线索二叉树的详细实现(C++)
线索二叉树概述
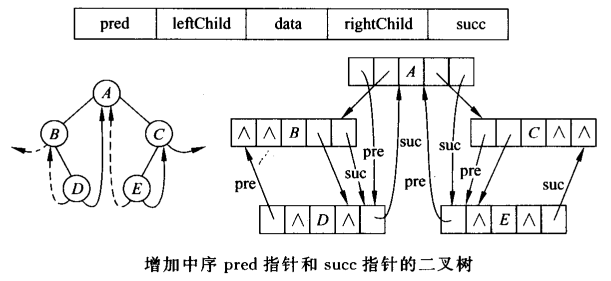

寻找当前结点在中序下的后继

寻找当前结点在中序序列下的前驱

线索二叉树的结点类
//线索二叉树结点类
template<typename T>
struct ThreadNode //结点类
{
int ltag, rtag; //左右子树标志位
ThreadNode<T> *leftChild, *rightChild; //左孩子和右孩子
T data; //结点存储的值
ThreadNode(const T item) :data(item), leftChild(NULL), rightChild(NULL), ltag(), rtag() {} //结点类的构造函数
};
线索二叉树的创建
//使用前序遍历创建二叉树(未线索化)
void CreateTree(ThreadNode<T>* &subTree)
{
T item;
if (cin >> item)
{
if (item != RefValue)
{
subTree = new ThreadNode<T>(item); //构造结点
if (subTree == NULL)
{
cout << "空间分配错误!" << endl;
exit();
}
CreateTree(subTree->leftChild); //递归创建左子树
CreateTree(subTree->rightChild); //递归创建右子树
}
else
{
subTree == NULL;
}
}
} //中序遍历对二叉树进行线索化
void createInThread(ThreadNode<T> *current, ThreadNode<T> * &pre)
{
if (current == NULL)
{
return;
}
createInThread(current->leftChild, pre); //递归左子树的线索化
if (current->leftChild == NULL) //建立当前结点的前驱结点
{
current->leftChild = pre;
current->ltag = ;
}
if (pre != NULL&&pre->rightChild == NULL) //建立当前结点的后继结点
{
pre->rightChild = current;
pre->rtag = ;
}
pre = current; //用前驱记住当前的结点
createInThread(current->rightChild, pre); //递归右子树的线索化
} //中序遍历对创建好的普通二叉树进行中序线索化
void CreateInThread()
{
ThreadNode<T> *pre = NULL; //第一个结点的左子树置为NULL
if (root != NULL) {
createInThread(root, pre);
//处理中序遍历的最后一个结点,最后一个结点的右子树置为空
pre->rightChild = NULL;
pre->rtag = ;
}
}
中序线索化二叉树的成员函数
//寻找中序下第一个结点
ThreadNode<T> * First(ThreadNode<T> *current)
//返回以*current为根的中序线索二叉树中序遍历的第一个结点
{
ThreadNode<T> *p = current;
while (p->ltag == )
{
p = p->leftChild; //循环找到最左下角结点
}
return p;
} //寻找中序下的后继结点
ThreadNode<T>* Next(ThreadNode<T>* current)
{
ThreadNode<T>* p = current->rightChild;
if(current->rtag==)
{
return First(p);
}
else
{
return p;
}
} //寻找中序下最后一个结点
ThreadNode<T> * Last(ThreadNode<T> *current)
//返回以*current为根的中序线索二叉树中序遍历的最后一个结点
{
ThreadNode<T> *p = current;
while (p->rtag==)
{
p = p->rightChild;
}
return p;
} //寻找结点在中序下的前驱结点
ThreadNode<T>* Prior(ThreadNode<T>* current)
{
ThreadNode<T>* p = current->leftChild;
if (current->ltag==)
{
return Last(p);
}
else
{
return p;
}
}
中序线索化二叉树上执行中序遍历的算法
//中序线索化二叉树上执行中序遍历的算法
void InOrder(ThreadNode<T>* p)
{
for (p=First(root);p!=NULL;p=Next(p))
{
cout << p->data<<" ";
}
cout << endl;
}
中序线索化二叉树上实现前序遍历的算法
void PreOrder(ThreadNode<T>* p)
{
while (p!=NULL)
{
cout << p->data<<" "; //先访问根节点
if (p->ltag==)
{
p = p->leftChild; //有左子树,即为后继
}
else if(p->rtag==) //否则,有右子树,即为后继
{
p = p->rightChild;
}
else //无左右子树
{
while (p!=NULL&&p->rtag==) //检测后继线索
{
p = p->rightChild; //直到找到有右子树的结点
}
if (p!=NULL)
{
p = p->rightChild; //该结点的右子树为后继
}
}
}
cout << endl;
}
中序线索化二叉树后序遍历的算法
//中序线索二叉树的后序遍历算法
void PostOrder(ThreadNode<T>* p)
{
ThreadNode<T>* t = p;
while (t->ltag==||t->rtag==) //寻找后续第一个结点
{
if(t->ltag==)
{
t = t->leftChild;
}
else if(t->rtag==)
{
t = t->rightChild;
}
}
cout << t->data<<" "; //访问第一个结点
while ((p=Parent(t))!=NULL) //每次都先找到当前结点的父结点
{
//若当前结点是父节点的右子树或者当前结点是左子树,但是这个父节点没有右子树,则后续下的后继为改父节点
if (p->rightChild==t||p->rtag==)
{
t = p;
}
//否则,在当前结点的右子树(如果存在)上重复执行上面的操作
else
{
t = p->rightChild;
while (t->ltag==||t->rtag==)
{
if (t->ltag==)
{
t = t->leftChild;
}
else if (t->rtag==)
{
t = t->rightChild;
}
}
}
cout << t->data << " ";
}
}
在中序线索二叉树中求父节点

//在中序线索化二叉树中求父节点
ThreadNode<T>* Parent(ThreadNode<T>* t)
{
ThreadNode<T>* p;
if(t==root) //根节点无父节点
{
return NULL;
}
for (p = t; p->ltag == ; p = p->leftChild); //求*t为根的中序下的第一个结点p
//情况1
if (p->leftChild!=NULL) //当p左子树指向不为空
{
//令p为p的左子树指向的结点,判断此结点是否并且此节点的左右子树结点的指向都不为t,再将p为p的右孩子结点
for (p = p->leftChild; p != NULL&&p->leftChild != t&&p->rightChild != t; p = p->rightChild);
}
//情况2
//如果上面的循环完了,由于是p==NULL结束的循环,没有找到与t相等的结点,就是一直找到了中序线索化的第一个结点了,这时候这种就要用到情况2的方法
if (p==NULL||p->leftChild==NULL)
{
//找到*t为根的中序下的最后一个结点
for (p = t; p->rtag == ; p = p->rightChild);
//让后让他指向最后一个结点指向的结点,从这个结点开始,以此判断它的左孩子孩子和右孩子是否和t相等
for (p = p->rightChild; p != NULL&&p->leftChild != t&&p->rightChild != t; p = p->leftChild);
}
return p;
}
完整代码
//线索二叉树
template<typename T>
struct ThreadNode //结点类
{
int ltag, rtag; //左右子树标志位
ThreadNode<T> *leftChild, *rightChild; //左孩子和右孩子
T data; //结点存储的值
ThreadNode(const T item) :data(item), leftChild(NULL), rightChild(NULL), ltag(), rtag() {} //结点类的构造函数
}; template<typename T>
class ThreadTree
{ public:
//构造函数(普通)
ThreadTree() :root(NULL) {} //指定结束标志RefValue的构造函数
ThreadTree(T value) :RefValue(value), root(NULL) {} //使用前序遍历创建二叉树(未线索化)
void CreateTree() { CreateTree(root); } //中序遍历对创建好的普通二叉树进行中序线索化
void CreateInThread()
{
ThreadNode<T> *pre = NULL; //第一个结点的左子树置为NULL
if (root != NULL) {
createInThread(root, pre);
//处理中序遍历的最后一个结点,最后一个结点的右子树置为空
pre->rightChild = NULL;
pre->rtag = ;
}
}
//线索化二叉树上执行中序遍历的算法
void InOrder() { InOrder(root); }
//中序线索化二叉树上实现前序遍历的算法
void PreOrder() { PreOrder(root); }
//中序线索二叉树的后序遍历算法
void PostOrder() { PostOrder(root); }
private:
//使用前序遍历创建二叉树(未线索化)
void CreateTree(ThreadNode<T>* &subTree)
{
T item;
if (cin >> item)
{
if (item != RefValue)
{
subTree = new ThreadNode<T>(item); //构造结点
if (subTree == NULL)
{
cout << "空间分配错误!" << endl;
exit();
}
CreateTree(subTree->leftChild); //递归创建左子树
CreateTree(subTree->rightChild); //递归创建右子树
}
else
{
subTree == NULL;
}
}
}
//中序遍历对二叉树进行线索化
void createInThread(ThreadNode<T> *current, ThreadNode<T> * &pre)
{
if (current == NULL)
{
return;
}
createInThread(current->leftChild, pre); //递归左子树的线索化
if (current->leftChild == NULL) //建立当前结点的前驱结点
{
current->leftChild = pre;
current->ltag = ;
}
if (pre != NULL&&pre->rightChild == NULL) //建立当前结点的后继结点
{
pre->rightChild = current;
pre->rtag = ;
}
pre = current; //用前驱记住当前的结点
createInThread(current->rightChild, pre); //递归右子树的线索化
} //寻找中序下第一个结点
ThreadNode<T> * First(ThreadNode<T> *current) //返回以*current为根的中序线索二叉树中序遍历的第一个结点
{
ThreadNode<T> *p = current;
while (p->ltag == )
{
p = p->leftChild; //循环找到最左下角结点
}
return p;
} //寻找中序下的后继结点
ThreadNode<T>* Next(ThreadNode<T>* current)
{
ThreadNode<T>* p = current->rightChild;
if(current->rtag==)
{
return First(p);
}
else
{
return p;
}
} //寻找中序下最后一个结点
ThreadNode<T> * Last(ThreadNode<T> *current) //返回以*current为根的中序线索二叉树中序遍历的最后一个结点
{
ThreadNode<T> *p = current;
while (p->rtag==)
{
p = p->rightChild;
}
return p;
}
//寻找结点在中序下的前驱结点
ThreadNode<T>* Prior(ThreadNode<T>* current)
{
ThreadNode<T>* p = current->leftChild;
if (current->ltag==)
{
return Last(p);
}
else
{
return p;
}
}
//在中序线索化二叉树中求父节点
ThreadNode<T>* Parent(ThreadNode<T>* t)
{
ThreadNode<T>* p;
if(t==root) //根节点无父节点
{
return NULL;
}
for (p = t; p->ltag == ; p = p->leftChild); //求*t为根的中序下的第一个结点p
//情况1
if (p->leftChild!=NULL) //当p左子树指向不为空
{
//令p为p的左子树指向的结点,判断此结点是否并且此节点的左右子树结点的指向都不为t,再将p为p的右孩子结点
for (p = p->leftChild; p != NULL&&p->leftChild != t&&p->rightChild != t; p = p->rightChild);
}
//情况2
//如果上面的循环完了,由于是p==NULL结束的循环,没有找到与t相等的结点,就是一直找到了中序线索化的第一个结点了,这时候这种就要用到情况2的方法
if (p==NULL||p->leftChild==NULL)
{
//找到*t为根的中序下的最后一个结点
for (p = t; p->rtag == ; p = p->rightChild);
//让后让他指向最后一个结点指向的结点,从这个结点开始,以此判断它的左孩子孩子和右孩子是否和t相等
for (p = p->rightChild; p != NULL&&p->leftChild != t&&p->rightChild != t; p = p->leftChild);
}
return p;
} //中序线索化二叉树上执行中序遍历的算法
void InOrder(ThreadNode<T>* p)
{
for (p=First(root);p!=NULL;p=Next(p))
{
cout << p->data<<" ";
}
cout << endl;
}
//中序线索化二叉树上实现前序遍历的算法
void PreOrder(ThreadNode<T>* p)
{
while (p!=NULL)
{
cout << p->data<<" "; //先访问根节点
if (p->ltag==)
{
p = p->leftChild; //有左子树,即为后继
}
else if(p->rtag==) //否则,有右子树,即为后继
{
p = p->rightChild;
}
else //无左右子树
{
while (p!=NULL&&p->rtag==) //检测后继线索
{
p = p->rightChild; //直到找到有右子树的结点
}
if (p!=NULL)
{
p = p->rightChild; //该结点的右子树为后继
}
}
}
cout << endl;
}
//中序线索二叉树的后序遍历算法
void PostOrder(ThreadNode<T>* p)
{
ThreadNode<T>* t = p;
while (t->ltag==||t->rtag==) //寻找后续第一个结点
{
if(t->ltag==)
{
t = t->leftChild;
}
else if(t->rtag==)
{
t = t->rightChild;
}
}
cout << t->data<<" "; //访问第一个结点
while ((p=Parent(t))!=NULL) //每次都先找到当前结点的父结点
{
//若当前结点是父节点的右子树或者当前结点是左子树,但是这个父节点没有右子树,则后续下的后继为改父节点
if (p->rightChild==t||p->rtag==)
{
t = p;
}
//否则,在当前结点的右子树(如果存在)上重复执行上面的操作
else
{
t = p->rightChild;
while (t->ltag==||t->rtag==)
{
if (t->ltag==)
{
t = t->leftChild;
}
else if (t->rtag==)
{
t = t->rightChild;
}
}
}
cout << t->data << " ";
}
} private:
//树的根节点
ThreadNode<T> *root;
T RefValue;
};
测试函数
int main(int argc, char* argv[])
{
//abc##de#g##f###
ThreadTree<char> tree('#');
tree.CreateTree();
tree.CreateInThread();
tree.InOrder();
tree.PreOrder();
tree.PostOrder();
}
线索二叉树的详细实现(C++)的更多相关文章
- 【PHP数据结构】完全二叉树、线索二叉树及树的顺序存储结构
在上篇文章中,我们学习了二叉树的基本链式结构以及建树和遍历相关的操作.今天我们学习的则是一些二叉树相关的概念以及二叉树的一种变形形式. 完全二叉树 什么叫完全二叉树呢?在说到完全二叉树之前,我们先说另 ...
- 数据结构《9》----Threaded Binary Tree 线索二叉树
对于任意一棵节点数为 n 的二叉树,NULL 指针的数目为 n+1 , 线索树就是利用这些 "浪费" 了的指针的数据结构. Definition: "A binary ...
- 线索二叉树Threaded binary tree
摘要 按照某种遍历方式对二叉树进行遍历,可以把二叉树中所有结点排序为一个线性序列.在该序列中,除第一个结点外每个结点有且仅有一个直接前驱结点:除最后一个结点外每一个结点有且仅有一个直接后继结点.这 ...
- 遍历二叉树 traversing binary tree 线索二叉树 threaded binary tree 线索链表 线索化
遍历二叉树 traversing binary tree 线索二叉树 threaded binary tree 线索链表 线索化 1. 二叉树3个基本单元组成:根节点.左子树.右子树 以L.D.R ...
- 树和二叉树->线索二叉树
文字描述 从二叉树的遍历可知,遍历二叉树的输出结果可看成一个线性队列,使得每个结点(除第一个和最后一个外)在这个线形队列中有且仅有一个前驱和一个后继.但是当采用二叉链表作为二叉树的存储结构时,只能得到 ...
- 图解中序遍历线索化二叉树,中序线索二叉树遍历,C\C++描述
body, table{font-family: 微软雅黑; font-size: 13.5pt} table{border-collapse: collapse; border: solid gra ...
- 【Java】 大话数据结构(9) 树(二叉树、线索二叉树)
本文根据<大话数据结构>一书,对Java版的二叉树.线索二叉树进行了一定程度的实现. 另: 二叉排序树(二叉搜索树) 平衡二叉树(AVL树) 二叉树的性质 性质1:二叉树第i层上的结点数目 ...
- 数据结构之线索二叉树——C语言实现
线索二叉树操作 (1) 线索二叉树的表示:将每个节点中为空的做指针与右指针分别用于指针节点的前驱和后续,即可得到线索二叉树. (2) 分类:先序线索二叉树,中序线索二叉树,后续线索二叉树 (3) 增 ...
- 后序线索二叉树中查找结点*p的后继
在后序线索二叉树中查找结点*p的后继: 1.若结点*p为根,则无后继:2.若结点*p为其双亲的右孩子,则其后继为其双亲:3.若结点*p为其双亲的左孩子,且双亲无右子女,则其后继为其双亲:4.若结点*p ...
随机推荐
- [转] c# 中使用opencv进行视频捕获
简介 这个项目是关于如何从网络摄像头或者视频文件(*.AVI)中捕获视频的,这个项目是用C#和OPENCV编写的. 这将有助于那些喜欢C#和OpenCV环境的人.这个程序完全基于Visual Stud ...
- java面试记录二:spring加载流程、springmvc请求流程、spring事务失效、synchronized和volatile、JMM和JVM模型、二分查找的实现、垃圾收集器、控制台顺序打印ABC的三种线程实现
注:部分答案引用网络文章 简答题 1.Spring项目启动后的加载流程 (1)使用spring框架的web项目,在tomcat下,是根据web.xml来启动的.web.xml中负责配置启动spring ...
- (转)进程同步之临界区域问题及Peterson算法
转自:http://blog.csdn.net/speedme/article/details/17595821 1. 背景 首先,看个例子,进程P1,P2共用一个变量COUNT,初始值为0 ...
- laravel多条件模糊查询
1.运用cmd在项目根目录下创建路由组 php artisan make:controller queryController --resource 1.1数据库信息(student) CREATE ...
- 高通量计算框架HTCondor(六)——拾遗
目录 1. 正文 1.1. 一些问题 1.2. 使用建议 2. 相关 1. 正文 1.1. 一些问题 如果真正要将HTCondor高通量计算产品化还需要很多工作要做,HTCondor并没有GUI界面, ...
- 高级特征工程II
以下是Coursera上的How to Win a Data Science Competition: Learn from Top Kagglers课程笔记. Statistics and dist ...
- Java修饰符类型
转自原文:http://www.yiibai.com/java/java_modifier_types.html 修饰符是添加到这些定义来改变它们的含义的关键词. Java语言有各种各样修饰词,其中包 ...
- ubuntu apt 换源
修改配置文件/etc/apt/sources.list 内容替换为 阿里镜像源 deb http://mirrors.aliyun.com/ubuntu/ vivid main restricted ...
- eclipse的安装和环境配置
一,eclipse下载 地址:https://www.eclipse.org/downloads/ 一般浏览器都有翻译功能 二.有32位和64位的版本根据自己的需求下载,选下载的选下载量最多的下载. ...
- orcad常用库文件
ORCAD CAPTURE元件库介绍 AMPLIFIER.OLB amplifier 共182个零件,存放模拟放大器IC,如CA3280,TL027C,EL4093等. ARITHMETIC.OLB ...