Hive集成HBase详解

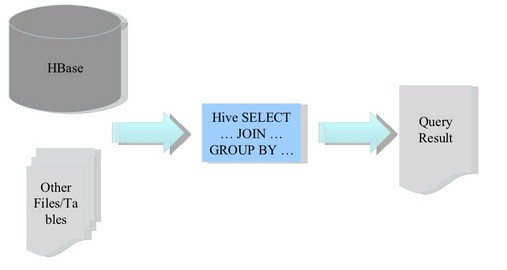
- 使用HQL语句创建一个指向HBase的Hive表
CREATE TABLE hbase_table_1(key int, value string) //Hive中的表名hbase_table_1
STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler' //指定存储处理器
WITH SERDEPROPERTIES ("hbase.columns.mapping" = ":key,cf1:val") //声明列族,列名
TBLPROPERTIES ("hbase.table.name" = "xyz", "hbase.mapred.output.outputtable" = "xyz");
//hbase.table.name声明HBase表名,为可选属性默认与Hive的表名相同,
//hbase.mapred.output.outputtable指定插入数据时写入的表,如果以后需要往该表插入数据就需要指定该值
- 通过HBase shell可以查看刚刚创建的HBase表的属性
$ hbase shell
HBase Shell; enter 'help<RETURN>' for list of supported commands.
Version: 0.20.3, r902334, Mon Jan 25 13:13:08 PST 2010
hbase(main):001:0> list
xyz
1 row(s) in 0.0530 seconds
hbase(main):002:0> describe "xyz"
DESCRIPTION ENABLED
{NAME => 'xyz', FAMILIES => [{NAME => 'cf1', COMPRESSION => 'NONE', VE true
RSIONS => '3', TTL => '2147483647', BLOCKSIZE => '65536', IN_MEMORY =>
'false', BLOCKCACHE => 'true'}]}
1 row(s) in 0.0220 seconds
hbase(main):003:0> scan "xyz"
ROW COLUMN+CELL
0 row(s) in 0.0060 seconds
- 使用HQL向HBase表中插入数据
INSERT OVERWRITE TABLE hbase_table_1 SELECT * FROM pokes WHERE foo=98;
- 在HBase端查看插入的数据
hbase(main):009:0> scan "xyz"
ROW COLUMN+CELL
98 column=cf1:val, timestamp=1267737987733, value=val_98
1 row(s) in 0.0110 seconds
- 创建一个指向已经存在的HBase表的Hive表
CREATE EXTERNAL TABLE hbase_table_2(key int, value string)
STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
WITH SERDEPROPERTIES ("hbase.columns.mapping" = "cf1:val")
TBLPROPERTIES("hbase.table.name" = "some_existing_table", "hbase.mapred.output.outputtable" = "some_existing_table");
- 建表或映射表的时候如果没有指定:key则第一个列默认就是行键
- HBase对应的Hive表中没有时间戳概念,默认返回的就是最新版本的值
- 由于HBase中没有数据类型信息,所以在存储数据的时候都转化为String类型
CREATE TABLE hbase_table_1(key int, value1 string, value2 int, value3 int)
STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
WITH SERDEPROPERTIES (
"hbase.columns.mapping" = ":key,a:b,a:c,d:e"
);
INSERT OVERWRITE TABLE hbase_table_1 SELECT foo, bar, foo+1, foo+2
FROM pokes WHERE foo=98 OR foo=100;
CREATE TABLE hbase_table_1(value map<string,int>, row_key int)
STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
WITH SERDEPROPERTIES (
"hbase.columns.mapping" = "cf:,:key"
);
INSERT OVERWRITE TABLE hbase_table_1 SELECT map(bar, foo), foo FROM pokes
WHERE foo=98 OR foo=100;
- 在HBase下查看数据
hbase(main):012:0> scan "hbase_table_1"
ROW COLUMN+CELL
100 column=cf:val_100, timestamp=1267739509194, value=100
98 column=cf:val_98, timestamp=1267739509194, value=98
2 row(s) in 0.0080 seconds
- 在Hive下查看数据
hive> select * from hbase_table_1;
Total MapReduce jobs = 1
Launching Job 1 out of 1
...
OK
{"val_100":100} 100
{"val_98":98} 98
Time taken: 3.808 seconds
CREATE TABLE hbase_table_1(key int, value map<int,int>)
STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
WITH SERDEPROPERTIES (
"hbase.columns.mapping" = ":key,cf:"
);
CREATE TABLE hbase_table_1(key int, value string)
STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
WITH SERDEPROPERTIES (
"hbase.columns.mapping" = ":key,cf:"
);
CREATE EXTERNAL TABLE delimited_example(key struct<f1:string, f2:string>, value string)
ROW FORMAT DELIMITED
COLLECTION ITEMS TERMINATED BY '~'
STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
WITH SERDEPROPERTIES (
'hbase.columns.mapping'=':key,f:c1');
- 对HBase表进行预分区,增大其MapReduce作业的并行度
- 合理的设计rowkey使其尽可能的分布在预先分区好的Region上
- 通过set hbase.client.scanner.caching设置合理的扫描缓存
参考资料:
Hive集成HBase详解的更多相关文章
- 图解大数据 | 海量数据库查询-Hive与HBase详解
作者:韩信子@ShowMeAI 教程地址:http://www.showmeai.tech/tutorials/84 本文地址:http://www.showmeai.tech/article-det ...
- 大数据Hadoop核心架构HDFS+MapReduce+Hbase+Hive内部机理详解
微信公众号[程序员江湖] 作者黄小斜,斜杠青年,某985硕士,阿里 Java 研发工程师,于 2018 年秋招拿到 BAT 头条.网易.滴滴等 8 个大厂 offer,目前致力于分享这几年的学习经验. ...
- Hadoop核心架构HDFS+MapReduce+Hbase+Hive内部机理详解
转自:http://blog.csdn.net/iamdll/article/details/20998035 分类: 分布式 2014-03-11 10:31 156人阅读 评论(0) 收藏 举报 ...
- Hive集成HBase;安装pig
Hive集成HBase 配置 将hive的lib/中的HBase.jar包用实际安装的Hbase的jar包替换掉 cd /opt/hive/lib/ ls hbase-0.94.2* rm -rf ...
- [转帖]HBase详解(很全面)
HBase详解(很全面) very long story 简单看了一遍 很多不明白的地方.. 2018-06-08 16:12:32 卢子墨 阅读数 34857更多 分类专栏: HBase [转自 ...
- 安卓集成发布详解(二)gradle
转自:http://frank-zhu.github.io/android/2015/06/15/android-release_app_build_gradle/ 安卓集成发布详解(二) 15 Ju ...
- Hadoop Hive sql语法详解
Hadoop Hive sql语法详解 Hive 是基于Hadoop 构建的一套数据仓库分析系统,它提供了丰富的SQL查询方式来分析存储在Hadoop 分布式文件系统中的数据,可以将结构 化的数据文件 ...
- 最佳实战Docker持续集成图文详解
最佳实战Docker持续集成图文详解 这是一种真正的容器级的实现,这个带来的好处,不仅仅是效率的提升,更是一种变革:开发人员第一次真正为自己的代码负责——终于可以跳过运维和测试部门,自主维护运行环境( ...
- Hive的配置详解和日常维护
Hive的配置详解和日常维护 一.Hive的参数配置详解 1>.mapred.reduce.tasks 默认为-1.指定Hive作业的reduce task个数,如果保留默认值,则Hive 自 ...
随机推荐
- Spring + mybatis整合方案总结 结合实例应用
Spring + mybatis整合实例应用 项目结构图 (Spring3.0.2 +mybatis3.0.4) 方案一: 通过配置文件整合Spring和mybatis 应用数据库 -- --数据库 ...
- Lenovo k860i 移植Android 4.4 cm11进度记录【下篇--实时更新中】
2014.8.24 k860i的cm11的移植在中断了近两三个月之后又開始继续了,进度记录的日志上一篇已经没什么写的了,就完结掉它吧,又一次开一篇日志做下篇好了.近期的战况是,在scue同学的努力之下 ...
- SuperSocket快速入门(二):启动程序以及相关的配置
如何快速启动第一个程序 既然是快速入门,所以,对于太深奥的知识点将不做讲解,会在后续的高级应用章节中,会对SS进行拆解.所有的实例90%都是来自SS的实例,外加本人的注释进行讲解. 一般应用而言,你只 ...
- css float父元素高度塌陷
css float父元素高度塌陷 float 使父元素高度塌陷不是BUG,反而是标准. float 原本是为了解决文字环绕才出现的. 当然有的时候要解决高度塌陷的问题 以下几个方法可以解决float ...
- HTML5 格式化、样式、链接、表格
HTML格式化.样式.链接.表格的使用举例
- Request.ServerVariables 服务器环境变量
Request.ServerVariables["Url"] 返回服务器地址 Request.ServerVariables["Path_Info"] 客户端提 ...
- Lambda表达式 - 浅谈
概述: 只要有委托参数类型的地方,就可以使用 Lambda表达式.在讲述Lambda表达式之前,有必要先简要说明一下 委托中的"匿名方法": using System; using ...
- DataTable循环删除行
1.如果只是想删除datatable中的一行,可以用DataRow的delete,但是必须要删除后让DataTable知道,所以就要用 到.AcceptChanges()方法,原因是这种删除只是标识性 ...
- java下io文件切割合并功能
package cn.stat.p1.file; import java.io.File; import java.io.FileInputStream; import java.io.FileNot ...
- js判断一个变量是否为数组的解决方案
前端开发中,在做项目的时候,我们经常需要对一个变量进行数组类型的判断,当然即使你暂时没遇到,但是这个问题也是大家去面试时的高频问题,有必要拿出来说一说. 大家都知道js中可以使用typeof来判断变量 ...