器之心报道 本文首先介绍GitHub中最受欢迎的开源深度学习框架排名,然后再对其进行系统地对比 下图总结了在GitHub中最受欢迎的开源深度学习框架排名,该排名是基于各大框架在GitHub里的收藏数 ...
- NNs(Neural Networks,神经网络)和Polynomial Regression(多项式回归)等价性之思考,以及深度模型可解释性原理研究与案例
1. Main Point 0x1:行文框架 第二章:我们会分别介绍NNs神经网络和PR多项式回归各自的定义和应用场景. 第三章:讨论NNs和PR在数学公式上的等价性,NNs和PR是两个等价的理论方法 ...
- NLP大赛冠军总结:300万知乎多标签文本分类任务(附深度学习源码)
NLP大赛冠军总结:300万知乎多标签文本分类任务(附深度学习源码) 七月,酷暑难耐,认识的几位同学参加知乎看山杯,均取得不错的排名.当时天池AI医疗大赛初赛结束,官方正在为复赛进行平台调 ...
- 三分钟快速上手TensorFlow 2.0 (下)——模型的部署 、大规模训练、加速
前文:三分钟快速上手TensorFlow 2.0 (中)——常用模块和模型的部署 TensorFlow 模型导出 使用 SavedModel 完整导出模型 不仅包含参数的权值,还包含计算的流程(即计算 ...
- hadoop文本转换为序列文件
在以前使用hadoop的时候因为mahout里面很多都要求输入文件时序列文件,所以涉及到把文本文件转换为序列文件或者序列文件转为文本文件(因为当时要分析mahout的源码,所以就要看到它的输入文件是什 ...
随机推荐
- Push segues can only be used when the.....
刚刚遇到的两个错误,. 1, Terminating app due to uncaught exception'NSGenericException', reason: 'Push segues c ...
- 在TreeWidget中增加右键菜单功能 以及TreeWidget的基本用法
TreeWidget 与 TreeView 中实现右键菜单稍有不同, TreeView 中是靠信号与槽 connect(ui->treeView,SIGNAL(customContextMenu ...
- Java并发编程总结2——慎用CAS(转)
一.CAS和synchronized适用场景 1.对于资源竞争较少的情况,使用synchronized同步锁进行线程阻塞和唤醒切换以及用户态内核态间的切换操作额外浪费消耗cpu资源:而CAS基于硬件实 ...
- HDU 2393 Higher Math
#include <cstdio> #include <string> using namespace std; void swap(int& a,int& b ...
- mac下配置cocos2d-x3.0
今天看到3.0的正式版公布了,就马上荡下来试试3.0,以下记录下环境变量配置过程 打开用户文件夹下.bash_profile文件,配置环境 1.首先配置下android sdk,我的是在opt文件夹下 ...
- asp.net生成RSS
经常看到博客.还有很多网站中有RSS订阅,今天就来玩玩asp.net生成RSS,在网上查找了相关资料 发现just soso,如下: aspx <?xml version="1.0&q ...
- Light OJ 1104 Birthday Pardo(生日悖论)
ime Limit:2000MS Memory Limit:32768KB 64bit IO Format:%lld & %llu Description Sometime ...
- 五毛的cocos2d-x学习笔记02-基本项目源码分析
class AppDelegate : private cocos2d::Application private表示私有继承,cocs2d是一个命名空间.私有继承下,Application类中的pri ...
- UrlEncode编码/UrlDecode解码
public class encode { public static void main(String[] args) throws UnsupportedEncodingException ...
- KVM镜像管理利器-guestfish使用详解
原文 http://xiaoli110.blog.51cto.com/1724/1568307 KVM镜像管理利器-guestfish使用详解 本文介绍以下内容: 1. 虚拟机镜像挂载及w2k8 ...