【37】池化层讲解(Pooling layers)
池化层(Pooling layers)
除了卷积层,卷积网络也经常使用池化层来缩减模型的大小,提高计算速度,同时提高所提取特征的鲁棒性,我们来看一下。
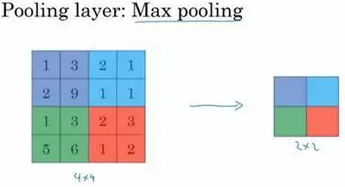
先举一个池化层的例子,然后我们再讨论池化层的必要性。假如输入是一个4×4矩阵,用到的池化类型是最大池化(max pooling)。执行最大池化的树池是一个2×2矩阵。执行过程非常简单,把4×4的输入拆分成不同的区域,我把这个区域用不同颜色来标记。对于2×2的输出,输出的每个元素都是其对应颜色区域中的最大元素值。
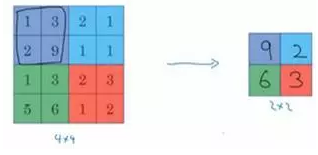
左上区域的最大值是9,右上区域的最大元素值是2,左下区域的最大值是6,右下区域的最大值是3。为了计算出右侧这4个元素值,我们需要对输入矩阵的2×2区域做最大值运算。这就像是应用了一个规模为2的过滤器,因为我们选用的是2×2区域,步幅是2,这些就是最大池化的超参数。
因为我们使用的过滤器为2×2,最后输出是9。然后向右移动2个步幅,计算出最大值2。然后是第二行,向下移动2步得到最大值6。最后向右移动3步,得到最大值3。这是一个2×2矩阵,即f=2,步幅是2,即s=2。
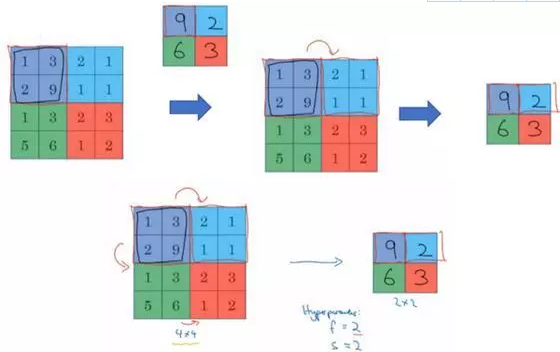
这是对最大池化功能的直观理解,你可以把这个4×4输入看作是某些特征的集合,也许不是。你可以把这个4×4区域看作是某些特征的集合,也就是神经网络中某一层的非激活值集合。
数字大意味着可能探测到了某些特定的特征,左上象限具有的特征可能是一个垂直边缘,一只眼睛,或是大家害怕遇到的CAP特征。显然左上象限中存在这个特征,这个特征可能是一只猫眼探测器。然而,右上象限并不存在这个特征。最大化操作的功能就是只要在任何一个象限内提取到某个特征,它都会保留在最大化的池化输出里。所以最大化运算的实际作用就是,如果在过滤器中提取到某个特征,那么保留其最大值。如果没有提取到这个特征,可能在右上象限中不存在这个特征,那么其中的最大值也还是很小,这就是最大池化的直观理解。
必须承认,人们使用最大池化的主要原因是此方法在很多实验中效果都很好。尽管刚刚描述的直观理解经常被引用,不知大家是否完全理解它的真正原因,不知大家是否理解最大池化效率很高的真正原因。
其中一个有意思的特点就是,它有一组超参数,但并没有参数需要学习。实际上,梯度下降没有什么可学的,一旦确定了f和s,它就是一个固定运算,梯度下降无需改变任何值。
我们来看一个有若干个超级参数的示例,输入是一个5×5的矩阵。我们采用最大池化法,它的过滤器参数为3×3,即f=3,步幅为1,s=1,输出矩阵是3×3。之前讲的计算卷积层输出大小的公式同样适用于最大池化,即(n+2p-f)/s+1,这个公式也可以计算最大池化的输出大小。
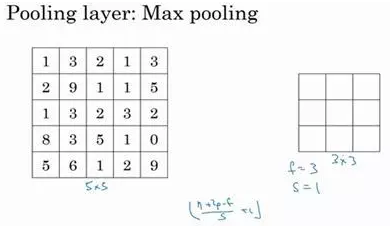
此例是计算3×3输出的每个元素,我们看左上角这些元素,注意这是一个3×3区域,因为有3个过滤器,取最大值9。然后移动一个元素,因为步幅是1,蓝色区域的最大值是9.继续向右移动,蓝色区域的最大值是5。然后移到下一行,因为步幅是1,我们只向下移动一个格,所以该区域的最大值是9。这个区域也是9。这两个区域的最大值都是5。最后这三个区域的最大值分别为8,6和9。超参数f=3,s=1,最终输出如图所示。
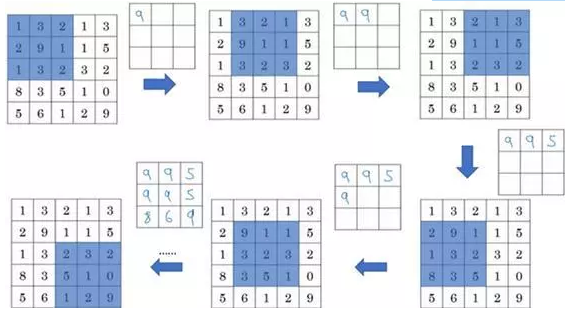
以上就是一个二维输入的最大池化的演示,如果输入是三维的,那么输出也是三维的。例如,输入是5×5×2,那么输出是3×3×2。计算最大池化的方法就是分别对每个通道执行刚刚的计算过程。如上图所示,第一个通道依然保持不变。对于第二个通道,我刚才画在下面的,在这个层做同样的计算,得到第二个通道的输出。一般来说,如果输入是5×5×n_c,输出就是3×3×n_c,n_c个通道中每个通道都单独执行最大池化计算,以上就是最大池化算法。

另外还有一种类型的池化,平均池化,它不太常用。我简单介绍一下,这种运算顾名思义,选取的不是每个过滤器的最大值,而是平均值。示例中,紫色区域的平均值是3.75,后面依次是1.25、4和2。这个平均池化的超级参数f=2,s=2,我们也可以选择其它超级参数。

目前来说,最大池化比平均池化更常用。但也有例外,就是深度很深的神经网络,你可以用平均池化来分解规模为7×7×1000的网络的表示层,在整个空间内求平均值,得到1×1×1000,一会我们看个例子。但在神经网络中,最大池化要比平均池化用得更多。
总结一下,池化的超级参数包括过滤器大小f和步幅s,常用的参数值为f=2,s=2,应用频率非常高,其效果相当于高度和宽度缩减一半。也有使用f=3,s=2的情况。至于其它超级参数就要看你用的是最大池化还是平均池化了。你也可以根据自己意愿增加表示padding的其他超级参数,虽然很少这么用。最大池化时,往往很少用到超参数padding,当然也有例外的情况,我们下周会讲。大部分情况下,最大池化很少用padding。目前p最常用的值是0,即p=0。最大池化的输入就是n_H×n_W×n_c,假设没有padding,则输出⌊(n_H-f)/s+1⌋×⌊(n_w-f)/s+1⌋×n_c。输入通道与输出通道个数相同,因为我们对每个通道都做了池化。需要注意的一点是,池化过程中没有需要学习的参数。执行反向传播时,反向传播没有参数适用于最大池化。只有这些设置过的超参数,可能是手动设置的,也可能是通过交叉验证设置的。

除了这些,池化的内容就全部讲完了。
最大池化只是计算神经网络某一层的静态属性,没有什么需要学习的,它只是一个静态属性。
关于池化我们就讲到这儿,现在我们已经知道如何构建卷积层和池化层了。下节课,我们会分析一个更复杂的可以引进全连接层的卷积网络示例。
【37】池化层讲解(Pooling layers)的更多相关文章
- tensorflow 1.0 学习:池化层(pooling)和全连接层(dense)
池化层定义在 tensorflow/python/layers/pooling.py. 有最大值池化和均值池化. 1.tf.layers.max_pooling2d max_pooling2d( in ...
- 图像处理池化层pooling和卷积核
1.池化层的作用 在卷积神经网络中,卷积层之间往往会加上一个池化层.池化层可以非常有效地缩小参数矩阵的尺寸,从而减少最后全连层中的参数数量.使用池化层即可以加快计算速度也有防止过拟合的作用. 2.为什 ...
- 神经网络中的池化层(pooling)
在卷积神经网络中,我们经常会碰到池化操作,而池化层往往在卷积层后面,通过池化来降低卷积层输出的特征向量,同时改善结果(不易出现过拟合).为什么可以通过降低维度呢? 因为图像具有一种“静态性”的属性,这 ...
- 深入解析CNN pooling 池化层原理及其作用
原文地址:https://blog.csdn.net/CVSvsvsvsvs/article/details/90477062 池化层作用机理我们以最简单的最常用的max pooling最大池化层为例 ...
- tensorflow的卷积和池化层(二):记实践之cifar10
在tensorflow中的卷积和池化层(一)和各种卷积类型Convolution这两篇博客中,主要讲解了卷积神经网络的核心层,同时也结合当下流行的Caffe和tf框架做了介绍,本篇博客将接着tenso ...
- caffe源码 池化层 反向传播
图示池化层(前向传播) 池化层其实和卷积层有点相似,有个类似卷积核的窗口按照固定的步长在移动,每个窗口做一定的操作,按照这个操作的类型可以分为两种池化层: 输入参数如下: 输入: 1 * 3 * 4 ...
- 空间金字塔池化(Spatial Pyramid Pooling, SPP)原理和代码实现(Pytorch)
想直接看公式的可跳至第三节 3.公式修正 一.为什么需要SPP 首先需要知道为什么会需要SPP. 我们都知道卷积神经网络(CNN)由卷积层和全连接层组成,其中卷积层对于输入数据的大小并没有要求,唯一对 ...
- 【深度学习篇】--神经网络中的池化层和CNN架构模型
一.前述 本文讲述池化层和经典神经网络中的架构模型. 二.池化Pooling 1.目标 降采样subsample,shrink(浓缩),减少计算负荷,减少内存使用,参数数量减少(也可防止过拟合)减少输 ...
- TensorFlow池化层-函数
池化层的作用如下-引用<TensorFlow实践>: 池化层的作用是减少过拟合,并通过减小输入的尺寸来提高性能.他们可以用来对输入进行降采样,但会为后续层保留重要的信息.只使用tf.nn. ...
随机推荐
- abp vnext2.0核心组件之领域实体组件源码解析
接着abp vnext2.0核心组件之模块加载组件源码解析和abp vnext2.0核心组件之.Net Core默认DI组件切换到AutoFac源码解析集合.Net Core3.1,基本环境已经完备, ...
- 【转载】计算机程序的思维逻辑 (82) - 理解ThreadLocal
本节,我们来探讨一个特殊的概念,线程本地变量,在Java中的实现是类ThreadLocal,它是什么?有什么用?实现原理是什么?让我们接下来逐步探讨. 基本概念和用法 线程本地变量是说,每个线程都有同 ...
- MFC对话框和控件
对话框和控件 对话框是Windows应用程序中一种常用的资源,其主要功能是输出信息和接收用户的输入数据.控件是嵌入在对话框中或其它父窗口中的一个特殊的小窗口,它用于完成不同的输入.输出功能.对话框与控 ...
- 【5min+】 这些C#的运算符您都认识吗?
系列介绍 [五分钟的dotnet]是一个利用您的碎片化时间来学习和丰富.net知识的博文系列.它所包含了.net体系中可能会涉及到的方方面面,比如C#的小细节,AspnetCore,微服务中的.net ...
- python 爬虫过程中出现:ConnectionResetError: [WinError 10054] 远程主机强迫关闭了一个现有的连接
参考: https://blog.csdn.net/illegalname/article/details/77164521
- eclipse运行python 安装pydev 版本匹配问题
Eclipse 4.5, Java 8: PyDev 5.2.0 PyDev 5.2.0 版本路径:https://dl.bintray.com/fabioz/pydev/5.2.0 1.安装时注意: ...
- uml图六种箭头的含义
转:https://blog.csdn.net/wglla/article/details/52225571 在看一些技术博客的时候,经常会见到博客里画上很多uml图.因为经常会被这几种表达关系的箭头 ...
- 《Python学习手册 第五版》 -第4章 介绍Python对象类型
本章的内容主要是介绍了Python的核心对象类型,后续的5.6.7.8.9章针对这些核心类型分别展开详细的说明 本章我认为重要的有几点 1.作者有谈到Python的知识结构,这个我感觉是一个大框架,可 ...
- java代码之美(15)---Java8 Function、Consumer、Supplier
Java8 Function.Consumer.Supplier 有关JDK8新特性之前写了三篇博客: 1.java代码之美(1)---Java8 Lambda 2.java代码之美(2)---Jav ...
- Go语言实现:【剑指offer】从上往下打印二叉树
该题目来源于牛客网<剑指offer>专题. 从上往下打印出二叉树的每个节点,同层节点从左至右打印. 不需分层,一维数组. Go语言实现: /** * Definition for a bi ...