Flink架构(四)- 状态管理
状态管理
之前我们提到过大多数流应用是有状态的。很多operators会不断的访问并更新某中状态,例如一个window中收集了多少条记录,输入源中当前读到的位置,亦或是用户定义的特定operators的状态。无论是内置的operator还是用户定义的operators,Flink对待它们都是一致的。在这章我们会讨论Flink 支持的不同的状态类型、state是如何被存储并由state backends管理的,以及有状态的应用如何通过重新分发state而进行扩展。
一般来说,所有数据都由一个task维护,并被用于计算一个函数的结果,这个函数包含于此task的state。可以认为state是一个本地变量或是一个实例变量,可以由task的业务逻辑访问。下图展示了一个task与它的state的常规交互过程:
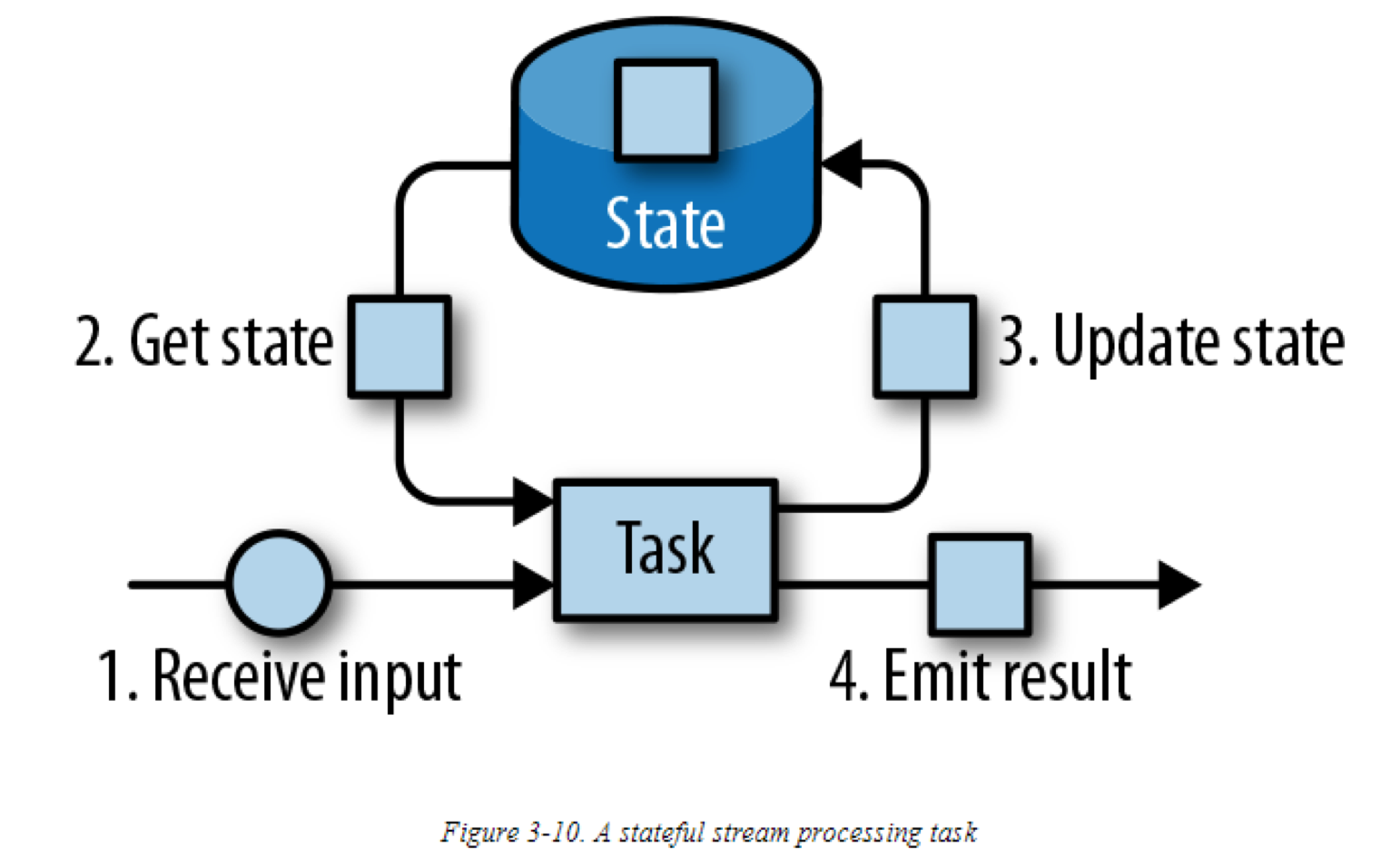
一个task接收一些输入数据。当处理数据时,task会访问state,并根据输入数据和state的信息更新它的state。一个简单的例子如:一个task持续计算迄今它接收到了多少条记录。当task接收到一个新的记录时,它会访问state获取当前的count数,增加count,更新state,并释放新的count作为结果输出。
Application读写state的逻辑一般较为直接并易于理解,然而高效、可靠的管理state更具有挑战性。它包括:处理超大的state(可能会超出内存),并确保在出现故障时state不会丢失等。Flink会处理所有关于state一致性、故障处理、高效存储并访问等问题,开发者仅需关注在他们的应用逻辑即可。
在Flink中,state一定是与一个特定的operator关联的。为了让Flink的runtime可以意识到一个operator的state,operator需要注册它的state。在Flink中有两种类型的state:operator state和keyed state。下面我们对它们做详细介绍。
Operator State
Operator state 被限定到一个operator task中,这个意思是:各个并行的task都有它自己的state,Operator state无法被其他task(无论是同一个还是不同的operator的task)访问。下图是tasks如何访问operator state:
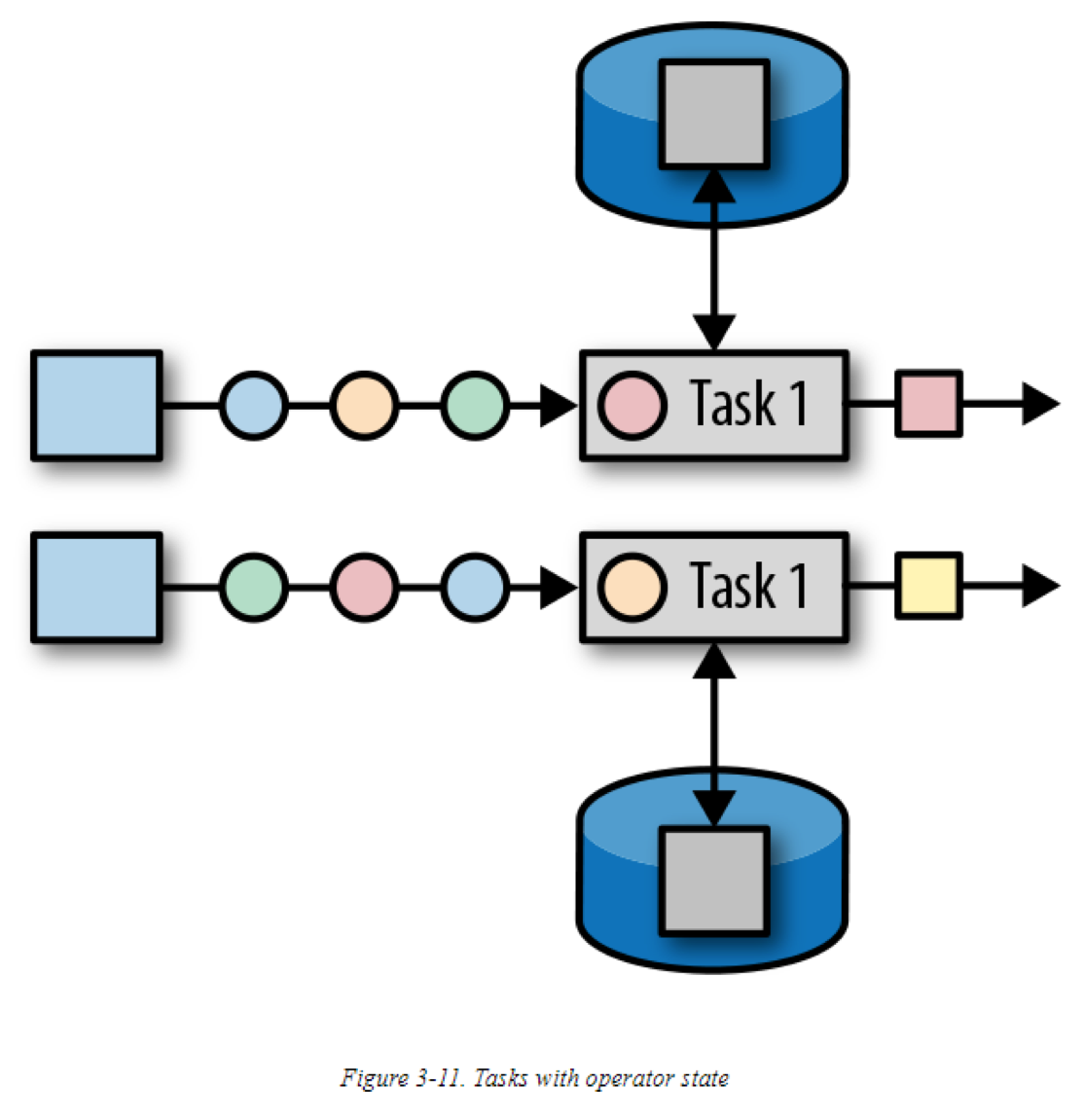
Flink为operator state提供了三种原型:
List state
· 以list的方式表示state
Union list state
· 同样以list的方式表示state。但是它与常规list state的不同点在于:发生故障时恢复的方式、或一个application从检查点开始的方式。
Broadcast state
· 被用于特殊场景,当一个operator的每个task的state都是相同时。这个属性可以被用于检查点,或是rescaling 一个 operator时。
Keyed State
Keyed state 的维护与访问是根据对应记录中的key决定的。Flink对每个key value 维护了一个state 实例,并将所有同样key的记录,分区到维护这些key的state的operator task中。当一个task处理一条记录时,它会自动归类当前record的key所要访问的state。最终,所有具有相同key的records会访问同一个state。下图展示了tasks与keyed state 的交互:
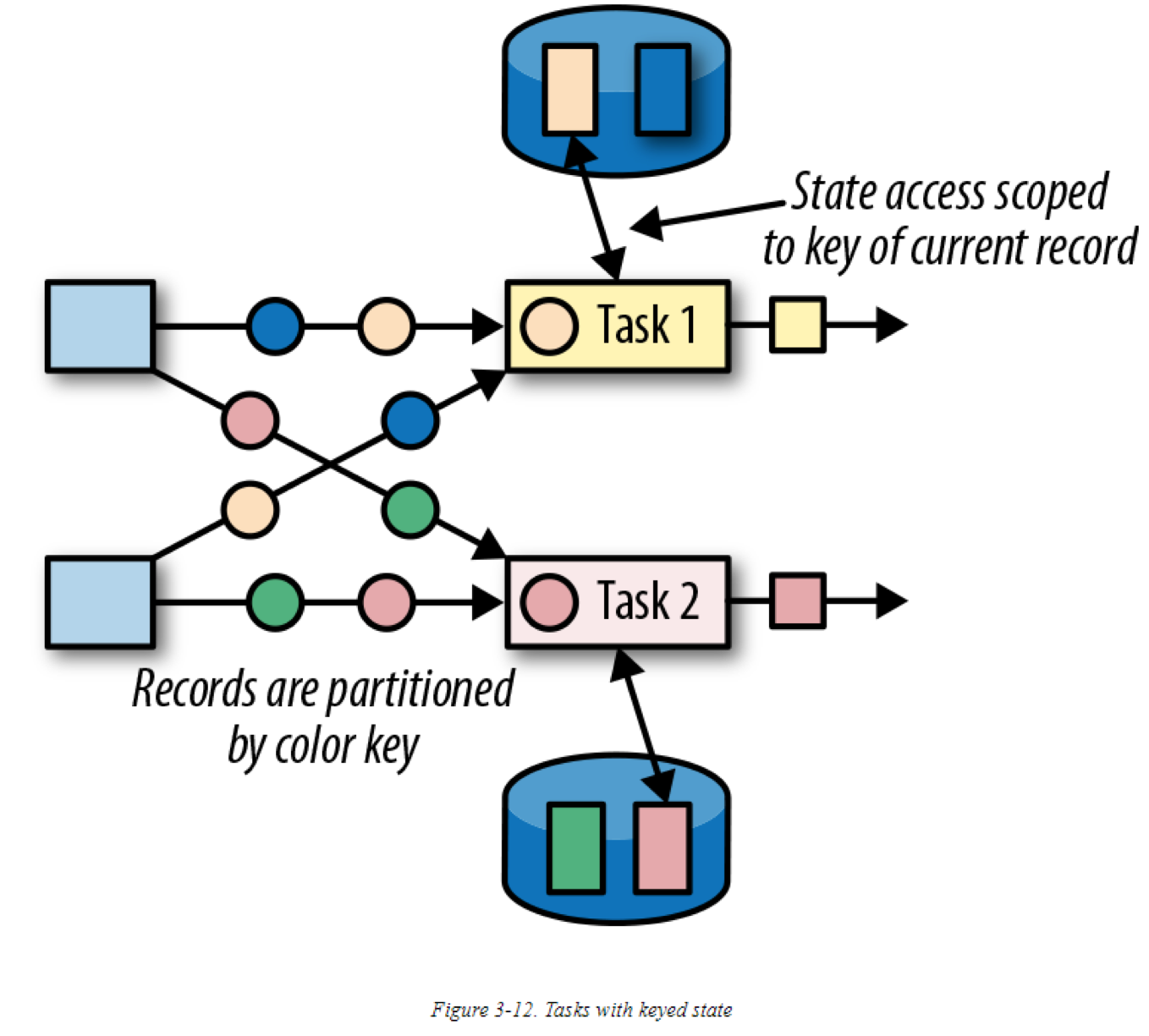
可以将keyed state看做是:对一个operator所有并行tasks上的所有key做分区后的key-value map。Flink为 keyed state 提供了不同的原语,用于决定在分布式的key-value map中,每个key里存储的value类型。
Value state
· 为每个key存一个单值(可以是任意类型)。复杂的数据结构也可以作为value state 存储
List state
· 为每个key存一个列表值。这个列表可以是任意类型
Map state
· 为每个key存一个key-value 映射。映射中的key和value可以是任意类型
State 原语为Flink提供了state的结构,并可以更高效的对state做访问。
状态后端(State Backends)
在有状态的operator中,它的task在每接受到一条记录时,一般都会访问、并更新state。因为高效地访问state 对于低延时处理records至关重要,所以每个并行的task都会在本地维护它的state,以确保快速访问state。State是如何准确的存储、访问、以及维护是由一个可插拔的组件决定的,这个组件成为状态后端(State backend)。一个state backend负责两件事:本地state管理,以及为state做检查点并存储到外部地址。
对于本地state 管理,state backend存储所有keyed state,并确保所有对keyed state的访问都符合当前key的条件。Flink提供的了state backend 将keyed state作为对象存储管理,并将它存储在JVM的堆内存中。另一个state backend 将state 对象序列化,并放入RocksDB中。RocksDB会将它们写入本地磁盘。第一个state backend 提供了快速访问state的选择,但是它会受到内存大小的限制。访问由RocksDB state backend存储的state会相对较慢,但是state可以增长到非常大。
对state做检查点非常重要,因为Flink是一个分布式系统,并且state仅仅是本地维护的。一个TaskManager进程(包括里面所有运行的task)可能会在任何时候出现故障。所以它的存储必须被认为是不稳定的。一个state backend 会对一个task的state做检查点,并存储到远端的持久性存储中。存储检查点的远端存储可以是一个分布式文件系统,或是一个数据库系统。不同的state backend会有不同的为state做检查点的方式。例如,RocksDB state backend 支持增量检查点,此方法可以大量减少对超大state做检查点时的开销。
扩展有状态的operators
对于流处理程序来说,一个常见的需求是:根据输入数据的速率,调节operators的并行度。对于无状态的operators 来说,扩展是很简单的。但是对于有状态的operators,会更具挑战性,因为他们的state需要被重新分区,并分配给更多或是更少的并行tasks。Flink支持四种模式,用于扩展不同类型的state。
对于keyed state的operators,扩展的实现方式是将keys重新分区到更少或是更多的tasks中。然而,为了提高tasks之间传递state的效率,Flink不会重新分布keys。它会将keys组织在一个或多个key groups中。一个key group不仅是keys的一个分区,也是Flink分配keys给tasks的方式。下图显示了keyed state 是如何在key groups中重新分区的:
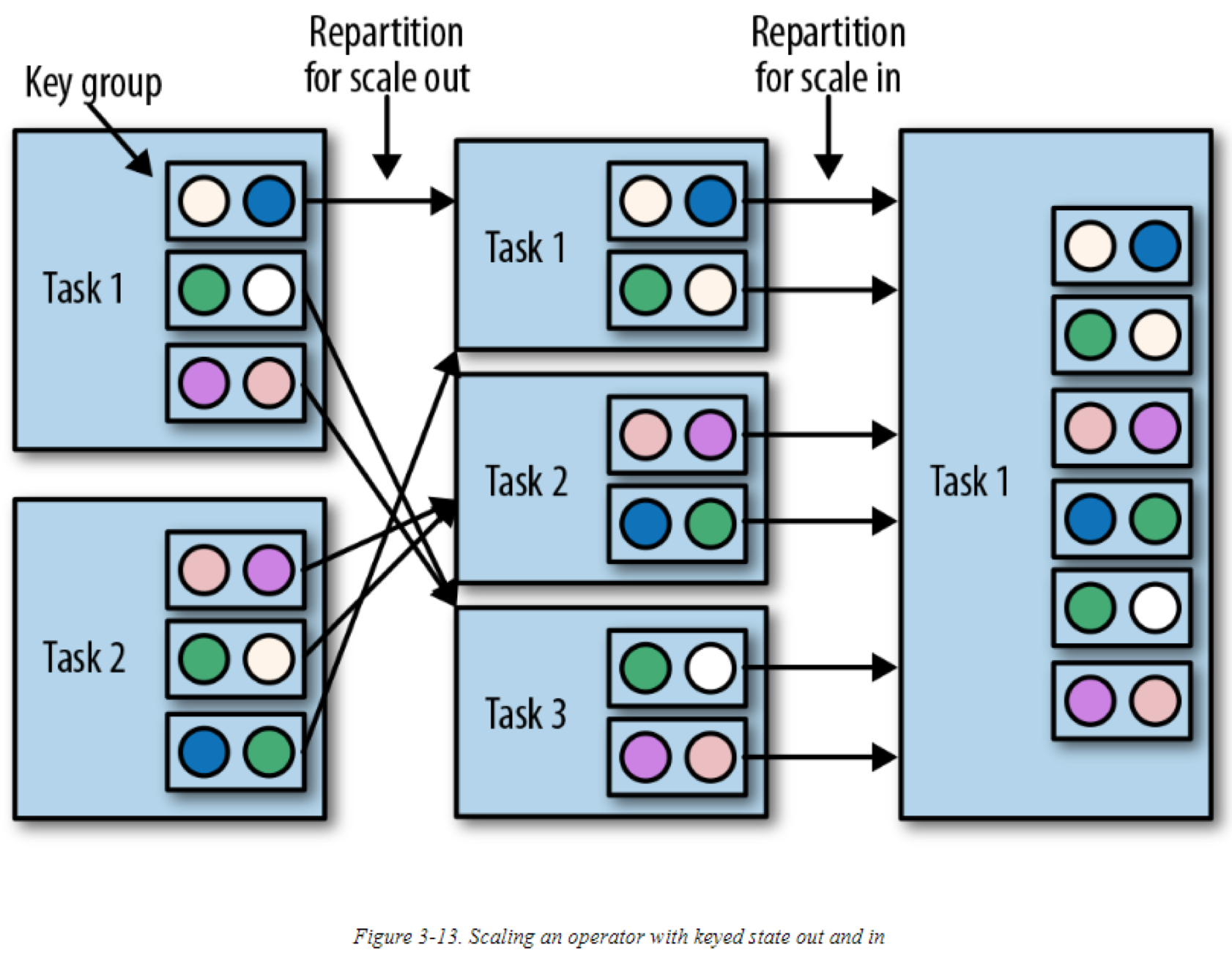
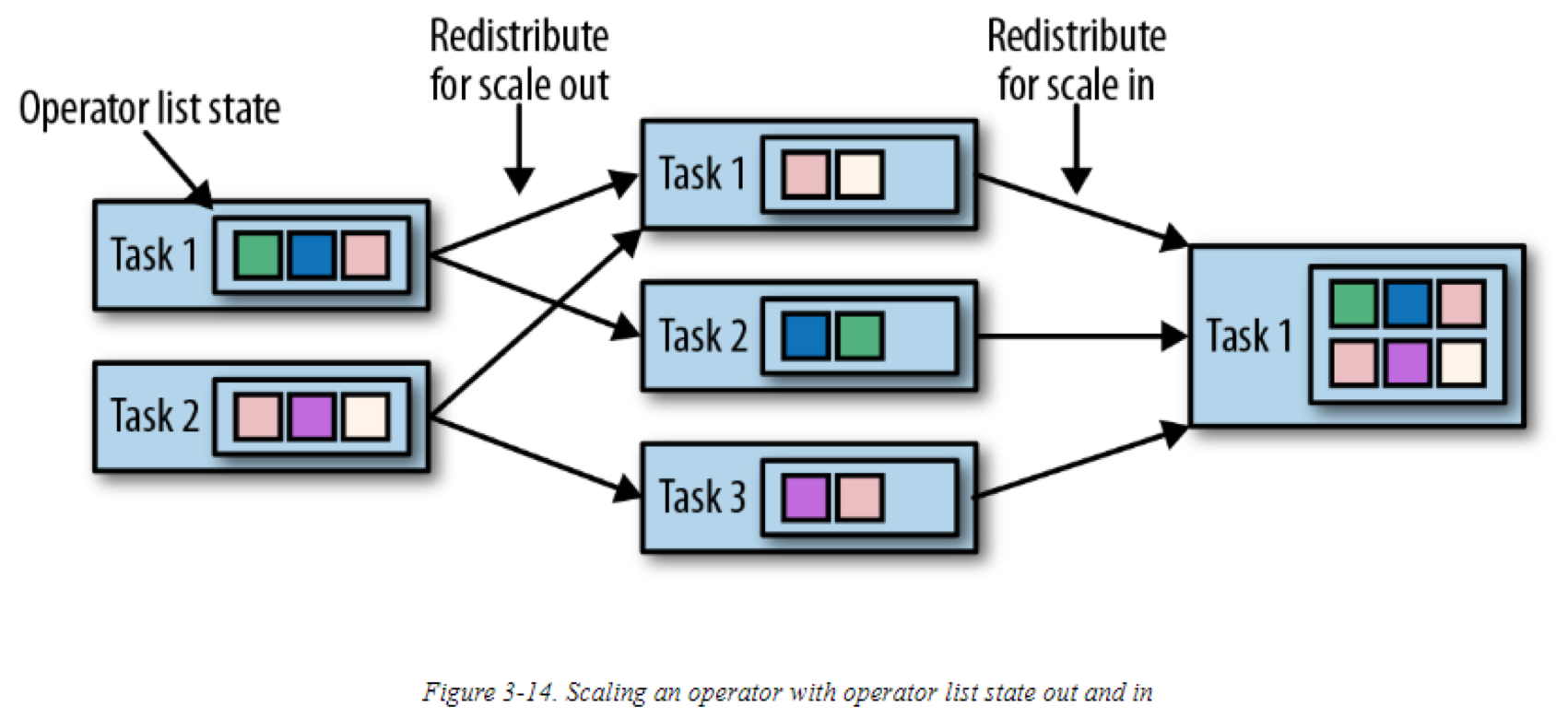
在扩展state为list state 的operators时,列表里的条目会被重新分配。概念上,所有并行tasks的列表里的条目被收集并均分的重新分布到更少或是更多的tasks中。如果列表条目数小于operator的新并行数,则一些task会从空state开始。下图显示了operator list state的重新分布:
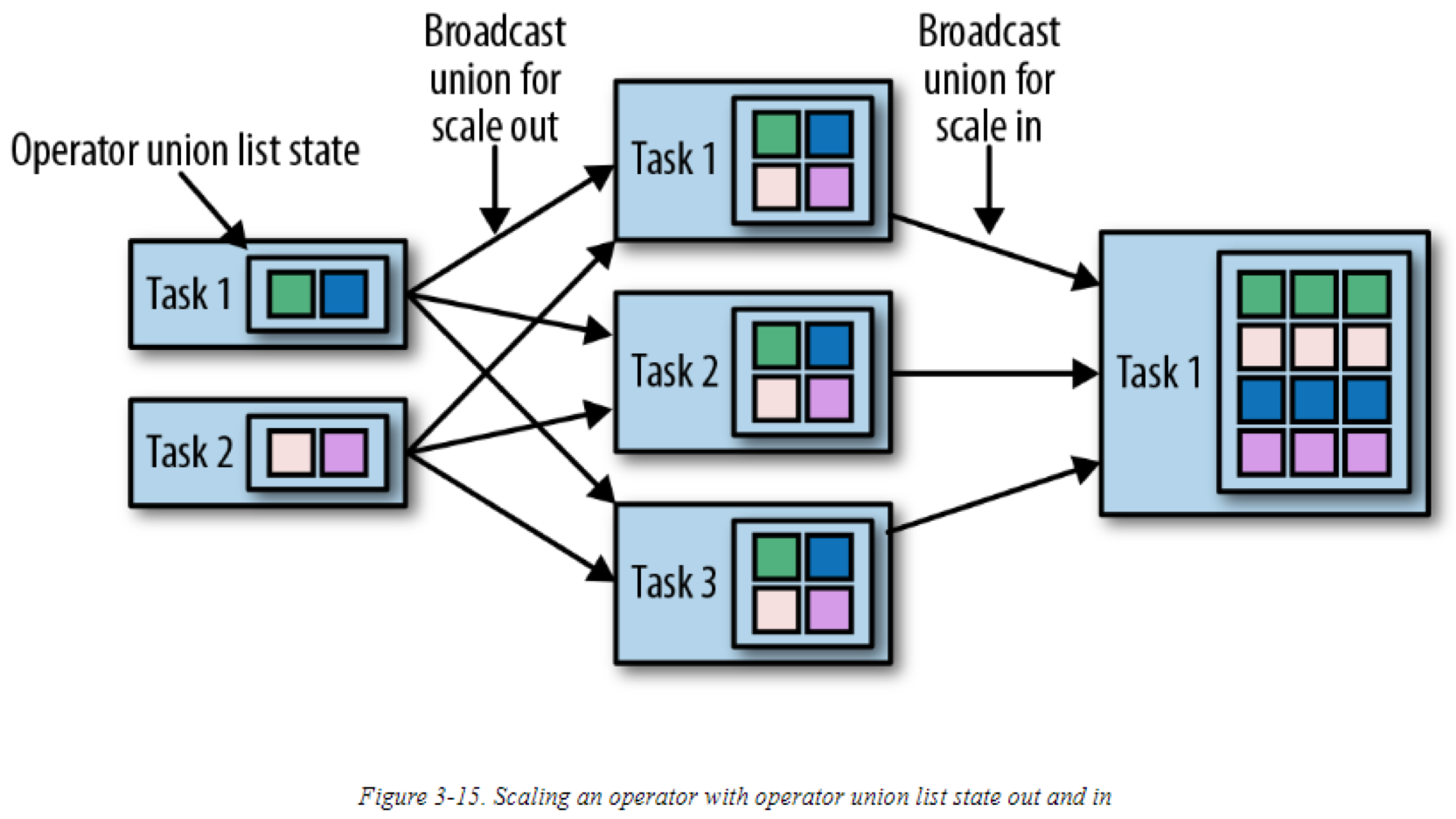
在扩展state 为union list state的operator时,列表中所有的state条目会被广播到每个task。Task之后可以选择使用哪些条目,丢弃哪些条目。下图显示了operator union list state 是如何重新分布的:
在扩展state为broadcast state 的operator时,state会被复制到新的task中。这里适用于这个操作是因为:广播state可以确保所有task有相同的state。在缩容时,多余的tasks会被简单地取消,因为state已经被复制了并且不会被丢失。下图显示的是operator broadcast state 的重新分布:

Normal
0
false
false
false
EN-US
ZH-CN
X-NONE
/* Style Definitions */
table.MsoNormalTable
{mso-style-name:"Table Normal";
mso-tstyle-rowband-size:0;
mso-tstyle-colband-size:0;
mso-style-noshow:yes;
mso-style-priority:99;
mso-style-parent:"";
mso-padding-alt:0cm 5.4pt 0cm 5.4pt;
mso-para-margin-top:0cm;
mso-para-margin-right:0cm;
mso-para-margin-bottom:8.0pt;
mso-para-margin-left:0cm;
line-height:107%;
mso-pagination:widow-orphan;
font-size:11.0pt;
font-family:Calibri;
mso-ascii-font-family:Calibri;
mso-ascii-theme-font:minor-latin;
mso-hansi-font-family:Calibri;
mso-hansi-theme-font:minor-latin;
mso-ansi-language:EN-US;}
References:
Vasiliki Kalavri, Fabian Hueske. Stream Processing With Apache Flink. 2019
Flink架构(四)- 状态管理的更多相关文章
- 【Vue】Vue学习(四)-状态管理中心Vuex的简单使用
一.vuex的简介 Vuex 是一个专为 Vue.js 应用程序开发的状态管理模式.Vuex背后的基本思想,就是前面所说的单向数据流.图4就是Vuex实现单向数据流的示意图. Store ...
- 总结Flink状态管理和容错机制
本文来自8月11日在北京举行的 Flink Meetup会议,分享来自于施晓罡,目前在阿里大数据团队部从事Blink方面的研发,现在主要负责Blink状态管理和容错相关技术的研发. 本文主要内容如 ...
- Flink状态管理和容错机制介绍
本文主要内容如下: 有状态的流数据处理: Flink中的状态接口: 状态管理和容错机制实现: 阿里相关工作介绍: 一.有状态的流数据处理# 1.1.什么是有状态的计算# 计算任务的结果不仅仅依赖于输入 ...
- 大数据计算引擎之Flink Flink状态管理和容错
这里将介绍Flink对有状态计算的支持,其中包括状态计算和无状态计算的区别,以及在Flink中支持的不同状态类型,分别有 Keyed State 和 Operator State .另外针对状态数据的 ...
- 理解vuex的状态管理模式架构
理解vuex的状态管理模式架构 一: 什么是vuex?官方解释如下:vuex是一个专为vue.js应用程序开发的状态管理模式.它采用集中式存储管理应用的所有组件的状态,并以相应的规则保证以一种可预测的 ...
- Flink架构(五)- 检查点,保存点,与状态恢复
检查点,保存点,与状态恢复 Flink是一个分布式数据处理系统,这种场景下,它需要处理各种异常,例如进程终止.机器故障.网络中断等.因为tasks在本地维护它们的state,Flink必须确保在出现故 ...
- Flink状态管理与状态一致性(长文)
目录 一.前言 二.状态类型 2.1.Keyed State 2.2.Operator State 三.状态横向扩展 四.检查点机制 4.1.开启检查点 (checkpoint) 4.2.保存点机制 ...
- 「Flink」Flink的状态管理与容错
在Flink中的每个函数和运算符都是有状态的.在处理过程中可以用状态来存储数据,这样可以利用状态来构建复杂操作.为了让状态容错,Flink需要设置checkpoint状态.Flink程序是通过chec ...
- 应用四:Vue之VUEX状态管理
(注:本文适用于有一定Vue基础或开发经验的读者,文章就知识点的讲解不一定全面,但却是开发过程中很实用的) 概念:Vuex 是一个专为 Vue.js 应用程序开发的状态管理模式.它采用集中式存储管理应 ...
随机推荐
- Navigation Nightmare POJ - 1984 带权并查集
#include<iostream> #include<cmath> #include<algorithm> using namespace std; ; // 东 ...
- Android_小账本小结
登录界面:支持登录.注册以及游客登录,单纯的小账本的话其实用不到这些个登录,单纯为了巩固学习知识. 尚未部署到服务器,账号等数据暂时保存在本地数据库中. 游客登陆:游客登录会直接跳到主页中,不影响使用 ...
- ECMAScript规范中第六大基本类型 Symbol
初步了解第六大基本类型Symbol 概述: 什么是Symbol.Symbol是一个标记,一个独一无二的记号. Symbol的出现主要是解决了以前ES5中两个问题 在属性中同名的属性会被覆盖 无法做到属 ...
- go语言 base58编码解码
package main import ( "bytes" "encoding/hex" "fmt" "math/big" ...
- 51Nod 1182 完美字符串 (贪心)
约翰认为字符串的完美度等于它里面所有字母的完美度之和.每个字母的完美度可以由你来分配,不同字母的完美度不同,分别对应一个1-26之间的整数. 约翰不在乎字母大小写.(也就是说字母F和f)的完美度相同. ...
- sql 注释解释
1 2 3 4 CREATE TABLE groups( gid INT PRIMARY KEY AUTO_INCREMENT COMMENT '设置主键自增', gname VARCHAR( ...
- Eclipse中配置Tomcat容器
Tomcat 安装与配置 Tomcat是Apache 软件基金会(Apache Software Foundation)核心项目之一,支持最新的Servlet 和JSP 规范.因为Tomcat 技术先 ...
- 对Ajax返回的json数据做处理报错
这个错误出现的原因是我再返回数据为json时,我页面的Ajax没有指定dataType: 'json'
- jfinal 拦截器中判断是否为pjax请求
个人博客 地址:http://www.wenhaofan.com/article/20180926013919 public class PjaxInterceptor implements Inte ...
- update(十)
Vue 的 _update 是实例的一个私有方法,它被调用的时机有 2 个,一个是首次渲染,一个是数据更新的时候:由于我们这一章节只分析首次渲染部分,数据更新部分会在之后分析响应式原理的时候涉及._u ...