stacking算法原理及代码
stacking算法原理
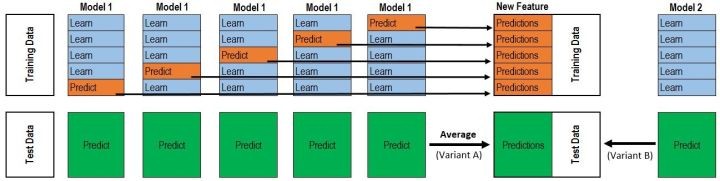
1:对于Model1,将训练集D分为k份,对于每一份,用剩余数据集训练模型,然后预测出这一份的结果
2:重复上面步骤,直到每一份都预测出来。得到次级模型的训练集
3:得到k份测试集,平均后得到次级模型的测试集
4: 对于Model2、Model3…..重复以上情况,得到M维数据
5:选定次级模型,进行训练预测 ,一般这最后一层用的是LR。
优缺点:
优点:
1、 采用交叉验证方法构造,稳健性强;
2、 可以结合多个模型判断结果,进行次级训练,效果好;
缺点:
1、构造复杂,难以得到相应规则,商用上难以解释。
代码:
import numpy as np
from sklearn.model_selection import KFold
def get_stacking(clf, x_train, y_train, x_test, n_folds=10):
"""
这个函数是stacking的核心,使用交叉验证的方法得到次级训练集
x_train, y_train, x_test 的值应该为numpy里面的数组类型 numpy.ndarray .
如果输入为pandas的DataFrame类型则会把报错"""
train_num, test_num = x_train.shape[0], x_test.shape[0]
second_level_train_set = np.zeros((train_num,))
second_level_test_set = np.zeros((test_num,))
test_nfolds_sets = np.zeros((test_num, n_folds))
kf = KFold(n_splits=n_folds)
for i,(train_index, test_index) in enumerate(kf.split(x_train)):
x_tra, y_tra = x_train[train_index], y_train[train_index]
x_tst, y_tst = x_train[test_index], y_train[test_index]
clf.fit(x_tra, y_tra)
second_level_train_set[test_index] = clf.predict(x_tst)
test_nfolds_sets[:,i] = clf.predict(x_test)
second_level_test_set[:] = test_nfolds_sets.mean(axis=1)
return second_level_train_set, second_level_test_set
#我们这里使用5个分类算法,为了体现stacking的思想,就不加参数了
from sklearn.ensemble import (RandomForestClassifier, AdaBoostClassifier,
GradientBoostingClassifier, ExtraTreesClassifier)
from sklearn.svm import SVC
rf_model = RandomForestClassifier()
adb_model = AdaBoostClassifier()
gdbc_model = GradientBoostingClassifier()
et_model = ExtraTreesClassifier()
svc_model = SVC()
#在这里我们使用train_test_split来人为的制造一些数据
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
iris = load_iris()
train_x, test_x, train_y, test_y = train_test_split(iris.data, iris.target, test_size=0.2)
train_sets = []
test_sets = []
for clf in [rf_model, adb_model, gdbc_model, et_model, svc_model]:
train_set, test_set = get_stacking(clf, train_x, train_y, test_x)
train_sets.append(train_set)
test_sets.append(test_set)
meta_train = np.concatenate([result_set.reshape(-1,1) for result_set in train_sets], axis=1)
meta_test = np.concatenate([y_test_set.reshape(-1,1) for y_test_set in test_sets], axis=1)
#使用决策树作为我们的次级分类器
from sklearn.tree import DecisionTreeClassifier
dt_model = DecisionTreeClassifier()
dt_model.fit(meta_train, train_y)
df_predict = dt_model.predict(meta_test)
print(df_predict)
stacking算法原理及代码的更多相关文章
- AC-BM算法原理与代码实现(模式匹配)
AC-BM算法原理与代码实现(模式匹配) AC-BM算法将待匹配的字符串集合转换为一个类似于Aho-Corasick算法的树状有限状态自动机,但构建时不是基于字符串的后缀而是前缀.匹配 时,采取自后向 ...
- 集成学习值Adaboost算法原理和代码小结(转载)
在集成学习原理小结中,我们讲到了集成学习按照个体学习器之间是否存在依赖关系可以分为两类: 第一个是个体学习器之间存在强依赖关系: 另一类是个体学习器之间不存在强依赖关系. 前者的代表算法就是提升(bo ...
- 【机器学习】Apriori算法——原理及代码实现(Python版)
Apriopri算法 Apriori算法在数据挖掘中应用较为广泛,常用来挖掘属性与结果之间的相关程度.对于这种寻找数据内部关联关系的做法,我们称之为:关联分析或者关联规则学习.而Apriori算法就是 ...
- 排序算法原理及代码实现(c#)
1.插入排序 把第一个元素看做已排序数组放在有序数组中,从第二个元素开始,依次把无序数组元素取出和有序数组中的元素逐个比较,并放在有序数组的正确位置上. /// <summary> /// ...
- 广告系统中weak-and算法原理及编码验证
wand(weak and)算法基本思路 一般搜索的query比较短,但如果query比较长,如是一段文本,需要搜索相似的文本,这时候一般就需要wand算法,该算法在广告系统中有比较成熟的应 该,主要 ...
- 机器学习之决策树一-ID3原理与代码实现
决策树之系列一ID3原理与代码实现 本文系作者原创,转载请注明出处:https://www.cnblogs.com/further-further-further/p/9429257.html 应用实 ...
- Logistic回归分类算法原理分析与代码实现
前言 本文将介绍机器学习分类算法中的Logistic回归分类算法并给出伪代码,Python代码实现. (说明:从本文开始,将接触到最优化算法相关的学习.旨在将这些最优化的算法用于训练出一个非线性的函数 ...
- 第一篇:K-近邻分类算法原理分析与代码实现
前言 本文介绍机器学习分类算法中的K-近邻算法并给出伪代码与Python代码实现. 算法原理 首先获取训练集中与目标对象距离最近的k个对象,然后再获取这k个对象的分类标签,求出其中出现频数最大的标签. ...
- 深入一致性哈希(Consistent Hashing)算法原理,并附100行代码实现
转自:https://my.oschina.net/yaohonv/blog/1610096 本文为实现分布式任务调度系统中用到的一些关键技术点分享——Consistent Hashing算法原理和J ...
随机推荐
- 无oracle客户端仅用plsql连接远程oracle
1.在安装ORACLE服务器的机器上搜索下列文件,oci.dllocijdbc10.dllociw32.dllorannzsbb10.dlloraocci10.dlloraociei10.dllsql ...
- CentOS 6.8 虚拟机安装详解
第一步:安装 VMware 官方网站:www.vmware.com 下载百度云链接:http://pan.baidu.com/s/1bphDOWv 密码:0zix VMware 是一个虚拟 PC 的软 ...
- bat 栈上限
栈耗尽,递归会导致该问题. ****** B A T C H R E C U R S I O N exceeds STACK limits ******Recursion Count=1240, St ...
- test_maven_实现表单验证
这篇文章是我的上一篇文章的续集,如未看过,可看一下,上面的test_maven再继续看这个 这篇文章主要是阐述使用struts实现表单验证的功能. 1.首先了解actionContext:Action ...
- test zhenai
web.Document.InvokeScript("eval",new string[]{"document.getElementById('passwordbt'). ...
- jQuery.bsgrid
http://thebestofyouth.com/bsgrid/ 支持json.xml数据格式,皮肤丰富并且容易定制,支持表格编辑.本地数据.导出参数构建等实用便捷的功能,容易扩展,更拥有丰富的示例 ...
- 20155238 2016-2017-2 《JAVA程序设计》第九周学习总结
教材学习内容总结 第十六章 JDBC SQL的解决方案是JDBC,在Java中,JDBC API主要用来存取数据库. *JDBC API是一个Java API,可以访问任何类型表列数据,特别是存储在关 ...
- 20155306 白皎 0day漏洞——漏洞的复现
一.Ubuntu16.04 (CVE-2017-16995) 1.漏洞概述 Ubuntu最新版本16.04存在本地提权漏洞,该漏洞存在于Linux内核带有的eBPF bpf(2)系统调用中,当用户提供 ...
- flask 与 vue.js 2.0 实现 todo list
实现了后端与前端分离,后端提供 RESTful api. 后端 flask 与前端 vue 的数据传输都是 json. 本文使用 vue.js 2.0 对前一个例子:flask, SQLAlchemy ...
- Yii2中的format
关于format,这个也非常方便, 用来格式化内容的. 如下代码: <?= DetailView::widget([ 'model' => $model, 'attributes' =&g ...