机器学习总结-bias–variance tradeoff
bias–variance tradeoff
通过机器学习,我们可以从历史数据学到一个\(f\),使得对新的数据\(x\),可以利用学到的\(f\)得到输出值\(f(x)\)。设我们不知道的真实的\(f\)为\(\overline{f}\),我们从数据中学到的\(f\)为\(f^{*}\),实际上\(f^{*}\)是\(\overline{f}\)的一个估计。在统计中,变量\(x\)的均值\(mean\)表示为\(\mu\),方差\(variance\)表示为\(\sigma\),假设我们抽取出\(x\)的\(N\)个样本,可以用\(m=\frac{1}{N}\sum_{i=1}^{N}x_{i}\)来估计\(\mu\),但实际上\(m \neq \mu\),如果我们抽取很多次得到不同的m,那么期望\(E(m)=E(\frac{1}{N}\sum_{i=1}^{N}x_{i})=\frac{1}{N}\sum_{i=1}^{N}E(x_{i})=E(x)=\mu\)。\(var(m)=\frac{\sigma^2}{N}\),即抽取的样本\(N\)大,\(m\)的\(variance\)越小。\(s^2=\frac{1}{N}\sum_{i=1}^{N}(x_{i}-m)^2\),\(E(s^2)=\frac{N-1}{N}\sigma^2\neq\sigma^2\),因此\(s^2\)是有偏估计量。
实际上,如果用平方误差表示,误差分为3个部分(来自wikipedia):
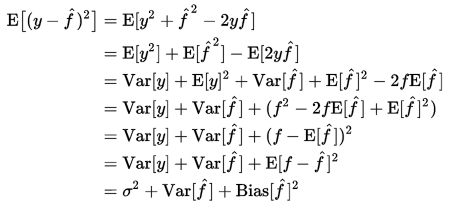
偏差度量了学习算法的期望预测与真实结果的偏离程度,即刻画了学习算法本身的拟合能力;
方差度量了同样大小的训练集的变动所导致的学习性能的变化,即刻画了数据扰动所造成的影响;
噪声则表达了在当前任务上任何学习算法所能达到的期望泛化误差的下界,即刻画了学习问题本身的难度。
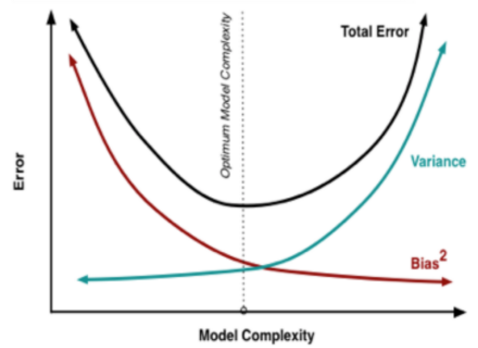
通常,简单的模型variance小(不同数据上的结果差异较小),bias大,容易表现为欠拟合,需要增加模型复杂度,加入新的特征;复杂的模型variance大(表达能力强,对不同数据较敏感,结果差异较大),bias小(平均来说与真实结果较为接近),容易表现为过拟合,需要增加更多数据(非常有效,但不太现实)或者用正则化来控制模型的复杂程度。
常见错误:
在机器学习任务中,如果使用测试集正确率为依据来调整模型,容易出现过拟合的现象,使得泛化误差很大。通常做法是交叉验证(Cross Validation),根据划分验证集上的平均结果来调整模型,不要过分关心测试集上的结果,如果验证集上的误差小,那么测试集上的期望误差也会小。
机器学习总结-bias–variance tradeoff的更多相关文章
- 2.9 Model Selection and the Bias–Variance Tradeoff
结论 模型复杂度↑Bias↓Variance↓ 例子 $y_i=f(x_i)+\epsilon_i,E(\epsilon_i)=0,Var(\epsilon_i)=\sigma^2$ 使用knn做预测 ...
- [转]理解 Bias 与 Variance 之间的权衡----------bias variance tradeoff
有监督学习中,预测误差的来源主要有两部分,分别为 bias 与 variance,模型的性能取决于 bias 与 variance 的 tradeoff ,理解 bias 与 variance 有助于 ...
- On the Bias/Variance tradeoff in Machine Learning
参考:https://codesachin.wordpress.com/2015/08/05/on-the-biasvariance-tradeoff-in-machine-learning/ 之前一 ...
- Bias/variance tradeoff
线性回归中有欠拟合与过拟合,例如下图: 则会形成欠拟合, 则会形成过拟合. 尽管五次多项式会精确的预测训练集中的样本点,但在预测训练集中没有的数据,则不能很好的预测,也就是说有较大的泛化误差,上面的右 ...
- Error=Bias+Variance
首先 Error = Bias + Variance Error反映的是整个模型的准确度,Bias反映的是模型在样本上的输出与真实值之间的误差,即模型本身的精准度,Variance反映的是模型每一次输 ...
- 【笔记】偏差方差权衡 Bias Variance Trade off
偏差方差权衡 Bias Variance Trade off 什么叫偏差,什么叫方差 根据下图来说 偏差可以看作为左下角的图片,意思就是目标为红点,但是没有一个命中,所有的点都偏离了 方差可以看作为右 ...
- 机器学习:偏差方差权衡(Bias Variance Trade off)
一.什么是偏差和方差 偏差(Bias):结果偏离目标位置: 方差(Variance):数据的分布状态,数据分布越集中方差越低,越分散方差越高: 在机器学习中,实际要训练模型用来解决一个问题,问题本身可 ...
- 机器学习模型 bias 和 variance 的直观判断
假设我们已经训练得到 一个模型,那么我们怎么直观判断这个 模型的 bias 和 variance? 直观方法: 如果模型的 训练错误 比较大,并且 验证错误 和 训练错误 差不多一样,都比较大,我们就 ...
- 【笔记】机器学习 - 李宏毅 - 3 - Bias & Variance
A more complex model does not always lead to better performance on testing data. Because error due t ...
随机推荐
- PHP 经典面试题集
这篇文章介绍的内容是关于PHP 经典面试题集 PHP 经典面试题集,有着一定的参考价值,现在分享给大家,有需要的朋友可以参考一下 结合我自己面试情况,面对的一些php面试题列举出来,基本上结合自己的看 ...
- [推荐]icheck-bootstrap(漂亮的ckeckbox/radiobox)
适用于Twitter Bootstrap框架的纯CSS样式的复选框/单选框按钮的插件. GitHub:https://github.com/bantikyan/icheck-bootstrap 如果你 ...
- 2018 东北地区大学生程序设计竞赛(ABEHIK)
HDU6500:Problem A. Game with string 题意: 给你一个字符串s以及它的m个子串的首尾位置,现在Alice和 Bob两个人轮流在任一子串的前面或者后面加1个字符,要求加 ...
- C++ | C++ 基础知识 | 结构、联合与枚举
1. 结构 1.0 结构 数组是相同类型元素的集合,相反,struct 是任意类型元素的集合. 代码例子: struct Address { const char* name; int number; ...
- html 小游戏合集(1.0)
最近做了个小游戏合集,有点沙雕,毕竟是1.0,将就看看. <!DOCTYPE html> <html> <head> <meta charset=" ...
- js正则定义支付宝账号、手机号、邮箱
一.支付宝账号:可以只输入数字.字母.字母(数字)+数字(字母),其中只字母中可以含有@._或者.也可以三者都可以包含并且可以在任意位置,限制:小于等于30位(可根据需求自定义范围): let zh ...
- 【LC_Lesson2】---整数反转练习
题目描述: 给出一个 32 位的有符号整数,你需要将这个整数中每位上的数字进行反转. 示例 1: 输入: 123 输出: 321 示例 2: 输入: -123 输出: -321 示例 3: 输入: 1 ...
- Java.前端.Layer.open.btn验证无效
今天遇到了一个很可笑的问题,在.Layer弹窗open中设置了多个按钮,只有yes按钮有效,btn2点击后直接关闭弹窗,排查了2个小时后终于解决,就是btn2要return false! var in ...
- restframework 序列化补充(自定义ModelSerializerl)
一.知识点 1.source title = serializers.CharField(source='courses.title') source用于one2one.foreginkey.choi ...
- ORM _meta
import os if __name__ == '__main__': os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'XadminDemon.se ...