spark使用hadoop native库
默认情况下,hadoop官方发布的二进制包是不包含native库的,native库是用C++实现的,用于进行一些CPU密集型计算,如压缩。比如apache kylin在进行预计算时为了减少预计算的数据占用的磁盘空间,可以配置使用压缩格式。
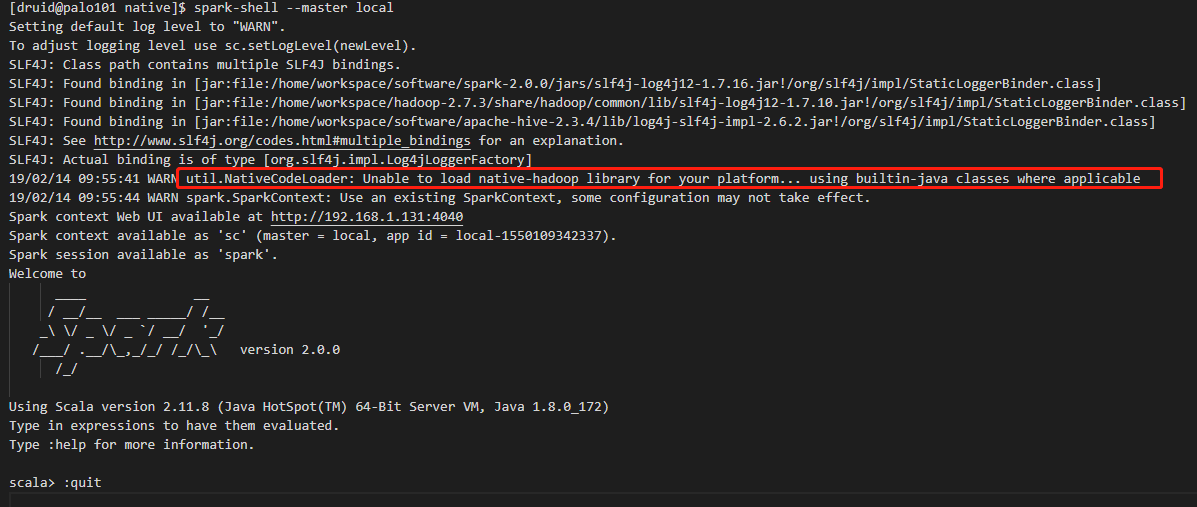
默认情况下,启动spark-shell,会有无法加载native库的警告:
19/02/14 09:55:41 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
1. 编译hadoop源码
具体请参见本人的博文
或者在hadoop源码根目录下,执行ant compile-native 编译本地库(未亲测)
编译好中之后在{hadoop_source_root}/hadoop-dist/target/hadoop-{hadoop_version}/lib/native会存在编译好的native库文件,具体路径,请自己替换为匹配的版本。在本人的机器上显示如下,本人机器上用的是hadoop-2.7.3,所以路径为
{hadoop_source_root}/hadoop-dist/target/hadoop-2.7.3/lib/native
[druid@palo101 native]$ ls -lh
total 4.6M
-rw-rw-r-- druid druid 1.2M Feb : libhadoop.a
-rw-rw-r-- druid druid 1.6M Feb : libhadooppipes.a
lrwxrwxrwx druid druid Feb : libhadoop.so -> libhadoop.so.1.0.
-rwxrwxr-x druid druid 710K Feb : libhadoop.so.1.0.
-rw-rw-r-- druid druid 465K Feb : libhadooputils.a
-rw-rw-r-- druid druid 425K Feb : libhdfs.a
lrwxrwxrwx druid druid Feb : libhdfs.so -> libhdfs.so.0.0.
-rwxrwxr-x druid druid 267K Feb : libhdfs.so.0.0.
2. 部署编译好的hadoop native库
.删除hadoop部署环境下的native库(如果存在的话)
rm -rf $HADOOP_HOME/lib/native
复制编译好的native库到hadoop部署目录
scp -r {hadoop_source_root}/hadoop-dist/target/hadoop-2.7./lib/native {hadoop集群节点IP}:$HADOOP_HOME/lib
注意:复制到集群节点上.
3. 复制libjvm.so文件到$HADOOP_HOME/lib/native目录下
用ldd查看一下生成的native二进制文件的信息,发现libjvm.so找不到
[druid@palo101 native]$ sudo ldd $HADOOP_HOME/lib/native/libhadoop.so
linux-vdso.so. => (0x00007ffe12bad000)
libdl.so. => /lib64/libdl.so. (0x00007fee0127c000)
libjvm.so => not found
libc.so. => /lib64/libc.so. (0x00007fee00eba000)
/lib64/ld-linux-x86-.so. (0x00007fee016ba000)

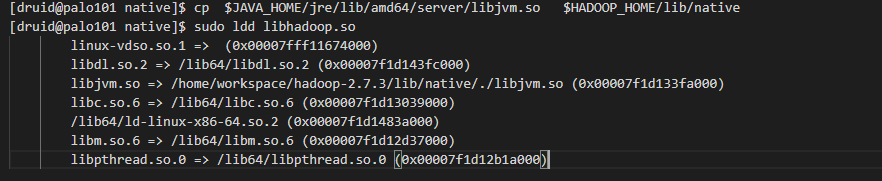
所以我们在每台机器上执行下面脚本,把libjvm.so文件复制到hadoop native lib目录下
cp $JAVA_HOME/jre/lib/amd64/server/libjvm.so $HADOOP_HOME/lib/native
复制过去后,再执行一下下面的命令检查一下二进制native库
sudo ldd $HADOOP_HOME/lib/native/libhadoop.so
一切正常,说明部署已经没有问题了。下面就来做一下配置
4. 配置使用native库
4.1 hadoop启用native库
vim $HADOOP_HOME/etc/hadoop/core-site.xml
添加配置项
<property>
<name>hadoop.native.lib</name>
<value>true</value>
<description>Should native hadoop libraries, if present, be used.</description>
</property>
4.2 添加环境变量
vim /etc/profile
在末尾添加
export LD_LIBRARY_PATH=$HADOOP_HOME/lib/native
也可以在shell窗口中执行这个命令,但是是临时生效,shell窗口关闭就失效了。
5. 在shell中验证是否成功

发现警告已经消失,成功使用了hadoop本地库.
spark使用hadoop native库的更多相关文章
- Hadoop支持的压缩格式对比和应用场景以及Hadoop native库
对于文件的存储.传输.磁盘IO读取等操作在使用Hadoop生态圈的存储系统时是非常常见的,而文件的大小等直接影响了这些操作的速度以及对磁盘空间的消耗. 此时,一种常用的方式就是对文件进行压缩.但文件被 ...
- 更改hadoop native库文件后datanode故障
hadoop是用cloudra的官方yum源安装的,服务器是CentOS6.3 64位操作系统,自己写的mapreduce执行的时候hadoop会提示以下错误: WARN util.NativeCod ...
- 4、解决native库不兼容
解决native库不兼容 现象: 报警告 [root@hadoop1 hadoop-]# bin/hdfs dfs -ls /input // :: WARN util.NativeCodeLoade ...
- 对于spark以及hadoop的几个疑问(转)
Hadoop是啥?spark是啥? spark能完全取代Hadoop吗? Hadoop和Spark属于哪种计算计算模型(实时计算.离线计算)? 学习Hadoop和spark,哪门语言好? 哪里能找到比 ...
- Spark与Hadoop计算模型的比较分析
http://tech.it168.com/a2012/0401/1333/000001333287.shtml 最近很多人都在讨论Spark这个貌似通用的分布式计算模型,国内很多机器学习相关工作者都 ...
- Spark入门(1-1)什么是spark,spark和hadoop
一.Spark是什么? Apache Spark 是专为大规模数据处理而设计的快速通用的计算引擎,可用来构建大型的.低延迟的数据分析应用程序. Spark是UC Berkeley AMP lab (加 ...
- [hadoop] hadoop native libraries 编译
安装hadoop启动之后总有警告:Unable to load native-hadoop library for your platform... using builtin-Javaclasses ...
- Spark和hadoop的关系
1. Spark VSHadoop有哪些异同点? Hadoop:分布式批处理计算,强调批处理,常用于数据挖掘和数据分析. Spark:是一个基于内存计算的开源的集群计算系统,目的是让数据分析更加快速, ...
- Spark和Hadoop作业之间的区别
Spark目前被越来越多的企业使用,和Hadoop一样,Spark也是以作业的形式向集群提交任务,那么在内部实现Spark和Hadoop作业模型都一样吗?答案是不对的. 熟悉Hadoop的人应该都知道 ...
随机推荐
- hasura graphql-engine集成pgbouncer 连接池工具
pgbouncer 是一个轻量的pg 连接池工具,我们可以和hasura graphql-engine集成起来,进行连接的一些优化 环境准备 docker-compose 文件 version: '3 ...
- Python的itertools模块
本章将介绍Python自建模块itertools,更多内容请参考:Python参考指南 python的自建模块itertools提供了非常有用的用于操作迭代对象的函数. 首先,我们看看itertool ...
- Linux+eclipse+maven+tomcat7小项目实战
一.准备工作:CentOS6.5安装linux,maven,tomcat7,eclipse 二.在linux中打开eclipse,创建一个maven项目 修改web.xml 打开Navigator视图 ...
- revit api 实现过滤墙图元并选中
public IList<Element> findElementsByCategory(Autodesk.Revit.UI.UIApplication aApp, Document aD ...
- node start - hello world http server
Write a file t1.js 'use strict'; const express = require('express'); // Constants const PORT = 8080; ...
- ipset可使iptables一次性封多个ip
ipset是什么? ipset是iptables的扩展,它允许你创建 匹配整个地址集合的规则.而不像普通的iptables链只能单IP匹配, ip集合存储在带索引的数据结构中,这种结构即时集合比较大也 ...
- Logstash的grok以及Ruby
logstash的grok插件的用途是提取字段,将非格式的内容进行格式化, input { file { path => "/var/log/http.log" } } fi ...
- tk简单使用
# 引入tk import tkinter as tk class UserLogin(object): """ 初始化窗口 """ def ...
- golang 指针在struct里的应用
type aa struct { b *int c string } func main() { var data int = 0 var ip *int /* 声明指针变量 */ ip = & ...
- js switch 函数类型 序列化 转义
switch(name){ case '1': age = 123; break; case '2': age = 456; break; default : age = 777; } 函数 func ...