CS229 6.16 Neurons Networks linear decoders and its implements
Sparse AutoEncoder是一个三层结构的网络,分别为输入输出与隐层,前边自编码器的描述可知,神经网络中的神经元都采用相同的激励函数,Linear Decoders 修改了自编码器的定义,对输出层与隐层采用了不用的激励函数,所以 Linear Decoder 得到的模型更容易应用,而且对模型的参数变化有更高的鲁棒性。
在网络中的前向传导过程中的公式:
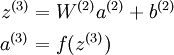
其中 a(3) 是输出. 在自编码器中, a(3) 近似重构了输入 x = a(1) 。
对于最后一层为 sigmod(tanh) 激活函数的 autoencoder ,会直接将数据归一化到 [0,1] ,所以当 f(z(3)) 采用 sigmod(tanh) 函数时,就要对输入限制或缩放,使其位于 [0,1] 范围中。但是对于输入数据 x ,比如 MNIST,但是很难满足 x 也在 [0,1] 的要求。比如, PCA 白化处理的输入并不满足 [0,1] 范围要求。
另 a(3) = z(3) 可以很简单的解决上述问题。即在输出端使用恒等函数 f(z) = z 作为激励函数,于是有 a(3) = f(z(3)) = z(3)。该特殊的激励函数叫做 线性激励 (恒等激励)函数。
Linear Decoder 中隐含层的神经元依然使用 sigmod(tanh)激励函数。隐含单元的激励公式为 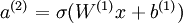 ,其中
,其中 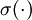 是 S 型函数, x 是入, W(1) 和 b(1) 分别是隐单元的权重和偏差项。即仅在输出层中使用线性激励函数。这用一个 S 型或 tanh 隐含层以及线性输出层构成的自编码器,叫做线性解码器。
是 S 型函数, x 是入, W(1) 和 b(1) 分别是隐单元的权重和偏差项。即仅在输出层中使用线性激励函数。这用一个 S 型或 tanh 隐含层以及线性输出层构成的自编码器,叫做线性解码器。
在线性解码器中,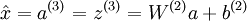 。因为输出
。因为输出 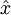 是隐单元激励输出的线性函数,改变 W(2) ,即可使输出值 a(3) 大于 1 或者小于 0。这样就可以避免在 sigmod 对输出层的值缩放到 [0,1] 。
是隐单元激励输出的线性函数,改变 W(2) ,即可使输出值 a(3) 大于 1 或者小于 0。这样就可以避免在 sigmod 对输出层的值缩放到 [0,1] 。
随着输出单元的激励函数的改变,输出单元的梯度也相应变化。之前每一个输出单元误差项定义为:
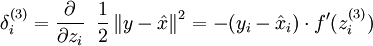
其中 y = x 是所期望的输出, 是自编码器的输出, 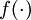 是激励函数.因为在输出层激励函数为 f(z) = z, 这样 f'(z) = 1,所以上述公式可以简化为
是激励函数.因为在输出层激励函数为 f(z) = z, 这样 f'(z) = 1,所以上述公式可以简化为
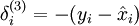
当然,若使用反向传播算法来计算隐含层的误差项时:
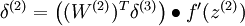
因为隐含层采用一个 S 型(或 tanh)的激励函数 f,在上述公式中,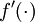 依然是 S 型(或 tanh)函数的导数。即Linear Decoder中只有输出层残差是不同于autoencoder 的。
依然是 S 型(或 tanh)函数的导数。即Linear Decoder中只有输出层残差是不同于autoencoder 的。
Liner Decoder 代码:
%% CS294A/CS294W Linear Decoder Exercise % Instructions
% ------------
%
% This file contains code that helps you get started on the
% linear decoder exericse. For this exercise, you will only need to modify
% the code in sparseAutoencoderLinearCost.m. You will not need to modify
% any code in this file. %%======================================================================
%% STEP : Initialization
% Here we initialize some parameters used for the exercise. imageChannels = ; % number of channels (rgb, so 3) patchDim = ; % patch dimension(需要 8*8 的小patches)
numPatches = ; % number of patches
% 把8 * * rgb_size 的小patchs 共同作为可见层的unit数目
visibleSize = patchDim * patchDim * imageChannels; % number of input units
outputSize = visibleSize; % number of output units
hiddenSize = ; % number of hidden units sparsityParam = .; % desired average activation of the hidden units.
lambda = 3e-; % weight decay parameter
beta = ; % weight of sparsity penalty term epsilon = .; % epsilon for ZCA whitening %%======================================================================
%% STEP : Create and modify sparseAutoencoderLinearCost.m to use a linear decoder,
% and check gradients
% You should copy sparseAutoencoderCost.m from your earlier exercise
% and rename it to sparseAutoencoderLinearCost.m.
% Then you need to rename the function from sparseAutoencoderCost to
% sparseAutoencoderLinearCost, and modify it so that the sparse autoencoder
% uses a linear decoder instead. Once that is done, you should check
% your gradients to verify that they are correct. % NOTE: Modify sparseAutoencoderCost first! % To speed up gradient checking, we will use a reduced network and some
% dummy patches debugHiddenSize = ;
debugvisibleSize = ;
patches = rand([ ]);
theta = initializeParameters(debugHiddenSize, debugvisibleSize); [cost, grad] = sparseAutoencoderLinearCost(theta, debugvisibleSize, debugHiddenSize, ...
lambda, sparsityParam, beta, ...
patches); % Check gradients
numGrad = computeNumericalGradient( @(x) sparseAutoencoderLinearCost(x, debugvisibleSize, debugHiddenSize, ...
lambda, sparsityParam, beta, ...
patches), theta); % Use this to visually compare the gradients side by side
disp([numGrad grad]); diff = norm(numGrad-grad)/norm(numGrad+grad);
% Should be small. In our implementation, these values are usually less than 1e-.
disp(diff); assert(diff < 1e-, 'Difference too large. Check your gradient computation again'); % NOTE: Once your gradients check out, you should run step again to
% reinitialize the parameters
%} %%======================================================================
%% STEP : Learn features on small patches
% In this step, you will use your sparse autoencoder (which now uses a
% linear decoder) to learn features on small patches sampled from related
% images. %% STEP 2a: Load patches
% In this step, we load 100k patches sampled from the STL10 dataset and
% visualize them. Note that these patches have been scaled to [,] load stlSampledPatches.mat displayColorNetwork(patches(:, :)); %% STEP 2b: Apply preprocessing
% In this sub-step, we preprocess the sampled patches, in particular,
% ZCA whitening them.
%
% In a later exercise on convolution and pooling, you will need to replicate
% exactly the preprocessing steps you apply to these patches before
% using the autoencoder to learn features on them. Hence, we will save the
% ZCA whitening and mean image matrices together with the learned features
% later on. % Subtract mean patch (hence zeroing the mean of the patches)
meanPatch = mean(patches, );
patches = bsxfun(@minus, patches, meanPatch);% - mean % Apply ZCA whitening
sigma = patches * patches' / numPatches;
[u, s, v] = svd(sigma);
%一下是打算对数据做ZCA变换,数据需要做的变换的矩阵
ZCAWhite = u * diag(1 ./ sqrt(diag(s) + epsilon)) * u';
%这一步是ZCA变换
patches = ZCAWhite * patches; displayColorNetwork(patches(:, :)); %% STEP 2c: Learn features
% You will now use your sparse autoencoder (with linear decoder) to learn
% features on the preprocessed patches. This should take around minutes. theta = initializeParameters(hiddenSize, visibleSize); % Use minFunc to minimize the function
addpath minFunc/ options = struct;
options.Method = 'lbfgs';
options.maxIter = ;
options.display = 'on'; [optTheta, cost] = minFunc( @(p) sparseAutoencoderLinearCost(p, ...
visibleSize, hiddenSize, ...
lambda, sparsityParam, ...
beta, patches), ...
theta, options); % Save the learned features and the preprocessing matrices for use in
% the later exercise on convolution and pooling
fprintf('Saving learned features and preprocessing matrices...\n');
save('STL10Features.mat', 'optTheta', 'ZCAWhite', 'meanPatch');
fprintf('Saved\n'); %% STEP 2d: Visualize learned features
%这里为什么要用(W*ZCAWhite)'呢?首先,使用W*ZCAWhite是因为每个样本x输入网络,
%其输出等价于W*ZCAWhite*x;另外,由于W*ZCAWhite的每一行才是一个隐含节点的变换值
%而displayColorNetwork函数是把每一列显示一个小图像块的,所以需要对其转置。
W = reshape(optTheta(1:visibleSize * hiddenSize), hiddenSize, visibleSize);
b = optTheta(2*hiddenSize*visibleSize+1:2*hiddenSize*visibleSize+hiddenSize);
displayColorNetwork( (W*ZCAWhite)'); function [cost,grad,features] = sparseAutoencoderLinearCost(theta, visibleSize, hiddenSize, ...
lambda, sparsityParam, beta, data)
% -------------------- YOUR CODE HERE --------------------
% Instructions:
% Copy sparseAutoencoderCost in sparseAutoencoderCost.m from your
% earlier exercise onto this file, renaming the function to
% sparseAutoencoderLinearCost, and changing the autoencoder to use a
% linear decoder.
% -------------------- YOUR CODE HERE -------------------- %将数据由向量转化为矩阵:
W1 = reshape(theta(:hiddenSize*visibleSize), hiddenSize, visibleSize);
W2 = reshape(theta(hiddenSize*visibleSize+:*hiddenSize*visibleSize), visibleSize, hiddenSize);
b1 = theta(*hiddenSize*visibleSize+:*hiddenSize*visibleSize+hiddenSize);
b2 = theta(*hiddenSize*visibleSize+hiddenSize+:end); %样本数
m = size(data ,); %%%%%%%%%%% forward %%%%%%%%%%%
z2 = W1*data + repmat(b1, [,m]);
a2 = f(z2);
z3 = W2*a2 + repmat(b2, [,m]);
a3 = z3; %求当前网络的平均激活度
rho_hat = mean(a2 ,);
rho = sparsityParam;
%对隐层所有节点的散度求和。
KL_Divergence = sum(rho * log(rho ./ rho_hat) + log((- rho) ./ (-rho_hat))); squares = (a3- data).^;
J_square_err = (/)*(/m)* sum(squares(:));
J_weight_decay = (lambd/)*(sum(W1(:).^) + sum(W2(:).^));
J_sparsity = beta * KL_Divergence; cost = J_square_err + J_weight_decay + J_sparsity; %%%%%%%%%%% backward %%%%%%%%%%%
delta3 = -(data-a3);% 注意 linear decoder
beta_term = beta * (- rho ./ rho_hat + (-rho) ./ (-rho_hat));
delta2 = (W2' * delta3) * repmat(beta_term, [1,m]) .* a2 .*(1-a2); W2grad = (1/m) * delta3 * a2' + lambda * W2;
b2grad = (/m) * sum(delta3, );
W1grad = (/m) * delta2 * data' + lambda * W1;
b1grad = (1/m) * sum(delta2, 2);
%-------------------------------------------------------------------
% Convert weights and bias gradients to a compressed form
% This step will concatenate and flatten all your gradients to a vector
% which can be used in the optimization method.
grad = [W1grad(:) ; W2grad(:) ; b1grad(:) ; b2grad(:)]; end
%-------------------------------------------------------------------
% We are giving you the sigmoid function, you may find this function
% useful in your computation of the loss and the gradients.
function sigm = sigmoid(x) sigm = 1 ./ (1 + exp(-x));
end
CS229 6.16 Neurons Networks linear decoders and its implements的更多相关文章
- (六)6.16 Neurons Networks linear decoders and its implements
Sparse AutoEncoder是一个三层结构的网络,分别为输入输出与隐层,前边自编码器的描述可知,神经网络中的神经元都采用相同的激励函数,Linear Decoders 修改了自编码器的定义,对 ...
- CS229 6.10 Neurons Networks implements of softmax regression
softmax可以看做只有输入和输出的Neurons Networks,如下图: 其参数数量为k*(n+1) ,但在本实现中没有加入截距项,所以参数为k*n的矩阵. 对损失函数J(θ)的形式有: 算法 ...
- CS229 6.1 Neurons Networks Representation
面对复杂的非线性可分的样本是,使用浅层分类器如Logistic等需要对样本进行复杂的映射,使得样本在映射后的空间是线性可分的,但在原始空间,分类边界可能是复杂的曲线.比如下图的样本只是在2维情形下的示 ...
- CS229 6.17 Neurons Networks convolutional neural network(cnn)
之前所讲的图像处理都是小 patchs ,比如28*28或者36*36之类,考虑如下情形,对于一副1000*1000的图像,即106,当隐层也有106节点时,那么W(1)的数量将达到1012级别,为了 ...
- CS229 6.15 Neurons Networks Deep Belief Networks
Hintion老爷子在06年的science上的论文里阐述了 RBMs 可以堆叠起来并且通过逐层贪婪的方式来训练,这种网络被称作Deep Belife Networks(DBN),DBN是一种可以学习 ...
- CS229 6.2 Neurons Networks Backpropagation Algorithm
今天得主题是BP算法.大规模的神经网络可以使用batch gradient descent算法求解,也可以使用 stochastic gradient descent 算法,求解的关键问题在于求得每层 ...
- CS229 6.14 Neurons Networks Restricted Boltzmann Machines
1.RBM简介 受限玻尔兹曼机(Restricted Boltzmann Machines,RBM)最早由hinton提出,是一种无监督学习方法,即对于给定数据,找到最大程度拟合这组数据的参数.RBM ...
- CS229 6.13 Neurons Networks Implements of stack autoencoder
对于加深网络层数带来的问题,(gradient diffuse 局部最优等)可以使用逐层预训练(pre-training)的方法来避免 Stack-Autoencoder是一种逐层贪婪(Greedy ...
- CS229 6.12 Neurons Networks from self-taught learning to deep network
self-taught learning 在特征提取方面完全是用的无监督的方法,对于有标记的数据,可以结合有监督学习来对上述方法得到的参数进行微调,从而得到一个更加准确的参数a. 在self-taug ...
随机推荐
- 弄清SDI显示工程中的每一个信号,每一个逻辑
弄清SDI显示工程中的每一个信号,每一个逻辑 1. FIFO外部逻辑控制 FIFO的读和写在不同的时钟域,所以读和写的控制逻辑应当分开写在不同的两个always块语句中. 2.播出端复位信号的产生 : ...
- MYSQL优化浅谈,工具及优化点介绍,mysqldumpslow,pt-query-digest,explain等
MYSQL优化浅谈 msyql是开发常用的关系型数据库,快速.稳定.开源等优点就不说了. 个人认为,项目上线,标志着一个项目真正的开始.从运维,到反馈,到再分析,再版本迭代,再优化… 这是一个漫长且考 ...
- 内存共享【Delphi版】
一.原理 通过使用“内存映射文件”,实现内存共享 二.主要操作 共享内存结构: PShareMem = ^TShareMem; TShareMem = Record id:string ...
- OpenTSDB(时序数据库官网)
官网地址:http://opentsdb.net/ 下载地址:https://github.com/OpenTSDB/opentsdb/releases ----------------------- ...
- Myeclipse 2017安装
一.下载 Myeclipse官网下载地址:http://www.myeclipsecn.com/download/ 二.安装 安装详细步骤省略,仅仅是一路下一步即可,博主默认安装到了C盘,注意:安装完 ...
- Base64 转 图片
static void Main(string[] args) { string s = "iVBORw0KGgoAAAANSUhEUgAAAFAAAABQCAIAAAABc2X6AAAAC ...
- 在CAD二次开发中使用状态条按钮
Pane pane = new Pane(); pane.Enabled = true; pane.Text = "状态条按钮"; pane.ToolTipText = " ...
- ALGO-118_蓝桥杯_算法训练_连续正整数的和
问题描述 78这个数可以表示为连续正整数的和,++,+++,++. 输入一个正整数 n(<=) 输出 m 行(n有m种表示法),每行是两个正整数a,b,表示a+(a+)+...+b=n. 对于多 ...
- 【springboot】之利用shell脚本优雅启动,关闭springboot服务
springbot开发api接口服务,生产环境中一般都是运行独立的jar,在部署过程中涉及到服务的优雅启动,关闭, springboot官方文档给出的有两种方式, 1.使用http shutdown ...
- STL基础--算法(修改数据的算法)
修改元素的算法 copy, move, transform, swap, fill, replace, remove vector<int> vec = {9,60,70,8,45,87, ...