Pandas简易入门(二)
目录:
处理缺失数据
制作透视图
删除含空数据的行和列
多行索引
使用apply函数
本节主要介绍如何处理缺失的数据,可以参考原文:https://www.dataquest.io/mission/12/working-with-missing-data
本节要处理的数据来自于泰坦尼克号的生存者名单,它的数据如下
|
pclass,survived,name,sex,age,sibsp,parch,ticket,fare,cabin,embarked,boat,body,home.dest 1,1,"Allen, Miss. Elisabeth Walton",female,29,0,0,24160,211.3375,B5,S,2,,"St Louis, MO" 1,1,"Allison, Master. Hudson Trevor",male,0.9167,1,2,113781,151.5500,C22 C26,S,11,,"Montreal, PQ / Chesterville, ON" 1,0,"Allison, Miss. Helen Loraine",female,2,1,2,113781,151.5500,C22 C26,S,,,"Montreal, PQ / Chesterville, ON" |
其中,pclass描述的是客舱等级,boat描述的是生存者搭乘的救生艇号码,body描述的是乘客的尸体编码。其中age和sex字段都有缺失的数据。由于不能对缺失数据进行运算,所以要先处理缺失的数据
处理缺失数据
首先,Pandas会用NaN(not a number)来表示一个缺失的数据,计算age字段为空的数据有多少行。Pandas有一个函数isnull()可以直接判断该列中的哪个数据为NaN
import pandas as pd file = ‘titanic_survival.csv’ titanic_survival = pd.read_csv(file) age_null = pd.isnull(titanic_survival[‘age’]) age_null_true = age_null[ age_null == True] age_null_count = len(age_null_true) #计算age字段的平均值 import pandas as pd mean_age = sum(titanic_survival["age"]) / len(titanic_survival["age"]) # mean_age的值为NaN,因为对NaN数据进行运算,结果也是NaN # 所以要先去除NaN数据 age_null = pd.isnull(titanic_survival["age"]) correct_mean_age = sum(titanic_survival['age'][age_null == False]) / len(titanic_survival['age'][age_null == False])
由于处理缺失数据很普遍,所以Pandas使用了一些可以自动过滤NaN的方法,譬如,mean()方法可以自动过滤缺失数据并计算平均值
correct_mean_age = titanic_survival["age"].mean()
总结:Pandas处理缺失数据的方法就是先用pd.isnull()来循环判断某列中的数据是否有空值,然后生成一个只有True或者False的列表,再把该列表中的False值传进该列中来得出不为空的数据
制作透视图
可以使用数据透视表汇总、分析、浏览和显示数据表数据概览或 外部数据 源。 数据透视表在您需要合计较大的数字列表时非常有用,聚合后的数据或分类汇总有助于您从不同角度查看数据和比较类似数据图表。

计算每一个客舱平均年龄,使用函数pivot_table()
import pandas as pd import numpy as np passenger_age = titanic_survival.pivot_table(index='pclass', values='age', aggfunc=np.mean)

# index参数指明了用来分类的列,values标签指明了用来计算的列,aggfunc指明了使用什么函数来计算values指定的列
# 如果要计算男性与女性的平均年龄
passenger_age = titanic_survival.pivot_table(index='sex', values='age', aggfunc=np.mean)

还可以制作更加复杂的透视图
譬如,要计算每一个客舱等级的平均年龄和费用
import numpy as np # 只要在values参数中增加参数即可 passenger_survival = titanic_survival.pivot_table(index="pclass", values=["age", "fare"], aggfunc=np.mean)

# 同样地,我要计算每个客舱等级中,每个性别的平均年龄和费用,则增加index的参数
passenger_survival = titanic_survival.pivot_table(index=["pclass","sex"], values=["age", "fare"], aggfunc=np.mean)

删除含有空数据的行和列
可以使用dropna()函数来删除具有空数据的行或列
import pandas as pd # 删除含有空数据的全部行 new_titanic_survival = titanic_survival.dropna() # 可以通过axis参数来删除含有空数据的全部列 new_titanic_survival = titanic_survival.dropna(axis=1) # 可以通过subset参数来删除在age和sex中含有空数据的全部行 new_titanic_survival = titanic_survival.dropna(subset=["age", "sex"]) print(new_titanic_survival) new_titanic_survival = titanic_survival.dropna(subset=['age', 'body','home.dest'])
多行索引
这是原始的titanic_survival

在我删除了那些body列为NaN的行之后,数据变成了下面这样
new_titanic_survival = titanic_survival.dropna(subset=["body"])
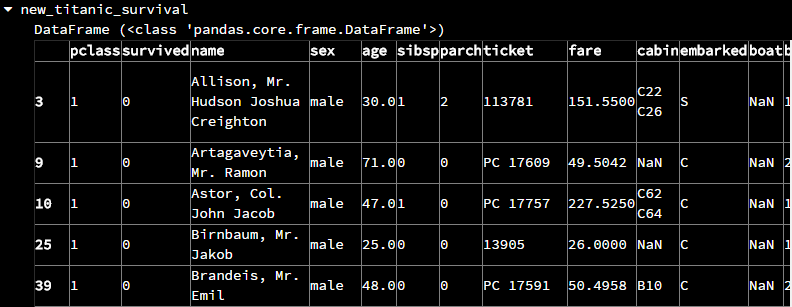
可见,在new_titanic_survival表中,行的索引仍然保持和之前一样,并没有重新从0开始计算。在上一篇的《Pandas简易入门(一)》中可以知道Pandas使用loc[ m ]函数来索引行号为m的那一行,或者loc[ m: n]来索引行号从m到n(包括n)的那些行,或者loc [[ m, n, o]]来索引行索引号为m, n, o的行。
但是,在重新生成的new_titanic_suvival中,行的索引号已经变得毫无规律,此时就要使用新的函数iloc[]来按照位置索引
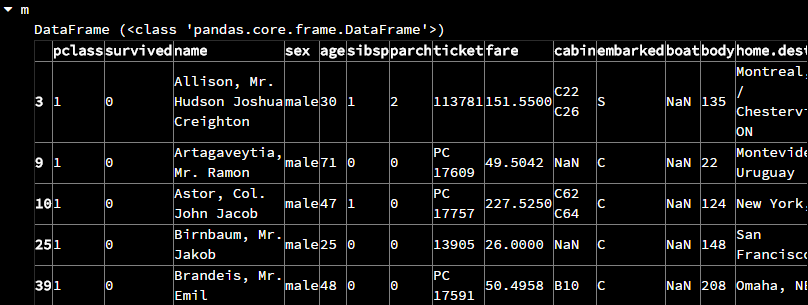
# 输出新表的前五行 m = new_titanic_survival.iloc[:5,:]
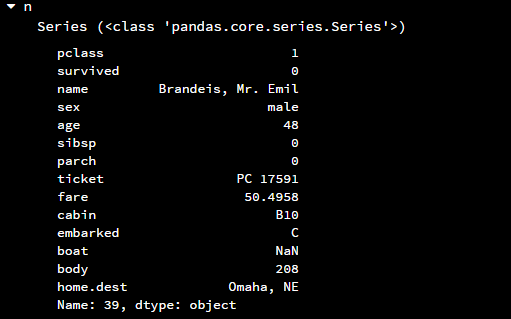
# 输出新表的第四行,注意仍然从0开始索引,所以在参数中填的是3而不是4 n = new_titanic_survival.iloc[3,:]
假如我想取出新表中第一行,第一列的那个值
m = new_titanic_survival.iloc[0,0] 等价于 n = new_titanic_survival.loc[3,"pclass"]
总结:iloc函数按照所在位置索引(iloc[]中的参数只能为整型值或者整型的分片),loc函数按照行号和列名索引
参考资料:http://pandas.pydata.org/pandas-docs/version/0.17.0/generated/pandas.DataFrame.iloc.html


看过上面就可以知道使用iloc来索引有多么的麻烦,实际上可以对新表进行索引重排序,使用reset_index()函数即可
titanic_reindexed = titanic_survival.dropna(subset=['age', 'boat']).reset_index(drop=True)
# drop函数用来指明是否不把原表中的index值作为一个新列放进新表

对比上图就看到行索引进行了重排序,如果drop参数为False
titanic_reindexed_false = titanic_survival.dropna(subset=['body']).reset_index(drop=False),就会生成如下格式

可以看到多了名为index的第一列,该值就是原表中的索引值
使用apply函数
之前我们已经计算了某一列中含有空值的数量,如果我要列出该表每一列中究竟有多少个空值呢,就可以使用apply(function)函数,该函数会将自定义的function函数应用在每一列中,并且把运行的结果保存在一个新的Series中,如下
import pandas as pd
# 这个函数返回一列中的空值数量
def null_count(column):
#首先用isnull函数判断该列中每个数值是否为空,生成一个只有True或者False的向量(列表)
column_null = pd.isnull(column)
# 把空值的那些数据提取出来,放在一个向量中
null = column[column_null == True]
# 返回该向量的长度即可
return len(null)
# 对所有的列都运行该函数
column_null_count = titanic_survival.apply(null_count)
print(column_null_count)

如果要把函数运行在全部行上,就是用axis参数即可
#对于每一行,假如该行的age字段缺失就显示unknown,age小于18就返回minor,age大于等于18就返回adult
def judge(row):
if pd.isnull(row['age']) == True :
return 'unknown'
return 'minor' if row['age'] < 18 else 'adult'
age_labels = titanic_survival.apply(judge, axis=1)
print(titanic_survival.columns)

Pandas简易入门(二)的更多相关文章
- Pandas简易入门(一)
目录: 读取数据 索引 选择数据 简单运算 声明,本文引用于:https://www.dataquest.io/mission/8/introduction-to-pandas (建议阅读原文) Pa ...
- Pandas简易入门(四)
本节主要介绍一下Pandas的另一个数据结构:DataFrame,本文的内容来源:https://www.dataquest.io/mission/147/pandas-internals-dataf ...
- Pandas简易入门(三)
本节主要介绍一下Pandas的数据结构,本文引用的网址:https://www.dataquest.io/mission/146/pandas-internals-series 本文所使用的数据来自于 ...
- Pandas 快速入门(二)
本文的例子需要一些特殊设置,具体可以参考 Pandas快速入门(一) 数据清理和转换 我们在进行数据处理时,拿到的数据可能不符合我们的要求.有很多种情况,包括部分数据缺失,一些数据的格式不正确,一些数 ...
- 机器学习简易入门(四)- logistic回归
摘要:使用logistic回归来预测某个人的入学申请是否会被接受 声明:(本文的内容非原创,但经过本人翻译和总结而来,转载请注明出处) 本文内容来源:https://www.dataquest.io/ ...
- 不用搭环境的10分钟AngularJS指令简易入门01(含例子)
不用搭环境的10分钟AngularJS指令简易入门01(含例子) `#不用搭环境系列AngularJS教程01,前端新手也可以轻松入坑~阅读本文大概需要10分钟~` AngularJS的指令是一大特色 ...
- pandas教程1:pandas数据结构入门
pandas是一个用于进行python科学计算的常用库,包含高级的数据结构和精巧的工具,使得在Python中处理数据非常快速和简单.pandas建造在NumPy之上,它使得以NumPy为中心的应用很容 ...
- Python pandas快速入门
Python pandas快速入门2017年03月14日 17:17:52 青盏 阅读数:14292 标签: python numpy 数据分析 更多 个人分类: machine learning 来 ...
- 【原创】NIO框架入门(二):服务端基于MINA2的UDP双向通信Demo演示
前言 NIO框架的流行,使得开发大并发.高性能的互联网服务端成为可能.这其中最流行的无非就是MINA和Netty了,MINA目前的主要版本是MINA2.而Netty的主要版本是Netty3和Netty ...
随机推荐
- 小白日记7:kali渗透测试之主动信息收集-发现(一)--二层发现:arping/shell脚本,Netdiscover,scapy
主动信息收集 被动信息收集可能不准确,可以用主动信息收集验证 特点:直接与目标系统交互通信,无法避免留下访问痕迹 解决方法:1.使用受控的第三方电脑进行探测,使用代理 (做好被封杀的准备) 2 ...
- Direct3D11-1 初始化
在使用一个东西之前,我们需要初始化他,好比汽车加油,手机充电.于是我们采取平时的编码习惯,试图写下如下代码 Direct3D11 _direct3d11; 事实上,我们 ...
- Mysql:表的操作
1.列的添加 2.列的删除 删除多列只需在DROP id 后加, DROP column_name; 3.显示表属性 4.设置默认值 5.删除默认值
- ruby 疑难点之—— attr_accessor attr_reader attr_writer
普通的实例变量 普通的实例变量,我们没法在 class 外面直接访问 #普通的实例变量,只能在 class 内部访问 class C1 def initialize(name) @name = nam ...
- [改善Java代码]多种最值算法,适时选择
建议64:多种最值算法,适时选择. 对一批数据进行排序,然后找出其中的最大值或最小值,这是基本的数据结构知识.在Java中我们可以通过编写算法的方式,也可以通过数组先排序再取值的方式来实现.下面以求最 ...
- Wince 设备环境和画笔应用
本文主要讲到的是画笔应用,在Wince -06环境下,画笔应用很广泛,很有技巧,这里笔者要着重介绍. 设备环境可以用一下图表示,主要是让大家大致了解Wince -06的设备环境,下面在图形舍虚设计中会 ...
- EF 实体+ Newtonsoft.Json 输出JSON 时动态忽略属性的解决方法
最近的项目采用的是 ASP.NET mvc 4.0 + entity framework 5.0 ,后台以JSON形式抛出数据是借助于Newtonsoft.Json , 要想忽略的属性前面添加特性 ...
- Linux C编程--main函数参数解析
我们经常用的main函数都是不带参数的.因此main 后的括号都是空括号.实际上,main函数可以带参数,这个参数可以认为是 main函数的形式参数.C语言规定main函数的参数只能有两个, 习惯上这 ...
- 自己封装的SqlHelper
using System; using System.Collections.Generic; using System.Configuration; using System.Data; using ...
- 第八篇、微信小程序-progress组件
主要属性: 效果图: ml: <View > <!--百分比是30,并在进度条右侧显示百分比--> <Text class="text-style"& ...