kafka配置监控和消费者测试
####分区partition
一定条件下,分区数越多,吞吐量越高。分区也是保证消息被顺序消费的基础,kafka只能保证一个分区内消息的有序性
####副本
每个分区有一至多个副本(Replica),分区的副本分布在集群的不同代理上,提高可用性。分区的每个副本在存储上对应与日志对象log对应
####AR
每个分区的多个部分之间称为AR(assigned replicas),包含至多一份leader副本和多个follower副本
###ISR
kafka在zookeeper中动态维护了一个ISR(In-sync Replica),即保存同步的副本列表。列表中保存的是与leader副本保持消息同步的所有副本对应的代理节点id
####优先副本
AR列表中的第一个副本。理想情况下,优先副本是该分区的leader副本。所有的读写请求都有分区leader副本处理,kafka要保证优先副本在集群中均匀分布,保证了所有分区leader均匀分布,
####代理
每一个kafka实例称为代理(broker),每个代理都有唯一标示id即broker id,一台服务器上可以配置一个或多个代理
####kafka streams
java语言实现的用于流处理的jar文件
####controller_epoch
控制器轮值次数,每选出一个新的控制器,+1,对应zookeeper的controller_epoch字段
选举策略是在zk的controller/路径下创建临时节点
####zkVersion
类似于数据库乐观锁,用于更新zk下相应元数据信息
####leader_epoch
分区leader更新次数
####配置文件
```bash
[root@sjck-node03 config]# cd /usr/local/kafka/config
[root@sjck-node03 config]# cp server.properties server.properties.bak
[root@sjck-node03 config]# cp server.properties server-1.properties
[root@sjck-node03 config]# cp server.properties server-2.properties
```
修改不同的配置文件,每个对应的broker.id不一样,012,类似zk里的myid,port是监听的端口
broker.id=0
listeners=PLAINTEXT://sjck-node03:9092
log.dirs=/home/soft/kafka/logs/broker-0
zookeeper.connect=sjck-node03:2181,sjck-node03:2182,sjck-node03:2183
broker.id=1
listeners=PLAINTEXT://sjck-node03:9093
log.dirs=/home/soft/kafka/logs/broker-1
zookeeper.connect=sjck-node03:2181,sjck-node03:2182,sjck-node03:2183
broker.id=2
listeners=PLAINTEXT://sjck-node03:9094
log.dirs=/home/soft/kafka/logs/broker-2
zookeeper.connect=sjck-node03:2181,sjck-node03:2182,sjck-node03:2183
配置kafka环境变量
vim /etc/profile
#KAFKA_HOME
export KAFKA_HOME=/usr/local/kafka
export PATH=$PATH:$KAFKA_HOME/bin
source /etc/profile
####先启动zookeeper,再启动kafka,启动脚本,daemon参数是后台守护进程
```
#!/bin/bash
brokers=(server server-1 server-2)
for broker in ${brokers[@]}
do
echo $broker
${KAFKA_HOME}/bin/kafka-server-start.sh -daemon ${KAFKA_HOME}/config/${broker}.properties
done
```
关闭脚本
#!/bin/bash
SIGNAL=${SIGNAL:-TERM}
for element in `jps -l|grep kafka|awk '{print $1}'`
do
echo $element
kill -s $SIGNAL $element
done
查看启动状态
[root@sjck-node03 ~]# jps -l
3299 org.apache.zookeeper.server.quorum.QuorumPeerMain
6148 kafka.Kafka
3258 org.apache.zookeeper.server.quorum.QuorumPeerMain
5787 kafka.Kafka
6524 sun.tools.jps.Jps
6494 kafka.Kafka
3231 org.apache.zookeeper.server.quorum.QuorumPeerMain
连接zkclient,查看节点注册情况
[root@sjck-node03 bin]# ./zkCli.sh -server localhost:2181
[zk: localhost:2181(CONNECTED) 0] ls /brokers/ids
[0, 1, 2]
[zk: localhost:2181(CONNECTED) 1] get /controller
{"version":1,"brokerid":0,"timestamp":"1552626305509"}
cZxid = 0x140000002c
ctime = Fri Mar 15 13:05:05 CST 2019
mZxid = 0x140000002c
mtime = Fri Mar 15 13:05:05 CST 2019
pZxid = 0x140000002c
cversion = 0
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x2000001158f0000
dataLength = 54
numChildren = 0
####创建主题,包含2个副本,3个分区
```
[root@sjck-node03 kafka]# kafka-topics.sh --create --zookeeper sjck-node03:2181,sjck-node03:2182,sjck-node03:2183 --replication-factor 2 --partitions 3 --topic kafka-action
Created topic "kafka-action".
```
登录zk查看创建主题对应的分区
[zk: localhost:2181(CONNECTED) 1] ls /brokers/topics/kafka-action/partitions
[0, 1, 2]
[zk: localhost:2181(CONNECTED) 2] get /brokers/topics/kafka-action
{"version":1,"partitions":{"2":[1,2],"1":[0,1],"0":[2,0]}}
删除topic,当配置文件里的delete.topic.enable=true,真正执行删除操作,zk中的节点和log中的分区文件被真正删除
kafka-topics.sh --delete --zookeeper sjck-node03:2181,sjck-node03:2182,sjck-node03:2183 --topic kafka-action
Topic kafka-action is marked for deletion.
Note: This will have no impact if delete.topic.enable is not set to true.
查看分区优先副本数
kafka-topics.sh --zookeeper sjck-node03:2181,sjck-node03:2182,sjck-node03:2183 --describe --topic kafka-action
Topic:kafka-action PartitionCount:3 ReplicationFactor:2 Configs:
Topic: kafka-action Partition: 0 Leader: 2 Replicas: 2,0 Isr: 2,0
Topic: kafka-action Partition: 1 Leader: 0 Replicas: 0,1 Isr: 0,1
Topic: kafka-action Partition: 2 Leader: 1 Replicas: 1,2 Isr: 1,2
生产者消费者测试,单播和多播,
注意broker-list的域名,要和server.properties里listeners的域名写的一样,127.0.0.1和localhost也会出错,没有解析对应上
1个生产者
kafka-console-producer.sh --broker-list sjck-node03:9092,sjck-node03:9093,sjck-node03:9094 --topic kafka-action
2个消费者
kafka-console-consumer.sh --bootstrap-server sjck-node03:9092,sjck-node03:9093,sjck-node03:9094 --topic kafka-action --consumer-property group.id=single-consumer-group
一条消息只能被同一个消费组的一个消费者消费
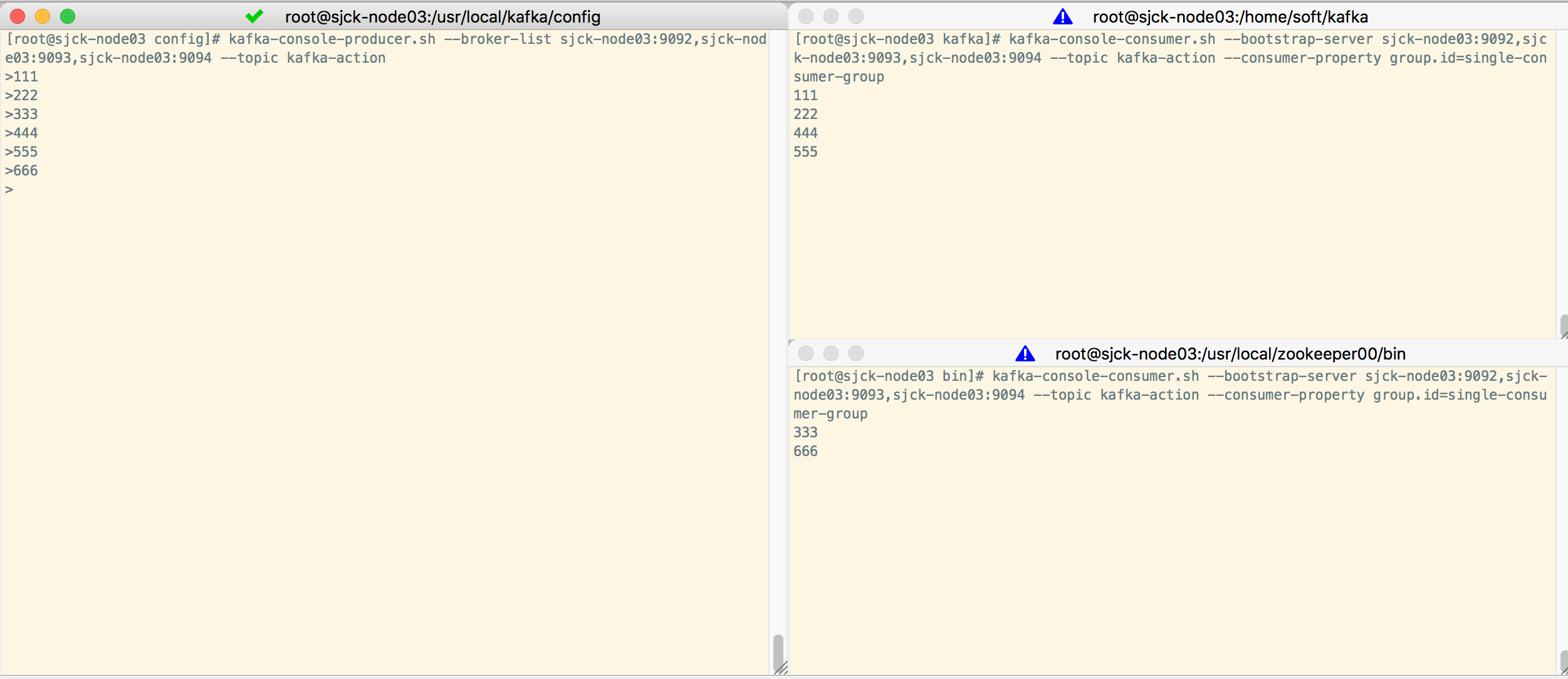
多播
再创建一个属于不同组的消费者
kafka-console-consumer.sh --bootstrap-server sjck-node03:9092,sjck-node03:9093,sjck-node03:9094 --topic kafka-action --consumer-property group.id=multi-consumer-group
一条消息能被不同消费组的消费者消费

流处理器
sink处理器,从上游处理器接受到的数据发送到指定topic中
source处理器,把topic消费数据当做输入流,发送到下游处理器
处理器拓扑(processor topgyolo)
流处理程序进行数据处理的计算逻辑,是流处理器和和相连接的流组成的有向无环图,其中流处理器是节点,流是边
kafka配置监控和消费者测试的更多相关文章
- centos7单机安装kafka,进行生产者消费者测试
[转载请注明]: 原文出处:https://www.cnblogs.com/jstarseven/p/11364852.html 作者:jstarseven 码字挺辛苦的..... 一.k ...
- Kafka入门之生产者消费者测试
目录: kafka启动脚本以及关闭脚本 1. 同一个生产者同一个Topic,两个相同的消费者相同的Group 2. 同一个生产者同一个Topic,两个消费者不同Group 3. 两个生产者同一个Top ...
- kafka消息监控-KafkaOffsetMonitor
参照site:https://github.com/quantifind/KafkaOffsetMonitor 一.简述 这个应用程序用来实时监控Kafka服务的Consumer以及它们所在的Part ...
- Kafka记录-Kafka简介与单机部署测试
1.Kafka简介 kafka-分布式发布-订阅消息系统,开发语言-Scala,协议-仿AMQP,不支持事务,支持集群,支持负载均衡,支持zk动态扩容 2.Kafka的架构组件 1.话题(Topic) ...
- kafka性能参数和压力测试揭秘
转自:http://blog.csdn.net/stark_summer/article/details/50203133 上一篇文章介绍了Kafka在设计上是如何来保证高时效.大吞吐量的,主要的内容 ...
- kafka环境搭建及librdkafka测试
kafka环境搭建及librdkafka测试 (2016-04-05 10:18:25) 一.kafka环境搭建(转自http://kafka.apache.org/documentation.h ...
- Kafka 消息监控 - Kafka Eagle
1.概述 在开发工作当中,消费 Kafka 集群中的消息时,数据的变动是我们所关心的,当业务并不复杂的前提下,我们可以使用 Kafka 提供的命令工具,配合 Zookeeper 客户端工具,可以很方便 ...
- hadoop生态搭建(3节点)-08.kafka配置
如果之前没有安装jdk和zookeeper,安装了的请直接跳过 # https://www.oracle.com/technetwork/java/javase/downloads/java-arch ...
- Kafka入门之生产者消费者
一.Kafka安装与使用 ( kafka介绍 ) 1. 下载Kafka 官网 http://kafka.apache.org/ 以及各个版本的下载地址 http://archive.ap ...
随机推荐
- POJ 1062 昂贵的聘礼(图论,最短路径)
POJ 1062 昂贵的聘礼(图论,最短路径) Description 年轻的探险家来到了一个印第安部落里.在那里他和酋长的女儿相爱了,于是便向酋长去求亲.酋长要他用10000个金币作为聘礼才答应把女 ...
- (转)面向对象——UML类图设计
背景:一直以来,对UMl类图的画法不甚理解,但是随着学习的深入,发现熟练掌握UML类图,能够更好理解代码间的逻辑性,而这也是程序设计的基础所在,所以很有必要把UML好好掌握. UML类图新手入门级介绍 ...
- Python之旅:并发编程之协程
一 引子 本节的主题是基于单线程来实现并发,即只用一个主线程(很明显可利用的cpu只有一个)情况下实现并发,为此我们需要先回顾下并发的本质:切换+保存状态 cpu正在运行一个任务,会在两种情况下切走去 ...
- maven pom 中的 build——resources 标签 mybatis加载mapper类及.xml文件
转: maven 理解 2017年12月18日 15:34:31 feicongcong 阅读数:5658 版权声明:本文为博主原创文章,未经博主允许不得转载. https://blog.csdn ...
- Hadoop生态圈-Azkaban实战之Command类型多job工作流flow
Hadoop生态圈-Azkaban实战之Command类型多job工作流flow 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. Azkaban内置的任务类型支持command.ja ...
- IDEA启动Tomcat报错1099 is already in use
IDEA中启动Tomcat报错,Error running Tomcat7.0.52: Address localhost:1099 is already in use 或者是 java.rmi.se ...
- Codeforces 906 D. Power Tower
http://codeforces.com/contest/906/problem/D 欧拉降幂 #include<cstdio> #include<iostream> usi ...
- .NET面试题系列(九)C# 结构体与类的区别
谈一下什么时候使用结构,什么使用类. 我们知道,结构存储在栈中,而栈有1个特点,就是空间较小,但是访问速度较快,堆空间较大,但是访问速度相对较慢.所以当我们描述1个轻量级对象的时候,可以将其定义为结构 ...
- 【NOI】2017 整数(BZOJ 4942,LOJ2302) 压位+线段树
[题目]#2302. 「NOI2017」整数 [题意]有一个整数x,一开始为0.n次操作,加上a*2^b,或询问2^k位是0或1.\(n \leq 10^6,|a| \leq 10^9,0 \leq ...
- ListView position
在使用listview的时候,我们经常会在listview的监听事件中,例如OnItemClickListener(onItemClick)中,或listview的adapter中(getView.g ...