C# webrequest 抓取数据时,多个域Cookie的问题
最近研究了下如何抓取为知笔记的内容,在抓取笔记里的图片内容时,老是提示403错误,用Chorme的开发者工具看了下:
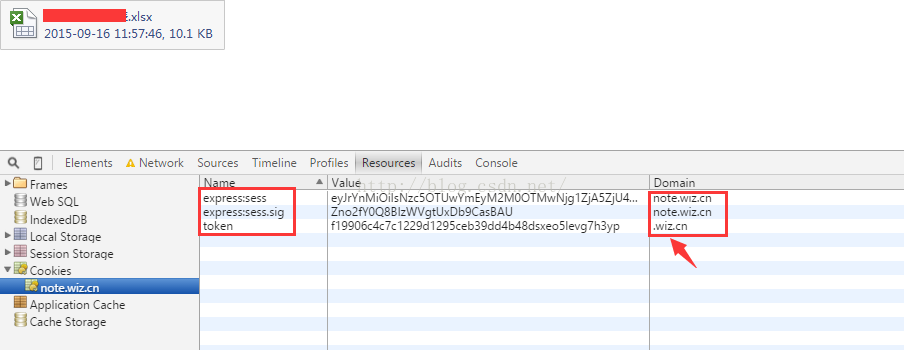
这里的Cookie来自两个域,估计为知那边是验证了token(登录后才能获取到token)
下载图片的代码:
- var path = "https://note.wiz.cn/" + str.TrimStart('/');
- var extension = Path.GetExtension(path);
- var filepath = AppPath.Combine("Images/" + DateTime.Now.Ticks + extension);
- const string userAgent ="Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/29.0.1547.76 Safari/537.36";
- const string accept = "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8";
- const string acceptLanguage = "zh-CN,zh;q=0.8";
- const string acceptEncoding = "gzip,deflate,sdch";
- var cookieContainer = new CookieContainer();
- var cookie = new Cookie
- {
- Name = "token".Trim(),
- Value = Token,
- Domain = ".wiz.cn".Trim() //设置cookie域
- };
- cookieContainer.Add(cookie);
- string[] cookiesArr = txtCookie.Text.Split(';');
- foreach (string s in cookiesArr)
- {
- string[] keyValuePair = s.Split('=');
- if (keyValuePair.Length > 1)
- {
- cookie = new Cookie
- {
- Name = keyValuePair[0].Trim(),
- Value = keyValuePair[1].Trim(),
- Domain = "note.wiz.cn" //设置cookie域
- };
- cookieContainer.Add(cookie);
- }
- }
- var newUri = new Uri(path);
- var webRequest = (HttpWebRequest)WebRequest.Create(newUri);
- webRequest.Timeout = 20000;
- //webRequest.CookieContainer = cookieContainer;
- webRequest.UserAgent = userAgent;
- webRequest.Accept = accept;
- webRequest.Headers["Accept-Language"] = acceptLanguage;
- webRequest.Headers["Accept-Charset"] = acceptEncoding;
- webRequest.Headers["Accept-Encoding"] = acceptEncoding;
- webRequest.KeepAlive = true;
- webRequest.Headers["Cache-Control"] = "no-cache";
- webRequest.Headers["Upgrade-Insecure-Requests"] = "1";
- webRequest.Headers["Pragma"] = "no-cache";
- webRequest.Headers["Cookie"] = "token=" + Token + ";" + txtCookie.Text.Trim();//todo: Cookie 要这样赋值,不能用CookieContainer??
- webRequest.Referer = newUri.AbsoluteUri;
- HttpWebResponse rsp = (HttpWebResponse)webRequest.GetResponse();
- Stream stream = null;
- stream = rsp.GetResponseStream();
- Image.FromStream(stream).Save(filepath);
- // 释放资源
- if (stream != null) stream.Close();
- if (rsp != null) rsp.Close();
奇怪的是:用 webRequest.CookieContainer = cookieContainer; 来跟cookie赋值,token参数总是赋不上,
后面改为:webRequest.Headers["Cookie"] = "token=" + Token + ";" + txtCookie.Text.Trim(); 就可以了,
CookieContainer 不是支持多个域的cookie吗,难到跨域Cookie只能webRequest.Headers["Cookie"]这样赋值吗? 没弄明白,有知道的童鞋不吝赐教。
C# webrequest 抓取数据时,多个域Cookie的问题的更多相关文章
- jsoup使用样式class抓取数据时空格的处理
最近在研究用android和jsoup抓取小说数据,jsoup的使用可以参照http://www.open-open.com/jsoup/;在抓纵横中文网永生这本书的目录内容时碰到了问题, 永生的书简 ...
- C# 从需要登录的网站上抓取数据
[转] C# 从需要登录的网站上抓取数据 背景:昨天一个学金融的同学让我帮她从一个网站上抓取数据,然后导出到excel,粗略看了下有1000+条记录,人工统计的话确实不可能.虽说不会,但作为一个学计算 ...
- Java模拟新浪微博登陆抓取数据
前言: 兄弟们来了来了,最近有人在问如何模拟新浪微博登陆抓取数据,我听后默默地抽了一口老烟,暗暗的对自己说,老汉是时候该你出场了,所以今天有时间就整理整理,浅谈一二. 首先: 要想登陆新浪微博需要 ...
- 测试开发Python培训:抓取新浪微博抓取数据-技术篇
测试开发Python培训:抓取新浪微博抓取数据-技术篇 poptest是国内唯一一家培养测试开发工程师的培训机构,以学员能胜任自动化测试,性能测试,测试工具开发等工作为目标.在poptest的se ...
- C#抓取数据、正则表达式+线程池初步运用
去年底用 多线程+HtmlAgilityPack.dll 写了一个抓取“慧聪网” 公司信息的小程序,代码惨不忍赌.好在能抓到数据,速度也能让人忍受就很久没管了. 最近这段时间把这个小程序发给同事看着玩 ...
- PHP Curl模拟登录并抓取数据
使用PHP的Curl扩展库可以模拟实现登录,并抓取一些需要用户账号登录以后才能查看的数据.具体实现的流程如下(个人总结): 1. 首先需要对相应的登录页面的html源代码进行分析,获得一些必要的信息: ...
- 爬虫学习笔记(1)-- 利用Python从网页抓取数据
最近想从一个网站上下载资源,懒得一个个的点击下载了,想写一个爬虫把程序全部下载下来,在这里做一个简单的记录 Python的基础语法在这里就不多做叙述了,黑马程序员上有一个基础的视频教学,可以跟着学习一 ...
- Web Scraper 翻页——控制链接批量抓取数据
 这是简易数据分析系列的第 5 ...
- Web Scraper 翻页——控制链接批量抓取数据(Web Scraper 高级用法)| 简易数据分析 05
这是简易数据分析系列的第 5 篇文章. 上篇文章我们爬取了豆瓣电影 TOP250 前 25 个电影的数据,今天我们就要在原来的 Web Scraper 配置上做一些小改动,让爬虫把 250 条电影数据 ...
随机推荐
- 第10月第21天 手势识别 开屏广告 Xcode快捷键
1.手势识别 http://yulingtianxia.com/blog/2016/12/29/Multimedia-Edit-Module-Architecture-Design/ 2.开屏广告 h ...
- Django安装配置
django2.0基础 一.安装与项目的创建 1.安装 pip install django 2.查看版本 python -m django --version 3.创建项目 django-admin ...
- Kali社会工程学攻击--powershell 攻击(无视防火墙)
1.打开setoolkit 输入我们反弹shell的地址与端口 2.修改我的shellcode 3.攻击成功
- ocky勒索软件恶意样本分析2
locky勒索软件恶意样本分析2 阿尔法实验室陈峰峰.胡进 前言 随着安全知识的普及,公民安全意识普遍提高了,恶意代码传播已经不局限于exe程序了,Locky敲诈者病毒就是其中之一,Locky敲诈者使 ...
- windows常用设置
1.截图 A.QQ打开,ctrl + Alt + A B. cmd 输入 截图工具 2.录制windows操作步骤 命令行输入:psr.exe
- mysql grep database error(cannot rmdir /dbname)
service mysql stop cd /var/lib/mysql/dbname rm -rf .fmr rm -rf .txt service mysql start srop databas ...
- Linux 内核中断内幕【转】
转自:http://www.ibm.com/developerworks/cn/linux/l-cn-linuxkernelint/ 本文对中断系统进行了全面的分析与探讨,主要包括中断控制器.中断分类 ...
- eclipse安装阿里巴巴java开发规范插件
阿里巴巴java开发规范插件 作为JAVA开发人员,始终没有一个明确的规范,何为好代码,何为坏代码,造成不同人的代码风格不同,接手别人代码后改造起来相当困难.前不久,阿里巴巴发布了<阿里巴巴Ja ...
- navicate连接Linux下mysql慢,卡,以及mysql相关查询,授权
方法,网上的办法是在my.ini的“[mysqld]”下面加入一行“skip-name-resolve”,就像这样: 然后保存并重启mysql服务即可. service mysqld restart ...
- Java编程的逻辑 (24) - 异常 (上)
本系列文章经补充和完善,已修订整理成书<Java编程的逻辑>,由机械工业出版社华章分社出版,于2018年1月上市热销,读者好评如潮!各大网店和书店有售,欢迎购买,京东自营链接:http: ...