Selenium实战(六)——数据驱动应用
一、数据驱动
由于大多数文章和资料都把“读取数据文件”看做数据驱动的标志,下面创建一个baidu_data.csv文件:

文件第一列为测试用例名称,第二列为搜索的关键字。接下来创建test_baidu_data.py文件:
import csv
import codecs
import unittest
from time import sleep
from itertools import islice
from selenium import webdriver class TestBaidu(unittest.TestCase): @classmethod
def setUpClass(cls):
cls.driver = webdriver.Chrome()
cls.base_url = "https://www.baidu.com" @classmethod
def tearDownClass(cls):
cls.driver.quit() def baidu_search(self, search_key):
self.driver.get(self.base_url)
self.driver.find_element_by_id("kw").send_keys(search_key)
self.driver.find_element_by_id("su").click()
sleep(3) def test_search(self):
with codecs.open('baidu_data.csv', 'r', 'utf_8_sig') as f:
data = csv.reader(f)
for line in islice(data, 1, None):
search_key = line[1]
self.baidu_search(search_key) if __name__ == '__main__':
unittest.main(verbosity=2)
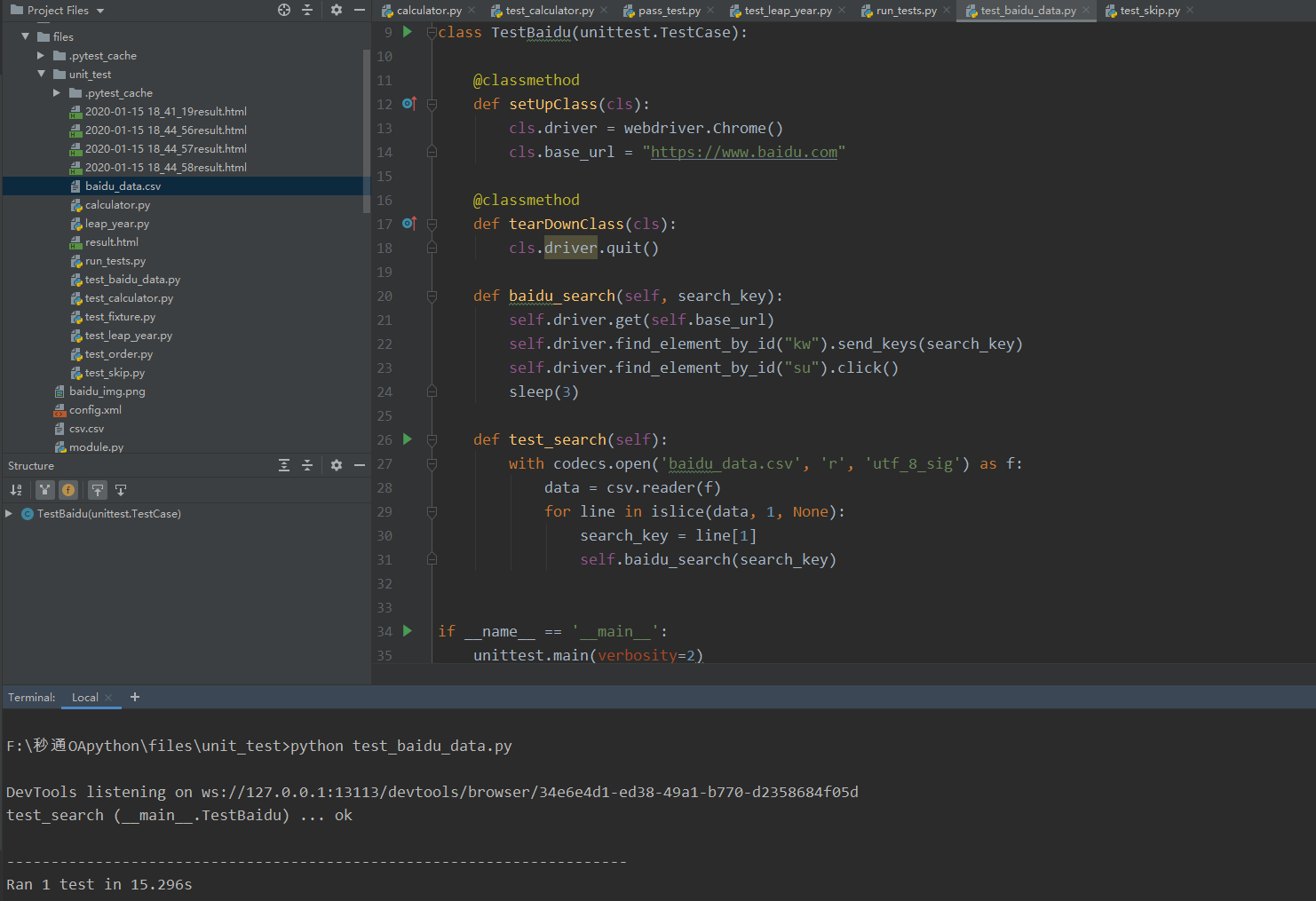
这样做将所有的测试数据当做一条测试用例并行地执行,如果有一条测试数据有误就会导致这条测试用例执行失败,显然是不合理的。因此做如下修改:
import csv
import codecs
import unittest
from time import sleep
from itertools import islice
from selenium import webdriver class TestBaidu(unittest.TestCase): @classmethod
def setUpClass(cls):
cls.driver = webdriver.Chrome()
cls.base_url = "https://www.baidu.com"
cls.test_data = []
with codecs.open('baidu_data.csv', 'r', 'utf_8_sig') as f:
data = csv.reader(f)
for line in islice(data, 1, None):
cls.test_data.append(line) @classmethod
def tearDownClass(cls):
cls.driver.quit() def baidu_search(self, search_key):
self.driver.get(self.base_url)
self.driver.find_element_by_id("kw").send_keys(search_key)
self.driver.find_element_by_id("su").click()
sleep(3) def test_search_selenium(self):
self.baidu_search(self.test_data[0][1]) def test_search_unittest(self):
self.baidu_search(self.test_data[1][1]) def test_search_parameterized(self):
self.baidu_search(self.test_data[2][1]) if __name__ == '__main__':
unittest.main(verbosity=2)
这一次,用setUpClass()方法读取baidu_data.csv文件,并将文件中的数据存储到test_data数组中,分别创建不同的测试方法使用test_data中的数据,结果如下

从测试结果可看出,存在以下问题:
- 增加了读取的成本。不管什么样的数据文件,在运行自动化测试用例前都需要将文件中的数据读取到程序中,这一步必不可少。
- 不方便维护。在CSV数据文件中,并不能直观体现出每一条数据对应的测试用例。而在测试用例中通过test_data[0][1]方式获取数据也存在很多问题,如果在csv文件中间插入了一条数据,那么测试用例获取到的测试数据很可能是错误的。
二、Parameterized
Parameterized是Python的一个参数化库,同时支持unittest、Nose和pytest单元测试框架。
GitHub地址:https://github.com/wolever/parameterized
Parameterized支持pip安装:pip install parameterized

导入parameterized后修改test_baidu_data.py文件如下:
import unittest
from time import sleep
from selenium import webdriver
from parameterized import parameterized class TestBaidu(unittest.TestCase): @classmethod
def setUpClass(cls):
cls.driver = webdriver.Chrome()
cls.base_url = "https://www.baidu.com" @classmethod
def tearDownClass(cls):
cls.driver.quit() def baidu_search(self, search_key):
self.driver.get(self.base_url)
self.driver.find_element_by_id("kw").send_keys(search_key)
self.driver.find_element_by_id("su").click()
sleep(3) # 通过Parameterized实现参数化
@parameterized.expand([
("case1", "selenium"),
("case2", "unittest"),
("case3", "parameterized"),
])
def test_search(self, name, search_key):
self.baidu_search(search_key)
self.assertEqual(self.driver.title, search_key + "_百度搜索") if __name__ == '__main__':
unittest.main(verbosity=2)
通过@parameterized.expand()来装饰测试用例test_search()。在@parameterized.expand()中,每个元组都可以被认为是一条测试用例。元组中的数据为该条测试测试用例变化的值。在测试用例中,通过参数来取每个元组中的数据。
在test_search()中,name参数对应元组中第一列数据,即"case1""case2""case3",用来定义测试用例的名称;search_key参数对应元组中第二列数据,即"sselenium""unittest""parameterized",用来定义搜索的关键字。
,
通过测试结果可以看到,因为是根据@parameterized.expand()中元组的个数来统计测试用例数的,所以产生了三条测试用例。test_search为定义的测试用例的名称。参数化会自动加上“0”、“1”、“2”来区分每条测试用例,在元组中定义的“case1”、“case2”、“case3”也会作为每条测试用例名称的后缀出现。
三、DDT
DDT(Data-Driven Tests)是针对unittest单元测试框架设计的扩展库。允许使用不同的测试数据来运行一个测试用例,并将其展示为多个测试用例。
GitHub地址:https://github.com/datadriventests/ddt
DDT支持pip安装:pip install ddt

创建一个test_baidu_ddt.py文件:
import unittest
from time import sleep
from selenium import webdriver
from ddt import ddt, data, file_data, unpack @ddt
class TestBaidu(unittest.TestCase): @classmethod
def setUpClass(cls):
cls.driver = webdriver.Chrome()
cls.base_url = "https://www.baidu.com" def baidu_search(self, search_key):
self.driver.get(self.base_url)
self.driver.find_element_by_id("kw").send_keys(search_key)
self.driver.find_element_by_id("su").click()
sleep(3) # 参数化使用方式一
@data(["case1", "selenium"], ["case2", "unittest"], ["case3", "python"])
@unpack
def test_search1(self, case, search_key):
print("第一组测试用例:", case)
self.baidu_search(search_key)
self.assertEqual(self.driver.title, search_key + "_百度搜索") # 参数化使用方式二
@data(("case1", "selenium"), ("case2", "unittest"), ("case3", "python"))
@unpack
def test_search2(self, case, search_key):
print("第二组测试用例:", case)
self.baidu_search(search_key)
self.assertEqual(self.driver.title, search_key + "_百度搜索") @data({"search_key": "selenium"}, {"search_key": "unittest"}, {"search_key": "python"})
@unpack
def test_search3(self, search_key):
print("第三组测试用例:", search_key)
self.baidu_search(search_key)
self.assertEqual(self.driver.title, search_key + "_百度搜索") @classmethod
def tearDownClass(cls):
cls.driver.quit() if __name__ == '__main__':
unittest.main(verbosity=2)
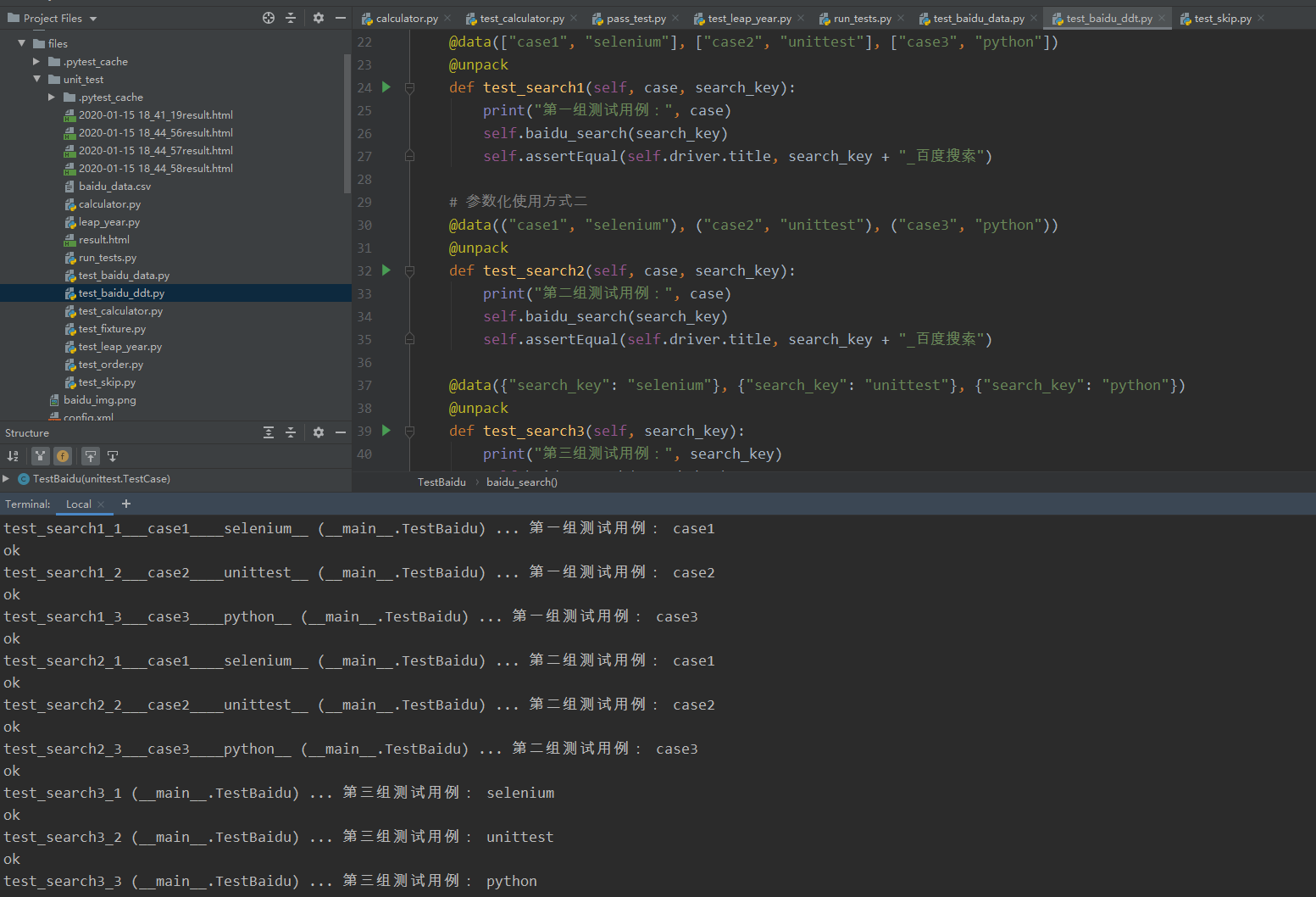
使用DDT需要注意以下几点:
- 首先,测试类需要通过@ddt进行装饰
- 其次,DDT提供了不同形式的参数化。这里列举了三组参数化,第一组为列表,第二组为元组,第三组为字典。需要注意的是,字典的key与测试方法的参数要保持一致。
同样的,DDT也支持数据文件的参数化。它封装了数据文件的读取,让我们更专注于数据文件中的内容,以及在测试用例中的使用,而不必关心数据文件时如何被读取进来的。
首先,创建ddt_data_file.json文件
{
"case1": {"search_key": "python"},
"case2": {"search_key": "ddt"},
"case3": {"search_key": "Selenium"}
}
在测试用例中使用ddt_data_file.json文件参数化测试用例,在test_baidu_ddt.py文件中增加测试用例数据:
# 参数化读取JSON文件
@file_data('ddt_data_file.json')
def test_search4(self, search_key):
print("第四组测试用例:", search_key)
self.baidu_search(search_key)
self.assertEqual(self.driver.title, search_key + "_百度搜索")

除此之外,DDT还支持yaml格式的数据文件。创建ddt_data_file.yaml文件:
case1:
- search_key: "python"
case2:
- search_key: "ddt"
case3:
- search_key: "Selenium"
在test_baidu_ddt.py文件中增加测试用例:
# 参数化读取yaml文件
@file_data('ddt_data_file.yaml')
def test_search5(self, case):
search_key = case[0]["search_key"]
print("第五组测试用例: ", search_key)
self.baidu_search(search_key)
self.assertEqual(self.driver.title, search_key + "_百度搜索")
执行结果如下:
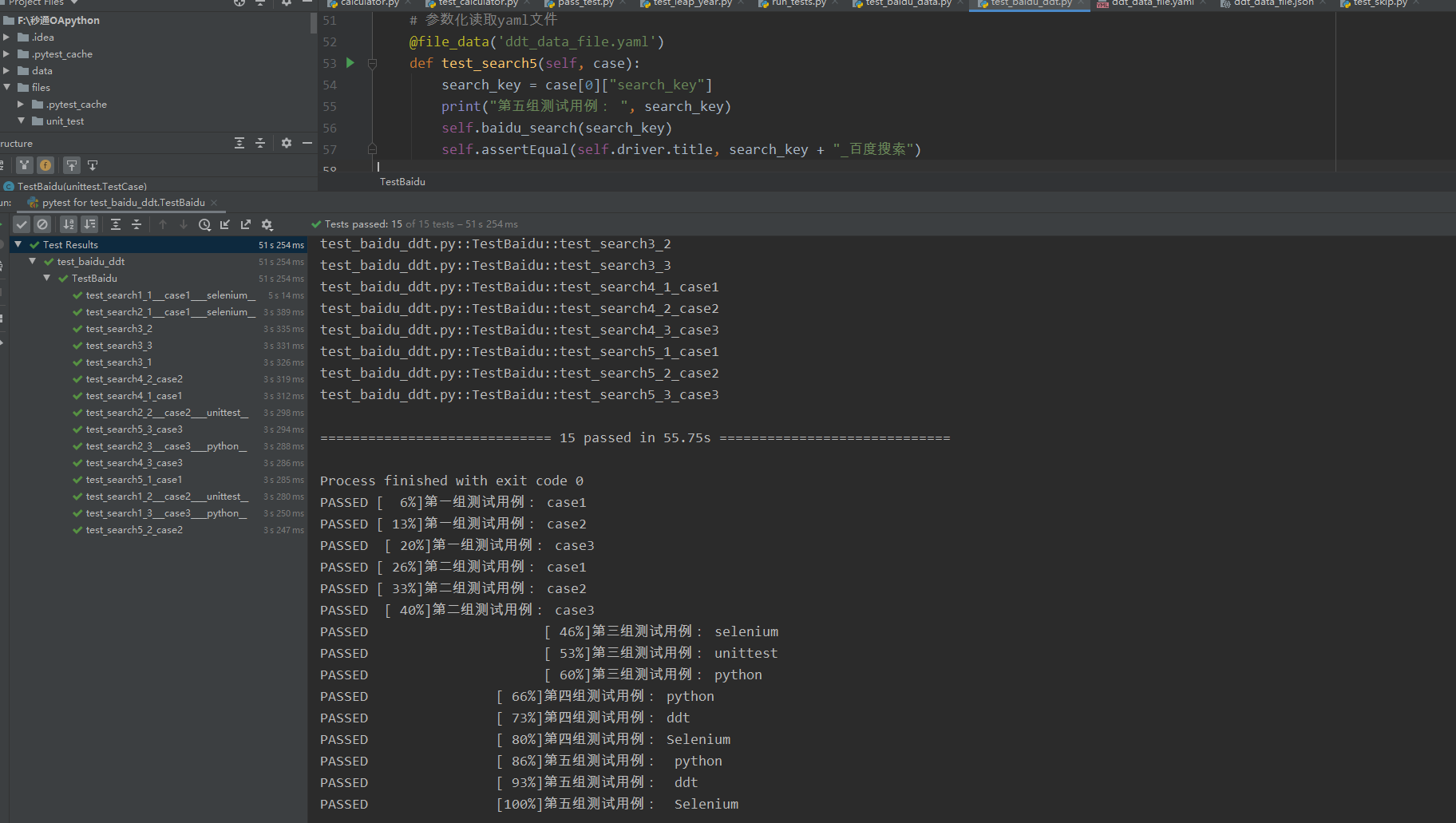
这里的取值与上面的JSON文件有所不同,因为每一条用例都被解析为[{'search_key':'python'}],所以要想渠道搜索关键字,则需要通过case[0]["search_key"]的方式获取。
Selenium实战(六)——数据驱动应用的更多相关文章
- selenium实战脚本集——新浪微博发送QQ每日焦点(火狐)
selenium实战脚本集(1)——新浪微博发送QQ每日焦点,乙醇用谷歌实现的,下边是用火狐实现的. 代码如下: # coding = utf-8 from selenium import webdr ...
- Selenium自动化测试之数据驱动及用例管理
Selenium自动化测试之数据驱动及用例管理 一.TestNg注解介绍 @Test:表示一个测试方法,在运行测试用例过程中,会自动运行@Test注解的方法. 例:
- Python爬虫实战六之抓取爱问知识人问题并保存至数据库
大家好,本次为大家带来的是抓取爱问知识人的问题并将问题和答案保存到数据库的方法,涉及的内容包括: Urllib的用法及异常处理 Beautiful Soup的简单应用 MySQLdb的基础用法 正则表 ...
- Selenium实战脚本集—新浪微博发送QQ每日焦点
Selenium实战脚本集-新浪微博发送QQ每日焦点 http://www.spasvo.com/ceshi/open/kygncsgj/Selenium/201549150822.html 背景 很 ...
- SpringSecurity权限管理系统实战—六、SpringSecurity整合jwt
目录 SpringSecurity权限管理系统实战-一.项目简介和开发环境准备 SpringSecurity权限管理系统实战-二.日志.接口文档等实现 SpringSecurity权限管理系统实战-三 ...
- miniFTP项目实战六
项目简介: 在Linux环境下用C语言开发的Vsftpd的简化版本,拥有部分Vsftpd功能和相同的FTP协议,系统的主要架构采用多进程模型,每当有一个新的客户连接到达,主进程就会派生出一个ftp服务 ...
- C# Redis实战(六)
六.查询数据 在C# Redis实战(五)中介绍了如何删除Redis中数据,本篇将继续介绍Redis中查询的写法. 1.使用Linq匹配关键字查询 using (var redisClient = R ...
- 1.selenium实战之从txt文档读取配置信息并执行登录
前置条件: 1.本机已搭建ECShop3.0网站 2.在脚本目录创建了user.txt文本如下: 目的:实现从txt中读取配置文件信息,本实战中,包含url地址.用户名.密码,然后进行ESChop的登 ...
- selenium实战脚本集(2)——简单的知乎爬虫
背景 很多同学在工作中是没有selenium的实战环境的,因此自学的同学会感到有力无处使,想学习但又不知道怎么练习.其实学习新东西的道理都是想通的,那就是反复练习.这里乙醇会给出一些有用的,也富有挑战 ...
随机推荐
- 聊聊CMDB的前世今生
CMDB,Configuration Management DataBase,配置管理数据库,是与 IT 系统所有组件相关的信息库,它包含 IT 基础架构配置项的详细信息. 传统运维思路下的CMDB, ...
- PT教程 - 应用系列 - ECO修复Timing(理论+实践+脚本分享)
本文转自:自己的微信公众号<集成电路设计及EDA教程> <PT教程 - 应用系列 - ECO修复Timing(理论+实践+脚本分享)> 这篇推文讲一下数字IC设计中的post ...
- virtualbox更新完无法启动的问题(不能为虚拟电脑 Ubuntu 打开一个新任务)
具体错误: 不能为虚拟电脑 Ubuntu 打开一个新任务. VT-x is disabled in the BIOS. (VERR_VMX_MSR_VMXON_DISABLED). 返回 代码: E_ ...
- C++输出中文字符
注:本文转载自互联网,感谢作者整理! 1. cout 场景1: 在源文件中定义 const char* str = "中文" 在 VC++ 编译器上,由于Windows环境用 ...
- 用Go语言在Linux下调用新中新DKQ-A16D读卡器,读二代证数据
1.背景 前几天用Python在Linux下成功的获取了二代证数据,最近正在学Go语言,这两天想着用Go语言也实现一下试看看. 2.开搞C++ 这次就比较简单了,直接把CppDemo里面的SynRea ...
- 2020牛客寒假算法基础集训营4 C : 子段乘积
C:子段乘积 考察点 : 线段树,尺取,乘法逆元 坑点 : 区间要做到不重不漏, long long 侃侃 : 这道题在比赛是写的尺取,但是写了半天发现不好处理除 0 问题(浮点错误),需要用到乘法逆 ...
- MetaWebLog API — 一个多平台文章同步的思路
文章选自我的博客:https://blog.ljyngup.com/archives/578.html/ 起因 为了给博客带来流量,我在CSDN,博客园,简书上开通了账号并且把博客里的一些可以发布的文 ...
- PPT导出图片质量太差?简单操作直接导出印刷质地图片
PPT导出图片质量太差?简单操作直接导出印刷质地图片 PPT不仅可以用于展示文档,还可以用于简单图片合成处理,同时,PPT文档还可以全部导出为图片. 默认情况下,PPT导出的图片为96DPI ...
- 云服务器centos系统安装python
1.查看python的版本 $ cd /usr/bin/$ ls python* $ ls -al python* //查看依赖关系 2.如果版本不合适可以卸载python再重新安装 # rpm -q ...
- 珠峰-webpack
##### webpack的优势.可以做哪里事情. ##### npx的运行原理 https://zhuanlan.zhihu.com/p/27840803 #### webpack的插件 html ...