【Spark算子】:reduceByKey、groupByKey和combineByKey
在spark中,reduceByKey、groupByKey和combineByKey这三种算子用的较多,结合使用过程中的体会简单总结:
我的代码实践:https://github.com/wwcom614/Spark
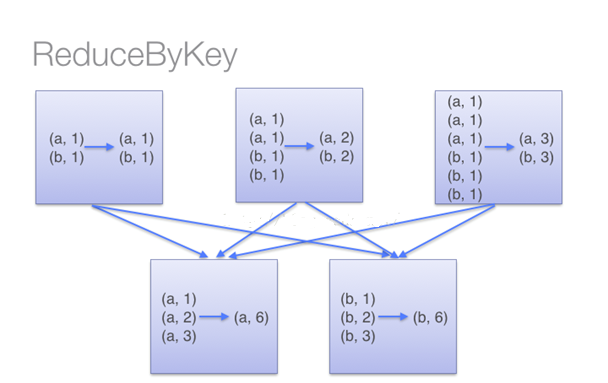
•reduceByKey
用于对每个key对应的多个value进行merge操作,最重要的是它能够在本地先进行merge操作,并且merge操作可以通过函数自定义;
•groupByKey
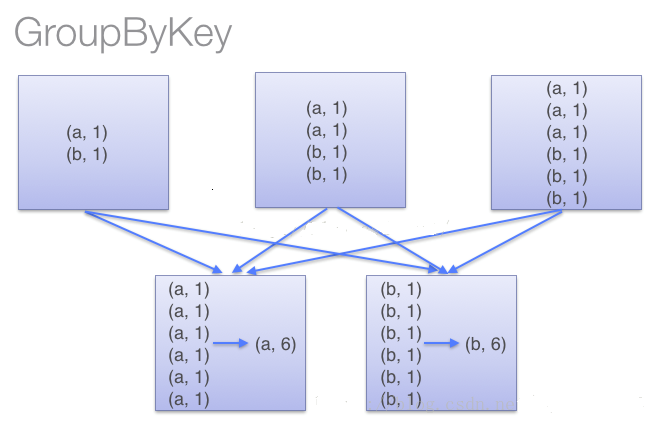
也是对每个key进行操作,但只生成一个sequence,groupByKey本身不能自定义函数,需要先用groupByKey生成RDD,然后才能对此RDD通过map进行自定义函数操作。
使用groupByKey时,spark会将所有的键值对进行移动,不会进行局部merge,会导致集群节点之间的开销很大,导致传输延时。
•combineByKey
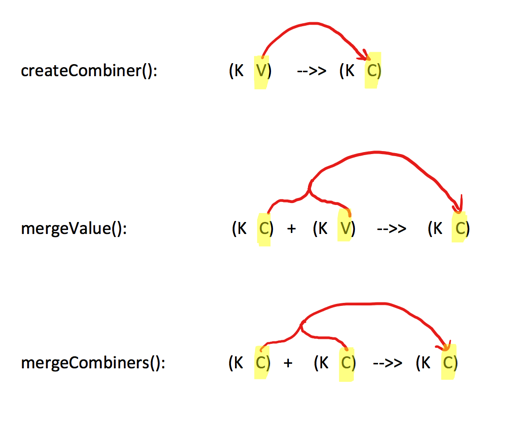
一个相对底层的基于键进行聚合的基础方法(因为大多数基于键聚合的方法,例如reduceByKey,groupByKey都是用它实现的),所以感觉这个方法还是挺重要的。
该方法的入参主要为前三个:
- createCombiner:遍历一个分区中每个元素,如果不存在,createCombiner创建累加器C,把原变量V放入,对相同K,把V合并成一个集合,例如将(key,88),映射建立集合(key,(88,1))
- mergeValue:遍历一个分区中每个元素,如果已存在,将相同的值累加,例如将(key,(88,1)),(key,(88,1)),mergeValue累加集合为(key,(88,2))
- mergeCombiners:createCombiner 和 mergeValue 是处理单个分区中数据, mergeCombiners是每个分区处理完了,多个分区合并数据使用,例如分区1累加集合值为(key,(88,2)),分区2累加集合值为(key,(88,3)),mergeCombiners累加集合为(key,(88,5))
写个求每个学生的平均成绩的例子
//2个学生及他们的成绩
val scoreList = Array(("ww1", 88), ("ww1", 95), ("ww2", 91), ("ww2", 93), ("ww2", 95), ("ww2", 98)) //将2个学生成绩转为RDD,分2个partition存储
val scoreRDD: RDD[(String, Int)] = sc.parallelize(scoreList, 2)
println("【scoreRDD.partitions.size】:" + scoreRDD.partitions.size)
//分区数,【scoreRDD.partitions.size】:2
println("【scoreRDD.glom.collect】:" + scoreRDD.glom().collect().mkString(",")) //每个分区的内容 //使用combineByKey,按每个学生累积分数和科目数量
val rddCombineByKey: RDD[(String, (Int, Int))] = scoreRDD.combineByKey(v => (v, 1),
(param1: (Int, Int), v) => (param1._1 + v, param1._2 + 1),
(p1: (Int, Int), p2: (Int, Int)) => (p1._1 + p2._1, p1._2 + p2._2))
println("【combineByKey】:" + rddCombineByKey.collect().mkString(","))
//【combineByKey】:(ww2,(377,4)),(ww1,(183,2)) //在map中使用case是scala的用法,按每个学生总成绩/科目数量,得到平均分
val avgScore = rddCombineByKey.map { case (key, value) => (key, value._1 / value._2.toDouble) }
println("【avgScore】:" + avgScore.collect().mkString(","))
//【avgScore】:(ww2,94.25),(ww1,91.5)
说明:
1.首先:各个分区createCombiner 和 mergeValue先干活
第一个分区遍历开始: 数据为
Array(("ww1", 88), ("ww1", 95), ("ww2", 91))
--> 处理(ww1,88), 因为是第一次遇到键“ww1”, 所以调用createCombiner方法 (v)=> (v,1) , 这里就是(ww1,88) =>( ww1, (88,1))
--> 处理(ww1,95),不是第一次遇到键“ww1”,所以会调用mergeValue方法(param1:(Int,Int),v)=>(param1._1+v,param1._2+1),这里就是(ww1,(88,1)),(ww1,95)=>(ww1,(88+95, 1+1))= (ww1,(183,2)) ---(成绩相加,科目数量+1)
--> 处理(ww2,91),因为是第一次遇到键“ww2”, 所以调用createCombiner方法 (v)=> (v,1) ,这里就是(ww2,91) => (ww2, (91,1))
第一个分区遍历结束:返回 (ww1,(183,2) ), ( ww2,(91,1))
第二个分区遍历开始: 数据为
Array(("ww2", 93), ("ww2", 95), ("ww2", 98))
--> 处理(ww2,93), 因为是第一次遇到键“ww2”, 所以调用createCombiner方法 (v)=> (v,1) ,这里就是(ww2,93 )=>(ww2, (93,1))
--> 处理(ww2,95),不是第一次遇到键“ww2”,所以会调用mergeValue方法(param1:(Int,Int),v)=>(param1._1+v,param1._2+1),这里就是(ww2,(93,1)),(ww2,95)=>(ww2,(93+95, 1+1))= (ww2,(188,2)) ---(成绩相加,科目数量+1)
--> 处理(ww2,98),不是第一次遇到键“ww2”,所以会调用mergeValue方法(param1:(Int,Int),v)=>(param1._1+v,param1._2+1),这里就是(ww2,(188,2)),(ww2,98)=>(ww2,(188+98, 2+1))= (ww2,(286,3) ) ---(成绩相加,科目数量+1)
第二个分区遍历结束:返回 (ww2,(286,3) )
2.然后:各个分区干完了, mergeCombiners方法汇总处理
--> 处理分区1的ww1,(183,2) ww2,(91,1) ,分区2的ww2,(286,3) , 会调用mergeCombiners方法(p1: (Int, Int), p2: (Int, Int)) => (p1._1 + p2._1, p1._2 + p2._2)),这里就是
( (ww1,(183,2)),(ww2,(91,1)) , (ww2,(286,3)) )=> ( (ww1,(183,2)) , (ww2,(91+286,1+3)) ) = ( (ww1,(183,2)) , (ww2,(377,4)) )
【Spark算子】:reduceByKey、groupByKey和combineByKey的更多相关文章
- Spark算子--reduceByKey
reduceByKey--Transformation类算子 代码示例 result
- (转)Spark 算子系列文章
http://lxw1234.com/archives/2015/07/363.htm Spark算子:RDD基本转换操作(1)–map.flagMap.distinct Spark算子:RDD创建操 ...
- Spark算子总结及案例
spark算子大致上可分三大类算子: 1.Value数据类型的Transformation算子,这种变换不触发提交作业,针对处理的数据项是Value型的数据. 2.Key-Value数据类型的Tran ...
- Spark算子总结(带案例)
Spark算子总结(带案例) spark算子大致上可分三大类算子: 1.Value数据类型的Transformation算子,这种变换不触发提交作业,针对处理的数据项是Value型的数据. 2.Key ...
- Spark算子使用
一.spark的算子分类 转换算子和行动算子 转换算子:在使用的时候,spark是不会真正执行,直到需要行动算子之后才会执行.在spark中每一个算子在计算之后就会产生一个新的RDD. 二.在编写sp ...
- Spark:常用transformation及action,spark算子详解
常用transformation及action介绍,spark算子详解 一.常用transformation介绍 1.1 transformation操作实例 二.常用action介绍 2.1 act ...
- UserView--第二种方式(避免第一种方式Set饱和),基于Spark算子的java代码实现
UserView--第二种方式(避免第一种方式Set饱和),基于Spark算子的java代码实现 测试数据 java代码 package com.hzf.spark.study; import ...
- UserView--第一种方式set去重,基于Spark算子的java代码实现
UserView--第一种方式set去重,基于Spark算子的java代码实现 测试数据 java代码 package com.hzf.spark.study; import java.util.Ha ...
- spark算子之DataFrame和DataSet
前言 传统的RDD相对于mapreduce和storm提供了丰富强大的算子.在spark慢慢步入DataFrame到DataSet的今天,在算子的类型基本不变的情况下,这两个数据集提供了更为强大的的功 ...
随机推荐
- 异常处理(异常解析器) 和 对于Properties类型的属性的配置
在程序运行中,有可能因为用户的不当操作,发生异常.. 在springmvc中可以根据不同的异常配置不同的处理方式 1.例如出现 这个类型异常 org.springframework.web.multi ...
- 使用Hadoop API 压缩HDFS文件
下篇解压缩:使用Hadoop API 解压缩 HDFS文件 起因: 集群磁盘剩余空间不足. 删除了存储在HDFS上的,一定时间之前的中间结果,发现并不能释放太多空间,查看计算业务,发现,每天的日志存在 ...
- 2019.01.23 hdu1964 Pipes(轮廓线dp)
传送门 题意简述:给一个没有障碍的网格图,任意两个格子连通需要花费一定代价,现在求一条覆盖所有格子的哈密顿回路的总权值的最小值. 思路: 跟这道题一毛一样,除了把求和变成求最小值以外. 代码: #in ...
- vue 开发系列(八) 动态表单开发
概要 动态表单指的是我们的表单不是通过vue 组件一个个编写的,我们的表单是根据后端生成的vue模板,在前端通过vue构建出来的.主要的思路是,在后端生成vue的模板,前端通过ajax的方式加载后端的 ...
- boost--asio
1.asio综述 asio的核心类是io_service,它相当于前摄器模式的Proactor角色,在异步模式下发起的I/O操作,需要定义一个用于回调的完成处理函数,当I/O完成时io_service ...
- CString int转换
1.CString 转 int CString strtemp = "100"; int intResult; intResult= atoi(strtem ...
- SSH三大框架的工作原理
Hibernate工作原理 原理:1.通过Configuration().configure();读取并解析hibernate.cfg.xml配置文件2.由hibernate.cfg.xml中的< ...
- 3-具体学习git--reset回到过去的版本(commit间穿梭),checkout单个文件穿梭
git log --oneline 命令可以在一块儿显示做过的改动. 我在change 2时忘了一条,想在change 1后再添加一个语句或一个操作,然后这个状态再提交仍作为change 2.将这个s ...
- mysql学习之路_基础知识
Mysql php阶段将数据库分为三个阶 基础阶段: mysql数据库的基本操作(增删改查),以及一些高级操作(视图,触发器,函数,存储过程等),PHP操作没有sql数 ...
- i2c_client的生成
网上很多文档都是介绍源码,包括i2c_client结构体的源码都有贴出,看上去似乎需要手动写该结构体,但实际上,i2c_client的生成是用如下方法. \arch\arm\mach-omap2/bo ...