openstack(pike 版)集群部署(一)----基础环境部署
一、环境
1、系统:
a、CentOS Linux release 7.4.1708 (Core)
b、更新yum源和安装常用软件
# yum -y install epel-release bash-completion.noarch bash-completion-extras.noarch vim net-tools
2、节点:6台


3、配置时间同步 (chrony)
博客:http://www.cnblogs.com/weijie0717/p/8549204.html
4、关闭 firewalld 和 Selinux
5、安装 openstack 源(所有节点)
# yum install centos-release-openstack-pike
6、安装 openstack-client(controller 节点)
# yum install python-openstackclient
7、更新系统,并重启(所有节点)
# yum upgrade
# init 6
二、ceph 集群部署
博客:ceph 集群安装
三、数据库集群部署 (controller 节点)
1、博客:Mysql 5.7 Galera cluster 部署
或 Centos 7 MariaDB Galera cluster 部署
安装python mysql 插件
# yum -y install python2-PyMySQL.noarch
2、配置文件添加修改如下配置:
# vim /etc/my.cnf
[mysqld]
bind-address = 10.6.32.x (各节点网卡IP) default-storage-engine = innodb
innodb_file_per_table = on
max_connections =
collation-server = utf8_general_ci
character-set-server = utf8
3、重启服务(因为是集群,服务逐一重启)
# systemctl restart mysql.service
四、集群高可用部署 (controller 节点)
博客:Corosync + Pacemaker + psc + HA-proxy 实现业务高可用
博客:Openstack 集群,及常用服务的 高可用 haproxy配置
部署 mysql + Haproxy,并逐台切换Haproxy的节点测试,保证mysql-VIP 负载可用。
五、Message queue 安装 (controller 节点)
博客:Centos 7 RabbitMQ + Haproxy 集群高可用部署
六、Memcached 安装 (controller 节点)
1、安装包
# yum install memcached python-memcached
2、修改配置
# vim /etc/sysconfig/memcached
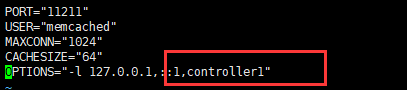
3、重启服务,并设置开机自启动
# systemctl enable memcached.service
# systemctl start memcached.service
七、Etcd 安装
目前Etcd 尚未搭建成功,前期openstack 可以不做配置,后期补充。
基础环境部署完毕。
openstack(pike 版)集群部署(一)----基础环境部署的更多相关文章
- Hadoop1.X集群完全分布式模式环境部署
Hadoop1.X集群完全分布式模式环境部署 1 Hadoop简介 Hadoop是Apache软件基金会旗下的一个开源分布式计算平台.以Hadoop分布式文件系统(HDFS,Hadoop Distri ...
- (二 )VMware workstation 部署虚拟集群实践——并行批量操作环境部署
在上一篇博客中,已经介绍了安装虚拟集群的过程和需要注意的细节问题. 这篇主要是介绍如何批量登陆远程主机和配置,这个过程中是在没有部署并行处理工具或者集群管理工具的前进行的. ------------首 ...
- Jenkins+maven+gitlab自动化部署之基础环境部署(一)
从一个二线城市,来到上海,刚入职,老大就给任务,为了减少开发打包部署时间,需要搭建一套自动化部署环境.接到任务后,赶紧上网查找资料,以及了解jenkins作用等等,用了一周时间,了解了个大概,由于都是 ...
- Oracle RAC集群搭建(二)-基础环境配置
01,创建用户,用户组 [root@rac1 ~]# groupadd -g 501 oinstall [root@rac1 ~]# groupadd -g 502 dba [root@rac1 ~] ...
- CentOS7.2非HA分布式部署Openstack Pike版 (实验)
部署环境 一.组网拓扑 二.设备配置 笔记本:联想L440处理器:i3-4000M 2.40GHz内存:12G虚拟机软件:VMware® Workstation 12 Pro(12.5.2 build ...
- OpenStack实践系列①openstack简介及基础环境部署
OpenStack实践系列①openstack简介及基础环境部署 一.OpenStack初探1.1 OpenStack简介 OpenStack是一整套开源软件项目的综合,它允许企业或服务提供者建立.运 ...
- 主从集群搭建及容灾部署redis
redis主从集群搭建及容灾部署(哨兵sentinel) Redis也用了一段时间了,记录一下相关集群搭建及配置详解,方便后续使用查阅. 提纲 l Redis安装 l 整体架构 l Redis主 ...
- VLAN 模式下的 OpenStack 管理 vSphere 集群方案
本文不合适转载,只用于自我学习. 关于为什么要用OpenStack 管理 vSphere 集群,原因可以有很多,特别是一些传统企业,VMware 的使用还是很普遍的,用 OpenStack 纳管至少会 ...
- 利用ansible来做kubernetes 1.10.3集群高可用的一键部署
请读者务必保持环境一致 安装过程中需要下载所需系统包,请务必使所有节点连上互联网. 本次安装的集群节点信息 实验环境:VMware的虚拟机 IP地址 主机名 CPU 内存 192.168.77.133 ...
随机推荐
- TabNavigator Container Example
<?xml version="1.0" encoding="utf-8"?> <s:Application xmlns:fx="ht ...
- 使用jquery刷新当前页面、刷新父级页面
如何使用jquery刷新当前页面 下面介绍全页面刷新方法:有时候可能会用到 window.location.reload(); //刷新当前页面.(我用的这个一个,非常好) parent.locati ...
- 选择、操作web元素-2
11月3日 等待web元素的出现 例子:百度搜索松勤网,点击操作后不等待页面刷新,下面选择页面元素的时候,该元素还是未出现 sleep方案的弊病:固定的等待时间,导致测试用例执行时间很长 为什么cli ...
- APP-5-百度电子围栏
1.代码部分 <!DOCTYPE html> <html> <head> <meta charset="utf-8"> <me ...
- vue - @click 用到的修饰符
1.vue提供的方法 .stop .prevent .capture .self .once .passive <!-- 阻止单击事件继续传播 --><a v-on:click.st ...
- data型怎么转换格式
data型如何转换格式01-1月 -03 如何转成 YYYY-MM-DD 的格式 本来就是date了 ------解决方案--------------------to_char ...
- linux 覆盖可执行文件的问题
测试环境是3.10.0 内核. 有一次操作中,发现cp -f A B执行的时候,行为不一样: 当B没被打开,则正常覆盖B. 当B是被打开,但没有被执行,则能覆盖, 当B被打开,且被执行,则不能直接覆盖 ...
- 【375】COMP 9021 相关笔记
1. Python 中的逻辑否定用 not 2. 对于下面的代码直邮输入整数才能运行,无论字符串或者浮点型都会报错 int(input('How many games should I simulat ...
- JavaScript 从定义到执行,你应该知道的那些事
JavaScript从定义到执行,JS引擎在实现层做了很多初始化工作,因此在学习JS引擎工作机制之前,我们需要引入几个相关的概念:执行环境栈.执行环境.全局对象.变量对象.活动对象.作用域和作用域链等 ...
- cap文件的格式说明
前面24个字节是.cap文件的文件头. 头信息对应的结构体为:struct pcap_file_header { bpf_u_int32 magic; u_short version_major; ...