processing data
获取有效数据
Scikit-learn will not accept categorical features by default
API里面不知使用默认的特征变量名,因此需要编码
这里我还是有疑问?
对于下载的数据集,一般的特征变量名,在进行分类的时候,机器是不能识别的,需要对特征名进行编码,因为计算机是二进制语言啊?Need to encode categorical features numerically
Convert to ‘dummy variables’
- 0: Observation was NOT that category
- 1: Observation was that category
Dealing with categorical features in Python
两种方式是一样的
- scikit-learn: OneHotEncoder()
- pandas: get_dummies()
pd.get_dummies
- 离散特征编码
- 可用来表示分类变量、非数量因素可能产生的影响
pandas加入虚拟变量的方式
get_dummies 是利用pandas实现one hot encode的方式。详细参数请查看官方文档
pandas.get_dummies(data, prefix=None, prefix_sep='_', dummy_na=False, columns=None, sparse=False, drop_first=False)[source]
- data 要处理的DataFrame
- prefix 列名的前缀,在多个列有相同的离散项时候使用
- prefix_sep 前缀和离散值的分隔符,默认为下划线,默认即可
- dummy_na 是否把NA值,作为一个离散值进行处理,默认为不处理
- columns 要处理的列名,如果不指定该列,那么默认处理所有列
- drop_first 是否从备选项中删除第一个,建模的时候为避免共线性使用
Pandas中的get_dummy()函数是将拥有不同值的变量转换为0/1数值。
举例说明:一群样本的年龄分别为19,32,56,94岁,19岁用1表示,32岁用2表示,56岁用3表示,94岁用4表示。1,2,3,4这些数值的大小本身没有意义,只是用来区分年龄。因此在实际问题中,需要将1,2,3,4转化为0/1,即如果是19岁,则为0,若不是则为1,以此类推。
- 举个例子
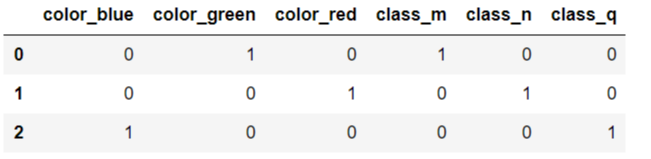
import pandas as pd
df = pd.DataFrame([
['green' , 'm'],
['red' , 'n'],
['blue' , 'q']])
df.columns = ['color', 'class']
pd.get_dummies(df)
# Create dummy variables: df_region
df_region = pd.get_dummies(df)
# Print the columns of df_region
print(df_region.columns)
# Drop 'Region_America' from df_region
df_region = pd.get_dummies(df, drop_first=True)
# Print the new columns of df_region
print(df_region)
处理缺失数据
Imputer()
- 填补缺失值:
sklearn.preprocessing.Imputer(missing_values=’NaN’, strategy=’mean’, axis=0, verbose=0, copy=True)
主要参数说明:
missing_values:缺失值,可以为整数或NaN(缺失值numpy.nan用字符串‘NaN’表示),默认为NaN
strategy:替换策略,字符串,默认用均值‘mean’替换
- 若为mean时,用特征列的均值替换
- 若为median时,用特征列的中位数替换
- 若为most_frequent时,用特征列的众数替换
axis:指定轴数,默认axis=0代表列,axis=1代表行
copy:设置为True代表不在原数据集上修改,设置为False时,就地修改,存在如下情况时,即使设置为False时,也不会就地修改
- X不是浮点值数组
- X是稀疏且missing_values=0
- axis=0且X为CRS矩阵
- axis=1且X为CSC矩阵
statistics_属性:axis设置为0时,每个特征的填充值数组,axis=1时,报没有该属性错误
参考
# Import the Imputer module
from sklearn.preprocessing import Imputer
from sklearn.svm import SVC
# Setup the Imputation transformer: imp
imp = Imputer(missing_values='NaN', strategy='most_frequent', axis=0)
# Instantiate the SVC classifier: clf
clf = SVC()
# Setup the pipeline with the required steps: steps
steps = [('imputation', imp),
('SVM', clf)]
dropna()
直接删除缺失值
pipline
官方文档
连接多个转换器和预测器在一起,形成一个机器学习工作流,这句解释太官方了,因此我没懂
processing data的更多相关文章
- PatentTips - Data Plane Packet Processing Tool Chain
BACKGROUND The present disclosure relates generally to systems and methods for providing a data plan ...
- Becoming a Data Scientist – Curriculum via Metromap
From: http://nirvacana.com/thoughts/becoming-a-data-scientist/ Data Science, Machine Learning, Big D ...
- Monitoring and Tuning the Linux Networking Stack: Receiving Data
http://blog.packagecloud.io/eng/2016/06/22/monitoring-tuning-linux-networking-stack-receiving-data/ ...
- 基于Processing的数据可视化
虽然数据可视化领域有很多成熟.界面友好.功能强大的软件产品(例如Tableau.VIDI.NodeXL等),但是借助Processing我们可以基于Java语言框架进行丰富多元的可视化编程,熟悉了Pr ...
- Awesome Big Data List
https://github.com/onurakpolat/awesome-bigdata A curated list of awesome big data frameworks, resour ...
- IAB303 Data Analytics Assessment Task
Assessment TaskIAB303 Data Analyticsfor Business InsightSemester I 2019Assessment 2 – Data Analytics ...
- Python - 2. Built-in Collection Data Types
From: http://interactivepython.org/courselib/static/pythonds/Introduction/GettingStartedwithData.htm ...
- Stream processing with Apache Flink and Minio
转自:https://blog.minio.io/stream-processing-with-apache-flink-and-minio-10da85590787 Modern technolog ...
- [Windows Azure] Data Management and Business Analytics
http://www.windowsazure.com/en-us/develop/net/fundamentals/cloud-storage/ Managing and analyzing dat ...
随机推荐
- PBFT算法java实现
PBFT 算法的java实现(上) 在这篇博客中,我会通过Java 去实现PBFT中结点的加入,以及认证.其中使用socket实现网络信息传输. 关于PBFT算法的一些介绍,大家可以去看一看网上的博客 ...
- [redis读书笔记] 第一部分 数据结构与对象 对象特性
一 类型检查和多态 类型检查,即有的命令是只针对特定类型的,如果类型不对,就会报错,此处的类型,是指的键类型,即robj.type.下面为有类型检查的命令: 对于某一种类型,redis下底层的实 ...
- MySql在Windows下自动备份的几种方法
以下几种全部是批处理命令中对于备份文件 1.复制date文件夹备份============================假想环境:MySQL 安装位置:C:\MySQL论坛数据库名称为:bbs数 ...
- Android 7.0新特性“Nougat”(牛轧糖)。
1.Unicode 9支持和全新的emoji表情符号 Android Nougat将会支持Unicode 9,并且会新增大约70种emoji表情符号.这些表情符号大多数都是人形的,并且提供不同的肤色, ...
- Vue之Vuex的使用
重点看懂这张图: 重点记住: 1.Mutation 必须是同步函数,即mutations里只能处理同步操作. 2.如果处理的是同步操作可直接commit提交mutations更改state,如果是异步 ...
- 图解Java设计模式之UML类图
图解Java设计模式之UML类图 3.1 UML基本介绍 UML图 UML类图 3.1 UML基本介绍 1)UML – Unified modeling language UML(统一建模语言),是一 ...
- C# 一个帮您理解回调函数的例子(新手必看)
using System; using System.Collections.Generic; using System.Linq; using System.Text; namespace 回调函数 ...
- spring cloud springboot 框架源码 activiti工作流 前后分离 集成代码生成器
1.代码生成器: [正反双向](单表.主表.明细表.树形表,快速开发利器)freemaker模版技术 ,0个代码不用写,生成完整的一个模块,带页面.建表sql脚本.处理类.service等完整模块2. ...
- Android中自定义xml文件给Spinner下拉框赋值并获取下拉选中的值
场景 实现效果如下 注: 博客: https://blog.csdn.net/badao_liumang_qizhi 关注公众号 霸道的程序猿 获取编程相关电子书.教程推送与免费下载. 实现 将布局改 ...
- Appium超详细环境搭建for Mac
兜兜转转试用了一圈自动化框架后,回归到appium,与一年之前相比,appium有了很大的改变:1.iOS 9 之前一直以 instruments 下的 UIAutomation为驱动底层技术(弊 ...