【Spark算子】:reduceByKey、groupByKey和combineByKey
在spark中,reduceByKey、groupByKey和combineByKey这三种算子用的较多,结合使用过程中的体会简单总结:
我的代码实践:https://github.com/wwcom614/Spark
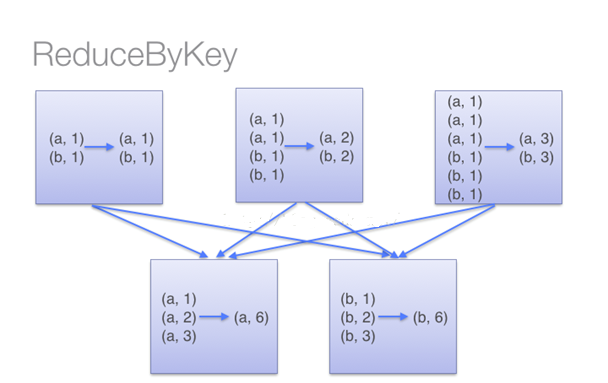
•reduceByKey
用于对每个key对应的多个value进行merge操作,最重要的是它能够在本地先进行merge操作,并且merge操作可以通过函数自定义;
•groupByKey
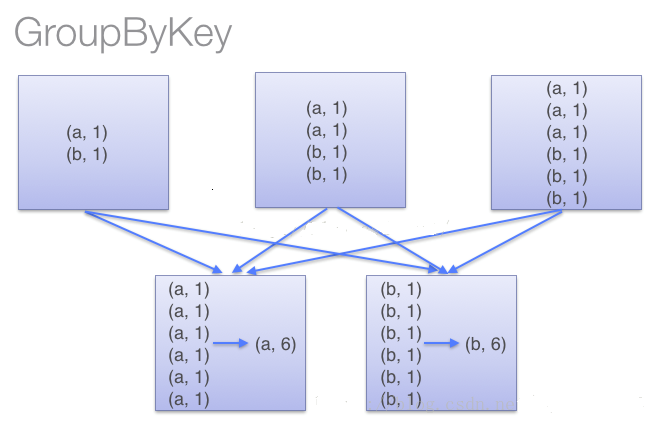
也是对每个key进行操作,但只生成一个sequence,groupByKey本身不能自定义函数,需要先用groupByKey生成RDD,然后才能对此RDD通过map进行自定义函数操作。
使用groupByKey时,spark会将所有的键值对进行移动,不会进行局部merge,会导致集群节点之间的开销很大,导致传输延时。
•combineByKey
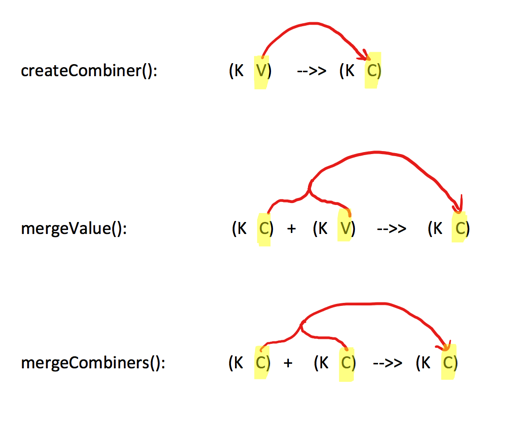
一个相对底层的基于键进行聚合的基础方法(因为大多数基于键聚合的方法,例如reduceByKey,groupByKey都是用它实现的),所以感觉这个方法还是挺重要的。
该方法的入参主要为前三个:
- createCombiner:遍历一个分区中每个元素,如果不存在,createCombiner创建累加器C,把原变量V放入,对相同K,把V合并成一个集合,例如将(key,88),映射建立集合(key,(88,1))
- mergeValue:遍历一个分区中每个元素,如果已存在,将相同的值累加,例如将(key,(88,1)),(key,(88,1)),mergeValue累加集合为(key,(88,2))
- mergeCombiners:createCombiner 和 mergeValue 是处理单个分区中数据, mergeCombiners是每个分区处理完了,多个分区合并数据使用,例如分区1累加集合值为(key,(88,2)),分区2累加集合值为(key,(88,3)),mergeCombiners累加集合为(key,(88,5))
写个求每个学生的平均成绩的例子
//2个学生及他们的成绩
val scoreList = Array(("ww1", 88), ("ww1", 95), ("ww2", 91), ("ww2", 93), ("ww2", 95), ("ww2", 98)) //将2个学生成绩转为RDD,分2个partition存储
val scoreRDD: RDD[(String, Int)] = sc.parallelize(scoreList, 2)
println("【scoreRDD.partitions.size】:" + scoreRDD.partitions.size)
//分区数,【scoreRDD.partitions.size】:2
println("【scoreRDD.glom.collect】:" + scoreRDD.glom().collect().mkString(",")) //每个分区的内容 //使用combineByKey,按每个学生累积分数和科目数量
val rddCombineByKey: RDD[(String, (Int, Int))] = scoreRDD.combineByKey(v => (v, 1),
(param1: (Int, Int), v) => (param1._1 + v, param1._2 + 1),
(p1: (Int, Int), p2: (Int, Int)) => (p1._1 + p2._1, p1._2 + p2._2))
println("【combineByKey】:" + rddCombineByKey.collect().mkString(","))
//【combineByKey】:(ww2,(377,4)),(ww1,(183,2)) //在map中使用case是scala的用法,按每个学生总成绩/科目数量,得到平均分
val avgScore = rddCombineByKey.map { case (key, value) => (key, value._1 / value._2.toDouble) }
println("【avgScore】:" + avgScore.collect().mkString(","))
//【avgScore】:(ww2,94.25),(ww1,91.5)
说明:
1.首先:各个分区createCombiner 和 mergeValue先干活
第一个分区遍历开始: 数据为
Array(("ww1", 88), ("ww1", 95), ("ww2", 91))
--> 处理(ww1,88), 因为是第一次遇到键“ww1”, 所以调用createCombiner方法 (v)=> (v,1) , 这里就是(ww1,88) =>( ww1, (88,1))
--> 处理(ww1,95),不是第一次遇到键“ww1”,所以会调用mergeValue方法(param1:(Int,Int),v)=>(param1._1+v,param1._2+1),这里就是(ww1,(88,1)),(ww1,95)=>(ww1,(88+95, 1+1))= (ww1,(183,2)) ---(成绩相加,科目数量+1)
--> 处理(ww2,91),因为是第一次遇到键“ww2”, 所以调用createCombiner方法 (v)=> (v,1) ,这里就是(ww2,91) => (ww2, (91,1))
第一个分区遍历结束:返回 (ww1,(183,2) ), ( ww2,(91,1))
第二个分区遍历开始: 数据为
Array(("ww2", 93), ("ww2", 95), ("ww2", 98))
--> 处理(ww2,93), 因为是第一次遇到键“ww2”, 所以调用createCombiner方法 (v)=> (v,1) ,这里就是(ww2,93 )=>(ww2, (93,1))
--> 处理(ww2,95),不是第一次遇到键“ww2”,所以会调用mergeValue方法(param1:(Int,Int),v)=>(param1._1+v,param1._2+1),这里就是(ww2,(93,1)),(ww2,95)=>(ww2,(93+95, 1+1))= (ww2,(188,2)) ---(成绩相加,科目数量+1)
--> 处理(ww2,98),不是第一次遇到键“ww2”,所以会调用mergeValue方法(param1:(Int,Int),v)=>(param1._1+v,param1._2+1),这里就是(ww2,(188,2)),(ww2,98)=>(ww2,(188+98, 2+1))= (ww2,(286,3) ) ---(成绩相加,科目数量+1)
第二个分区遍历结束:返回 (ww2,(286,3) )
2.然后:各个分区干完了, mergeCombiners方法汇总处理
--> 处理分区1的ww1,(183,2) ww2,(91,1) ,分区2的ww2,(286,3) , 会调用mergeCombiners方法(p1: (Int, Int), p2: (Int, Int)) => (p1._1 + p2._1, p1._2 + p2._2)),这里就是
( (ww1,(183,2)),(ww2,(91,1)) , (ww2,(286,3)) )=> ( (ww1,(183,2)) , (ww2,(91+286,1+3)) ) = ( (ww1,(183,2)) , (ww2,(377,4)) )
【Spark算子】:reduceByKey、groupByKey和combineByKey的更多相关文章
- Spark算子--reduceByKey
reduceByKey--Transformation类算子 代码示例 result
- (转)Spark 算子系列文章
http://lxw1234.com/archives/2015/07/363.htm Spark算子:RDD基本转换操作(1)–map.flagMap.distinct Spark算子:RDD创建操 ...
- Spark算子总结及案例
spark算子大致上可分三大类算子: 1.Value数据类型的Transformation算子,这种变换不触发提交作业,针对处理的数据项是Value型的数据. 2.Key-Value数据类型的Tran ...
- Spark算子总结(带案例)
Spark算子总结(带案例) spark算子大致上可分三大类算子: 1.Value数据类型的Transformation算子,这种变换不触发提交作业,针对处理的数据项是Value型的数据. 2.Key ...
- Spark算子使用
一.spark的算子分类 转换算子和行动算子 转换算子:在使用的时候,spark是不会真正执行,直到需要行动算子之后才会执行.在spark中每一个算子在计算之后就会产生一个新的RDD. 二.在编写sp ...
- Spark:常用transformation及action,spark算子详解
常用transformation及action介绍,spark算子详解 一.常用transformation介绍 1.1 transformation操作实例 二.常用action介绍 2.1 act ...
- UserView--第二种方式(避免第一种方式Set饱和),基于Spark算子的java代码实现
UserView--第二种方式(避免第一种方式Set饱和),基于Spark算子的java代码实现 测试数据 java代码 package com.hzf.spark.study; import ...
- UserView--第一种方式set去重,基于Spark算子的java代码实现
UserView--第一种方式set去重,基于Spark算子的java代码实现 测试数据 java代码 package com.hzf.spark.study; import java.util.Ha ...
- spark算子之DataFrame和DataSet
前言 传统的RDD相对于mapreduce和storm提供了丰富强大的算子.在spark慢慢步入DataFrame到DataSet的今天,在算子的类型基本不变的情况下,这两个数据集提供了更为强大的的功 ...
随机推荐
- c#泛型与其他语言的对比(深入理解c#)
1.同c++模板的对比: c++模板有点像是发展到极致的宏.他们非常强大,但代价就是代码膨胀和不易理解. 在c++中使用一个模板时,会为那一套特定的模板实参编译代码,好在模板实参本来就在源代码中一样. ...
- log4j介绍和使用
1.apache推出的开源免费日志处理的类库 2.为什么需要日志?? 2.1 在项目中编写system.out.println();输出到控制台,当项目发布到tomcat后,没有控制台(在命令界面能看 ...
- idea创建spring boot+mybatis(oracle)+themeleaf项目
1.新建项目 选择idea已经有的spring initializr next,然后填写项目命名,包名 然后next,选择所需要的依赖 然后一路next,finish,项目新建成功,然后可以删除下面的 ...
- excelToWord-vba
Sub ExcelToWord() ' 利用Word程序创建文本文件,运行时word不能为打开状态 Dim WordApp As Object '搜索Dim Records As Integer, i ...
- hadoop yarn组件介绍
Yarn的产生 mapReduc1.0 1单点故障 2扩展效率低 3资源利用率高 降低运维成本 方便数据共享 多计算框架支持 MapReduce Spark Storm Yarn的架构图 Yarn模块 ...
- android:padding和android:margin的区别[转]
本文综合了:http://zhujiao.iteye.com/blog/1856980 和 http://blog.csdn.net/maikol/article/details/6048647 两篇 ...
- (转)VmWare下安装CentOS6图文安装教程
转自:http://www.cnblogs.com/seesea125/archive/2012/02/25/2368255.html 第一次使用VmWare和CentOS6,中间遇到不少问题,记性不 ...
- 23种设计模式(1)-Facade设计模式
前记 曾经我遇见的一个需求是这样的,接口A有个方法void methodA(),类B需要实现接口A的methodA()方法,并且在类B中需要把methodA()方法内部处理逻辑获得的结果利用C类实例的 ...
- 如何更好地使用Java 8的Optional
Java 8中的Optional<T> 是一个可以包含或不可以包含非空值的容器对象,在 Stream API中很多地方也都使用到了Optional. java中非常讨厌的一点就是nullp ...
- 最长上升子序列 and 最长公共子序列 问题模板
两种求最长上升子序列问题 第一种:定义dp[i]=以a[i]为末尾的最长上升子序列问题的长度 第二种:定义dp[i]=长度为i+1的上升 子序列 中末尾元素的最小值 #include <cstd ...