Selenium实战(六)——数据驱动应用
一、数据驱动
由于大多数文章和资料都把“读取数据文件”看做数据驱动的标志,下面创建一个baidu_data.csv文件:

文件第一列为测试用例名称,第二列为搜索的关键字。接下来创建test_baidu_data.py文件:
import csv
import codecs
import unittest
from time import sleep
from itertools import islice
from selenium import webdriver class TestBaidu(unittest.TestCase): @classmethod
def setUpClass(cls):
cls.driver = webdriver.Chrome()
cls.base_url = "https://www.baidu.com" @classmethod
def tearDownClass(cls):
cls.driver.quit() def baidu_search(self, search_key):
self.driver.get(self.base_url)
self.driver.find_element_by_id("kw").send_keys(search_key)
self.driver.find_element_by_id("su").click()
sleep(3) def test_search(self):
with codecs.open('baidu_data.csv', 'r', 'utf_8_sig') as f:
data = csv.reader(f)
for line in islice(data, 1, None):
search_key = line[1]
self.baidu_search(search_key) if __name__ == '__main__':
unittest.main(verbosity=2)
这样做将所有的测试数据当做一条测试用例并行地执行,如果有一条测试数据有误就会导致这条测试用例执行失败,显然是不合理的。因此做如下修改:
import csv
import codecs
import unittest
from time import sleep
from itertools import islice
from selenium import webdriver class TestBaidu(unittest.TestCase): @classmethod
def setUpClass(cls):
cls.driver = webdriver.Chrome()
cls.base_url = "https://www.baidu.com"
cls.test_data = []
with codecs.open('baidu_data.csv', 'r', 'utf_8_sig') as f:
data = csv.reader(f)
for line in islice(data, 1, None):
cls.test_data.append(line) @classmethod
def tearDownClass(cls):
cls.driver.quit() def baidu_search(self, search_key):
self.driver.get(self.base_url)
self.driver.find_element_by_id("kw").send_keys(search_key)
self.driver.find_element_by_id("su").click()
sleep(3) def test_search_selenium(self):
self.baidu_search(self.test_data[0][1]) def test_search_unittest(self):
self.baidu_search(self.test_data[1][1]) def test_search_parameterized(self):
self.baidu_search(self.test_data[2][1]) if __name__ == '__main__':
unittest.main(verbosity=2)
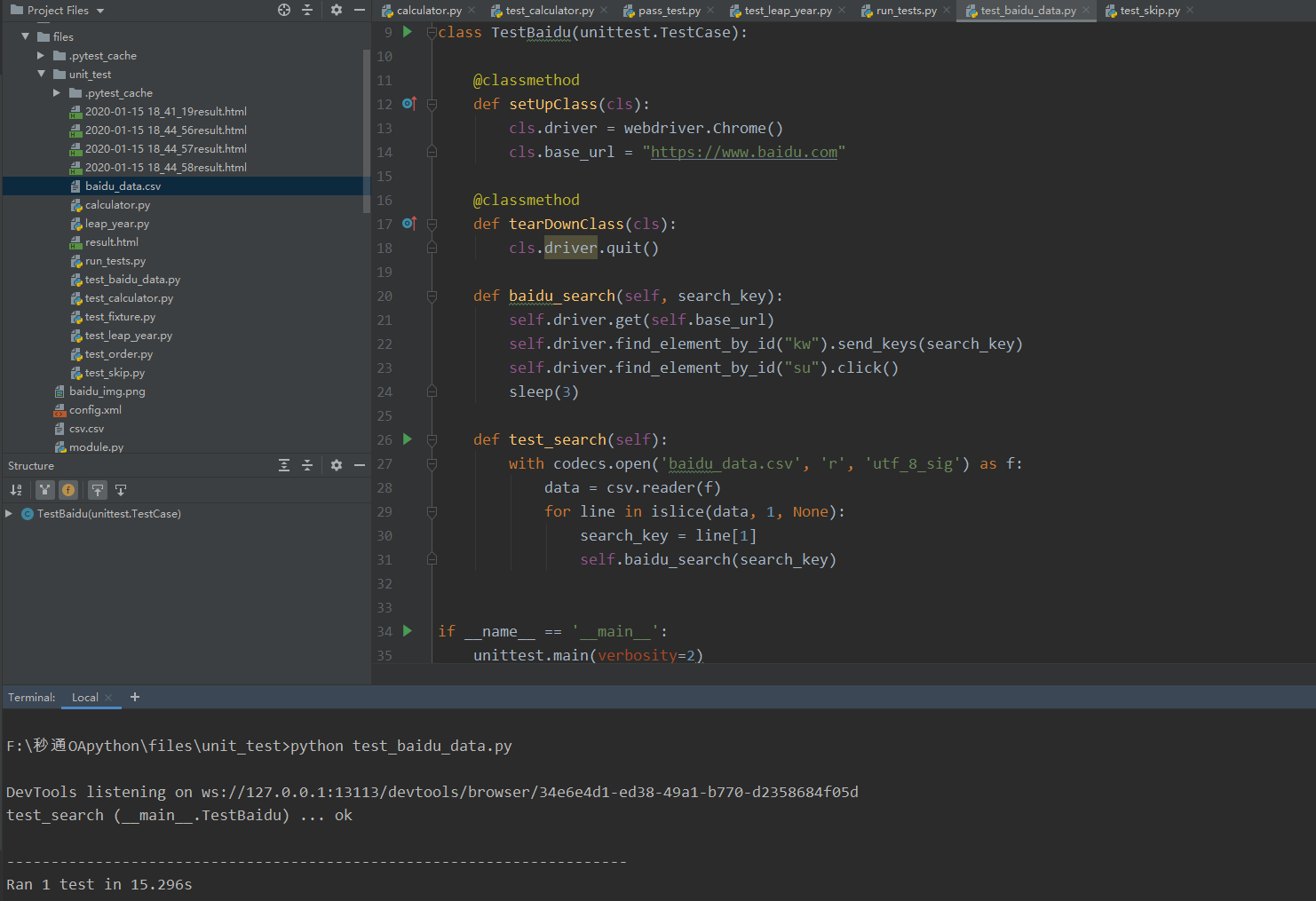
这一次,用setUpClass()方法读取baidu_data.csv文件,并将文件中的数据存储到test_data数组中,分别创建不同的测试方法使用test_data中的数据,结果如下

从测试结果可看出,存在以下问题:
- 增加了读取的成本。不管什么样的数据文件,在运行自动化测试用例前都需要将文件中的数据读取到程序中,这一步必不可少。
- 不方便维护。在CSV数据文件中,并不能直观体现出每一条数据对应的测试用例。而在测试用例中通过test_data[0][1]方式获取数据也存在很多问题,如果在csv文件中间插入了一条数据,那么测试用例获取到的测试数据很可能是错误的。
二、Parameterized
Parameterized是Python的一个参数化库,同时支持unittest、Nose和pytest单元测试框架。
GitHub地址:https://github.com/wolever/parameterized
Parameterized支持pip安装:pip install parameterized

导入parameterized后修改test_baidu_data.py文件如下:
import unittest
from time import sleep
from selenium import webdriver
from parameterized import parameterized class TestBaidu(unittest.TestCase): @classmethod
def setUpClass(cls):
cls.driver = webdriver.Chrome()
cls.base_url = "https://www.baidu.com" @classmethod
def tearDownClass(cls):
cls.driver.quit() def baidu_search(self, search_key):
self.driver.get(self.base_url)
self.driver.find_element_by_id("kw").send_keys(search_key)
self.driver.find_element_by_id("su").click()
sleep(3) # 通过Parameterized实现参数化
@parameterized.expand([
("case1", "selenium"),
("case2", "unittest"),
("case3", "parameterized"),
])
def test_search(self, name, search_key):
self.baidu_search(search_key)
self.assertEqual(self.driver.title, search_key + "_百度搜索") if __name__ == '__main__':
unittest.main(verbosity=2)
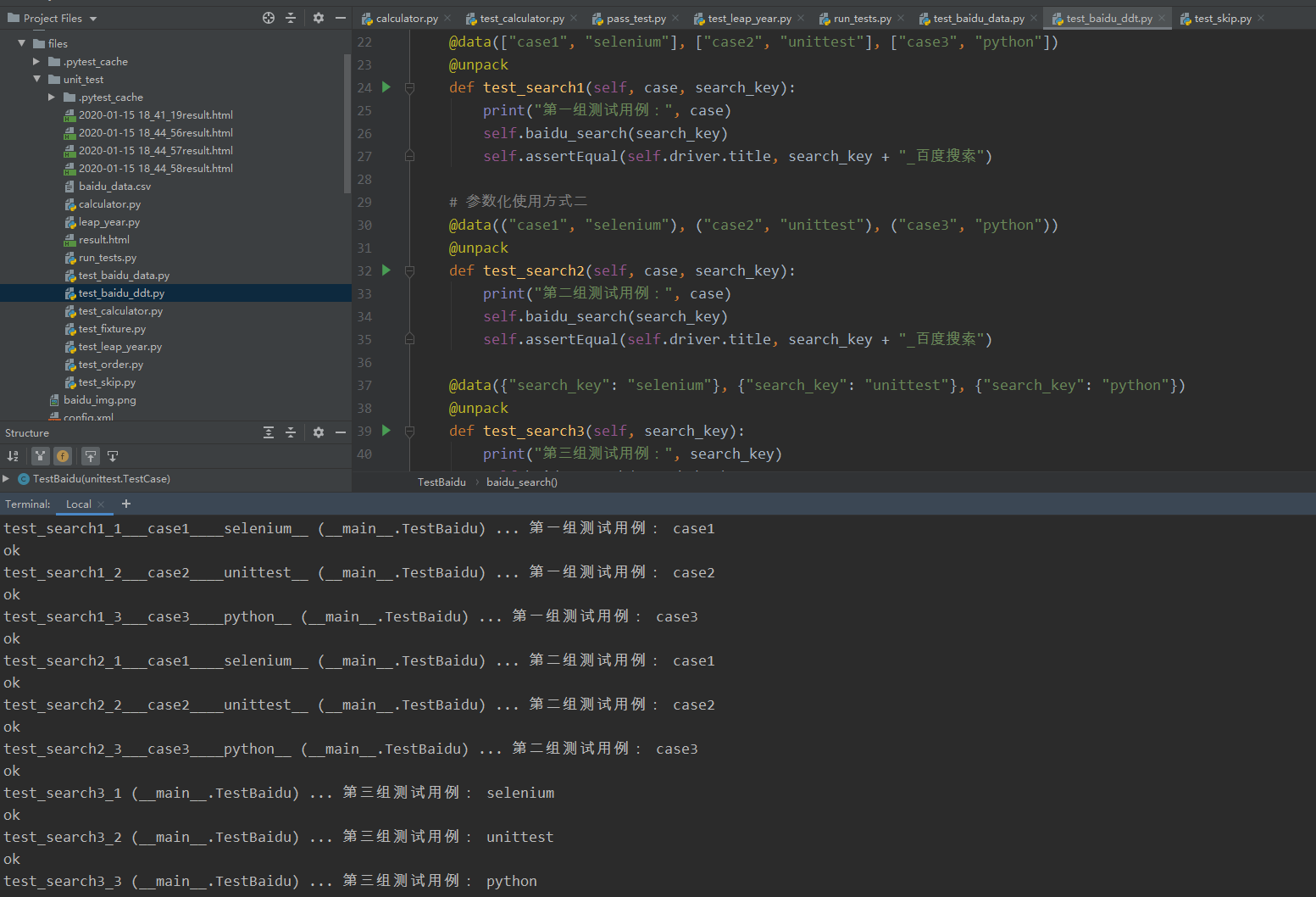
通过@parameterized.expand()来装饰测试用例test_search()。在@parameterized.expand()中,每个元组都可以被认为是一条测试用例。元组中的数据为该条测试测试用例变化的值。在测试用例中,通过参数来取每个元组中的数据。
在test_search()中,name参数对应元组中第一列数据,即"case1""case2""case3",用来定义测试用例的名称;search_key参数对应元组中第二列数据,即"sselenium""unittest""parameterized",用来定义搜索的关键字。
,
通过测试结果可以看到,因为是根据@parameterized.expand()中元组的个数来统计测试用例数的,所以产生了三条测试用例。test_search为定义的测试用例的名称。参数化会自动加上“0”、“1”、“2”来区分每条测试用例,在元组中定义的“case1”、“case2”、“case3”也会作为每条测试用例名称的后缀出现。
三、DDT
DDT(Data-Driven Tests)是针对unittest单元测试框架设计的扩展库。允许使用不同的测试数据来运行一个测试用例,并将其展示为多个测试用例。
GitHub地址:https://github.com/datadriventests/ddt
DDT支持pip安装:pip install ddt

创建一个test_baidu_ddt.py文件:
import unittest
from time import sleep
from selenium import webdriver
from ddt import ddt, data, file_data, unpack @ddt
class TestBaidu(unittest.TestCase): @classmethod
def setUpClass(cls):
cls.driver = webdriver.Chrome()
cls.base_url = "https://www.baidu.com" def baidu_search(self, search_key):
self.driver.get(self.base_url)
self.driver.find_element_by_id("kw").send_keys(search_key)
self.driver.find_element_by_id("su").click()
sleep(3) # 参数化使用方式一
@data(["case1", "selenium"], ["case2", "unittest"], ["case3", "python"])
@unpack
def test_search1(self, case, search_key):
print("第一组测试用例:", case)
self.baidu_search(search_key)
self.assertEqual(self.driver.title, search_key + "_百度搜索") # 参数化使用方式二
@data(("case1", "selenium"), ("case2", "unittest"), ("case3", "python"))
@unpack
def test_search2(self, case, search_key):
print("第二组测试用例:", case)
self.baidu_search(search_key)
self.assertEqual(self.driver.title, search_key + "_百度搜索") @data({"search_key": "selenium"}, {"search_key": "unittest"}, {"search_key": "python"})
@unpack
def test_search3(self, search_key):
print("第三组测试用例:", search_key)
self.baidu_search(search_key)
self.assertEqual(self.driver.title, search_key + "_百度搜索") @classmethod
def tearDownClass(cls):
cls.driver.quit() if __name__ == '__main__':
unittest.main(verbosity=2)
使用DDT需要注意以下几点:
- 首先,测试类需要通过@ddt进行装饰
- 其次,DDT提供了不同形式的参数化。这里列举了三组参数化,第一组为列表,第二组为元组,第三组为字典。需要注意的是,字典的key与测试方法的参数要保持一致。
同样的,DDT也支持数据文件的参数化。它封装了数据文件的读取,让我们更专注于数据文件中的内容,以及在测试用例中的使用,而不必关心数据文件时如何被读取进来的。
首先,创建ddt_data_file.json文件
{
"case1": {"search_key": "python"},
"case2": {"search_key": "ddt"},
"case3": {"search_key": "Selenium"}
}
在测试用例中使用ddt_data_file.json文件参数化测试用例,在test_baidu_ddt.py文件中增加测试用例数据:
# 参数化读取JSON文件
@file_data('ddt_data_file.json')
def test_search4(self, search_key):
print("第四组测试用例:", search_key)
self.baidu_search(search_key)
self.assertEqual(self.driver.title, search_key + "_百度搜索")

除此之外,DDT还支持yaml格式的数据文件。创建ddt_data_file.yaml文件:
case1:
- search_key: "python"
case2:
- search_key: "ddt"
case3:
- search_key: "Selenium"
在test_baidu_ddt.py文件中增加测试用例:
# 参数化读取yaml文件
@file_data('ddt_data_file.yaml')
def test_search5(self, case):
search_key = case[0]["search_key"]
print("第五组测试用例: ", search_key)
self.baidu_search(search_key)
self.assertEqual(self.driver.title, search_key + "_百度搜索")
执行结果如下:
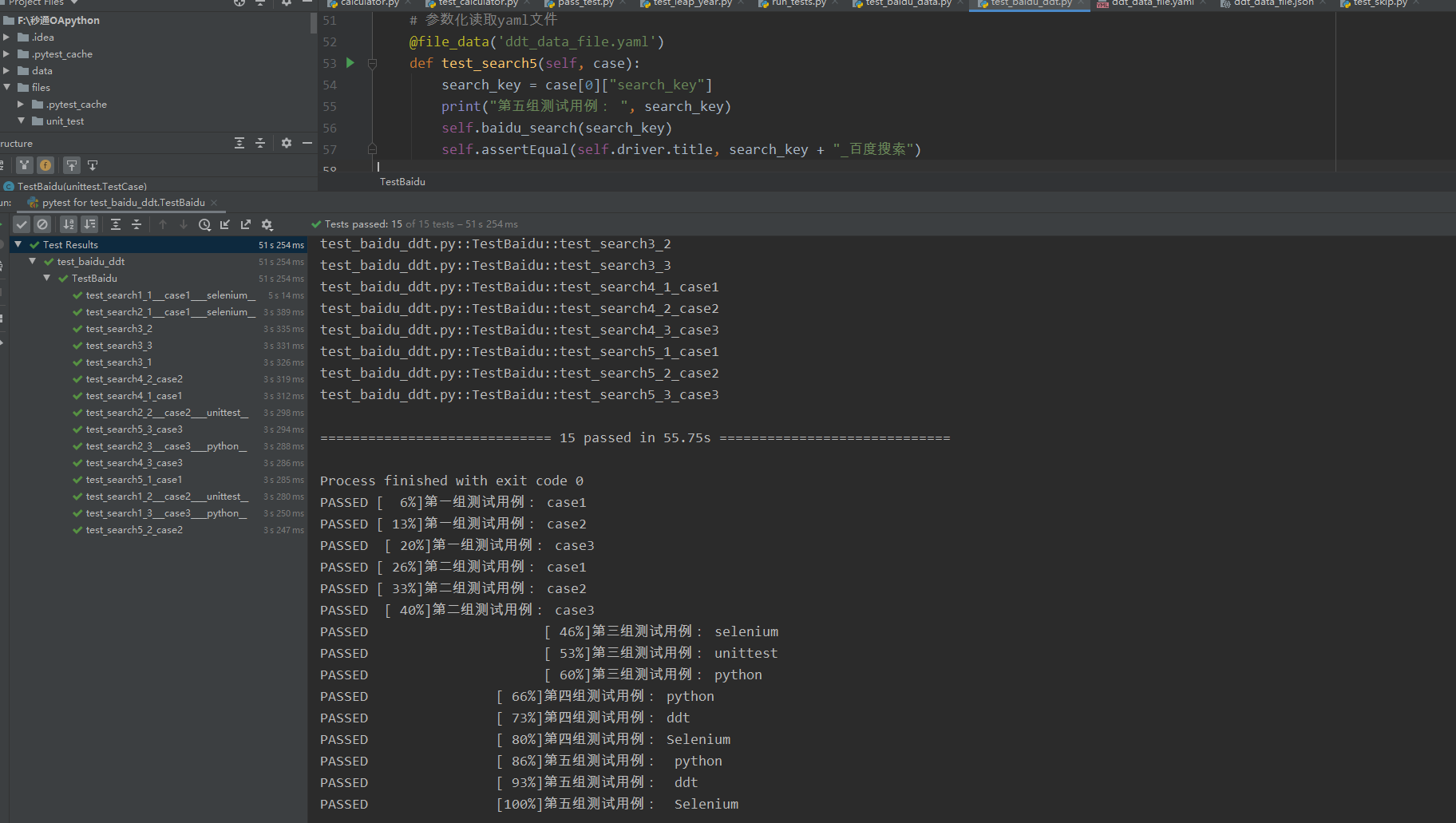
这里的取值与上面的JSON文件有所不同,因为每一条用例都被解析为[{'search_key':'python'}],所以要想渠道搜索关键字,则需要通过case[0]["search_key"]的方式获取。
Selenium实战(六)——数据驱动应用的更多相关文章
- selenium实战脚本集——新浪微博发送QQ每日焦点(火狐)
selenium实战脚本集(1)——新浪微博发送QQ每日焦点,乙醇用谷歌实现的,下边是用火狐实现的. 代码如下: # coding = utf-8 from selenium import webdr ...
- Selenium自动化测试之数据驱动及用例管理
Selenium自动化测试之数据驱动及用例管理 一.TestNg注解介绍 @Test:表示一个测试方法,在运行测试用例过程中,会自动运行@Test注解的方法. 例:
- Python爬虫实战六之抓取爱问知识人问题并保存至数据库
大家好,本次为大家带来的是抓取爱问知识人的问题并将问题和答案保存到数据库的方法,涉及的内容包括: Urllib的用法及异常处理 Beautiful Soup的简单应用 MySQLdb的基础用法 正则表 ...
- Selenium实战脚本集—新浪微博发送QQ每日焦点
Selenium实战脚本集-新浪微博发送QQ每日焦点 http://www.spasvo.com/ceshi/open/kygncsgj/Selenium/201549150822.html 背景 很 ...
- SpringSecurity权限管理系统实战—六、SpringSecurity整合jwt
目录 SpringSecurity权限管理系统实战-一.项目简介和开发环境准备 SpringSecurity权限管理系统实战-二.日志.接口文档等实现 SpringSecurity权限管理系统实战-三 ...
- miniFTP项目实战六
项目简介: 在Linux环境下用C语言开发的Vsftpd的简化版本,拥有部分Vsftpd功能和相同的FTP协议,系统的主要架构采用多进程模型,每当有一个新的客户连接到达,主进程就会派生出一个ftp服务 ...
- C# Redis实战(六)
六.查询数据 在C# Redis实战(五)中介绍了如何删除Redis中数据,本篇将继续介绍Redis中查询的写法. 1.使用Linq匹配关键字查询 using (var redisClient = R ...
- 1.selenium实战之从txt文档读取配置信息并执行登录
前置条件: 1.本机已搭建ECShop3.0网站 2.在脚本目录创建了user.txt文本如下: 目的:实现从txt中读取配置文件信息,本实战中,包含url地址.用户名.密码,然后进行ESChop的登 ...
- selenium实战脚本集(2)——简单的知乎爬虫
背景 很多同学在工作中是没有selenium的实战环境的,因此自学的同学会感到有力无处使,想学习但又不知道怎么练习.其实学习新东西的道理都是想通的,那就是反复练习.这里乙醇会给出一些有用的,也富有挑战 ...
随机推荐
- Java 设置Excel自适应行高、列宽
在excel中,可通过设置自适应行高或列宽自动排版,是一种比较常用的快速调整表格整体布局的方法.设置自适应时,可考虑2种情况: 1.固定数据,设置行高.列宽自适应数据(常见的设置自适应方法) 2.固定 ...
- java8数组
public class jh_01_为什么需要数组 { public static void main(String[] args) { int [] arr = new int[5]; // in ...
- python中的PYC文件是什么?
1. Python是一门解释型语言吗? 我初学Python时,听到的关于Python的第一句话就是,Python是一门解释性语言,我就这样一直相信下去,直到发现了*.pyc文件的存在.如果是解释型语言 ...
- mysql添加远程权限
mysql -u root -p grant all privileges on *.* to root@'%' identified by "password"; flush p ...
- zabbix的mysql优化后的配置文件
zabbix的mysql数据库导致磁盘IO一直90%以上,访问卡的一逼 改了配置文件最后好了 [root@root /]# cat /etc/my.cnf [mysqld] datadir=/Data ...
- 详解Net Core Web Api项目与在NginX下发布
前言 本文将介绍Net Core的一些基础知识和如何NginX下发布Net Core的WebApi项目. 测试环境 操作系统:windows 10 开发工具:visual studio 2019 框架 ...
- 《Java 8 in Action》Chapter 11:CompletableFuture:组合式异步编程
某个网站的数据来自Facebook.Twitter和Google,这就需要网站与互联网上的多个Web服务通信.可是,你并不希望因为等待某些服务的响应,阻塞应用程序的运行,浪费数十亿宝贵的CPU时钟周期 ...
- MySql存储引擎:innodb myisan memory
一.MySQL存在的常用存储引擎 存储引擎就是指表的类型,数据库的存储引擎决定了表在计算机中的存储方式. 使用show engines; (show engines\G;)可查看数据库支持的存储引擎 ...
- Python学习小记(5)---Magic Method
具体见The Python Language Reference 与Attribute相关的有 __get__ __set__ __getattribute__ __getattr__ __setat ...
- python实现自动点赞
1.思路通过pyautogui可以实现鼠标点击.滚动鼠标.截屏等操作.由此功能实现打开页面,进行点赞.aircv可以从大图像获得小图像的位置,利用pyautogui截屏得到的图片,可以在页面获取到每一 ...