【Go】优雅的读取http请求或响应的数据
【Go】优雅的读取http请求或响应的数据
原文链接:https://blog.thinkeridea.com/201901/go/you_ya_de_du_qu_http_qing_qiu_huo_xiang_ying_de_shu_ju.html
从 http.Request.Body 或 http.Response.Body 中读取数据方法或许很多,标准库中大多数使用 ioutil.ReadAll 方法一次读取所有数据,如果是 json 格式的数据还可以使用 json.NewDecoder 从 io.Reader 创建一个解析器,假使使用 pprof 来分析程序总是会发现 bytes.makeSlice 分配了大量内存,且总是排行第一,今天就这个问题来说一下如何高效优雅的读取 http 中的数据。
背景介绍
我们有许多 api 服务,全部采用 json 数据格式,请求体就是整个 json 字符串,当一个请求到服务端会经过一些业务处理,然后再请求后面更多的服务,所有的服务之间都用 http 协议来通信(啊, 为啥不用 RPC,因为所有的服务都会对第三方开放,http + json 更好对接),大多数请求数据大小在 1K~4K,响应的数据在 1K~8K,早期所有的服务都使用 ioutil.ReadAll 来读取数据,随着流量增加使用 pprof 来分析发现 bytes.makeSlice 总是排在第一,并且占用了整个程序 1/10 的内存分配,我决定针对这个问题进行优化,下面是整个优化过程的记录。
pprof 分析
这里使用 https://github.com/thinkeridea/go-extend/blob/master/exnet/exhttp/expprof/pprof.go 中的 API 来实现生产环境的 /debug/pprof 监测接口,没有使用标准库的 net/http/pprof 包因为会自动注册路由,且长期开放 API,这个包可以设定 API 是否开放,并在规定时间后自动关闭接口,避免存在工具嗅探。
服务部署上线稳定后(大约过了一天半),通过 curl 下载 allocs 数据,然后使用下面的命令查看分析。
$ go tool pprof allocs
File: xxx
Type: alloc_space
Time: Jan 25, 2019 at 3:02pm (CST)
Entering interactive mode (type "help" for commands, "o" for options)
(pprof) top
Showing nodes accounting for 604.62GB, 44.50% of 1358.61GB total
Dropped 776 nodes (cum <= 6.79GB)
Showing top 10 nodes out of 155
flat flat% sum% cum cum%
111.40GB 8.20% 8.20% 111.40GB 8.20% bytes.makeSlice
107.72GB 7.93% 16.13% 107.72GB 7.93% github.com/sirupsen/logrus.(*Entry).WithFields
65.94GB 4.85% 20.98% 65.94GB 4.85% strings.Replace
54.10GB 3.98% 24.96% 56.03GB 4.12% github.com/json-iterator/go.(*frozenConfig).Marshal
47.54GB 3.50% 28.46% 47.54GB 3.50% net/url.unescape
47.11GB 3.47% 31.93% 48.16GB 3.55% github.com/json-iterator/go.(*Iterator).readStringSlowPath
46.63GB 3.43% 35.36% 103.04GB 7.58% handlers.(*AdserviceHandler).returnAd
42.43GB 3.12% 38.49% 84.62GB 6.23% models.LogItemsToBytes
42.22GB 3.11% 41.59% 42.22GB 3.11% strings.Join
39.52GB 2.91% 44.50% 87.06GB 6.41% net/url.parseQuery
从结果中可以看出采集期间一共分配了 1358.61GB top 10 占用了 44.50% 其中 bytes.makeSlice 占了接近 1/10,那么看看都是谁在调用 bytes.makeSlice 吧。
(pprof) web bytes.makeSlice
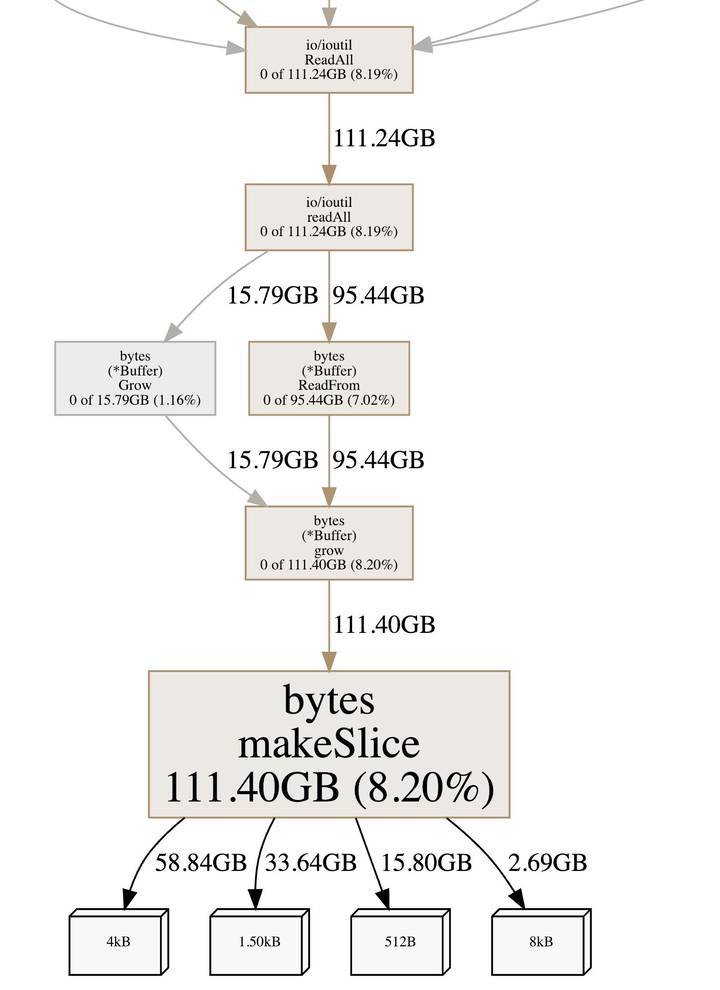
从上图可以看出调用 bytes.makeSlice 的最终方法是 ioutil.ReadAll, (受篇幅影响就没有截取 ioutil.ReadAll 上面的方法了),而 90% 都是 ioutil.ReadAll 读取 http 数据调用,找到地方先别急想优化方案,先看看为啥 ioutil.ReadAll 会导致这么多内存分配。
func readAll(r io.Reader, capacity int64) (b []byte, err error) {
var buf bytes.Buffer
// If the buffer overflows, we will get bytes.ErrTooLarge.
// Return that as an error. Any other panic remains.
defer func() {
e := recover()
if e == nil {
return
}
if panicErr, ok := e.(error); ok && panicErr == bytes.ErrTooLarge {
err = panicErr
} else {
panic(e)
}
}()
if int64(int(capacity)) == capacity {
buf.Grow(int(capacity))
}
_, err = buf.ReadFrom(r)
return buf.Bytes(), err
}
func ReadAll(r io.Reader) ([]byte, error) {
return readAll(r, bytes.MinRead)
}
以上是标准库 ioutil.ReadAll 的代码,每次会创建一个 var buf bytes.Buffer 并且初始化 buf.Grow(int(capacity)) 的大小为 bytes.MinRead, 这个值呢就是 512,按这个 buffer 的大小读取一次数据需要分配 2~16 次内存,天啊简直不能忍,我自己创建一个 buffer 好不好。
看一下火焰图
【Go】优雅的读取http请求或响应的数据的更多相关文章
- 【Go】优雅的读取http请求或响应的数据-续
原文链接:https://blog.thinkeridea.com/201902/go/you_ya_de_du_qu_http_qing_qiu_huo_xiang_ying_de_shu_ju_2 ...
- Ajax发送GET、POST请求和响应XML数据案例
1.新建工程 新建一个java web工程,新建一个Servlet文件 AServlet.java,用于返回get和post请求. public class AServlet extends Http ...
- spring基础---->请求与响应的参数(一)
这里面我们主要介绍一下spring中关于请求和响应参数数据的问题.爱,从来就是一件千回百转的事.不曾被离弃,不曾受伤害,怎懂得爱人?爱,原来是一种经历. spring中的请求与响应 一.spring中 ...
- struts2基础——请求与响应、获取web资源
一.请求与响应 Action1.含义:(1) struts.xml 中的 action 元素,也指 from 表单的 action 属性,总之代表一个 struts2 请求.(2) 用于处理 Stru ...
- 写一个ActionFilter检测WebApi接口请求和响应
我们一般用日志记录每次Action的请求和响应,方便接口出错后排查,不过如果每个Action方法内都写操作日志太麻烦,而且客户端传递了错误JSON或XML,没法对应强类型参数,请求没法进入方法内, 把 ...
- http请求返回响应码的意思
HTTP 状态响应码 意思详解/大全 HTTP状态码(HTTP Status Code)是用以表示网页服务器HTTP响应状态的3位数字代码.它由 RFC 2616 规范定义的,并得到RFC 2518. ...
- CakePHP之请求与响应对象
请求与响应对象 请求与响应对象在 CakePHP 2.0 是新增加的.在之前的版本中,这两个对象是由数组表示的,而相关的方法是分散在RequestHandlerComponent,Router,Dis ...
- 老李分享:HTTP协议之请求和响应
老李分享:HTTP协议之请求和响应 HTTP请求头详解: GET http://www.foo.com/ HTTP/1.1 GET是请求方式,请求方式有GET/POST http://www.fo ...
- python爬虫(二)_HTTP的请求和响应
HTTP和HTTPS HTTP(HyperText Transfer Protocol,超文本传输协议):是一种发布和接收HTML页面的方法 HTTPS(HyperText Transfer Prot ...
随机推荐
- 【慕课网实战】五、以慕课网日志分析为例 进入大数据 Spark SQL 的世界
提交Spark Application到环境中运行spark-submit \--name SQLContextApp \--class com.imooc.spark.SQLContextApp \ ...
- python之路(七)-递归算法
递归 特点 递归算法是一种直接或者间接地调用自身算法的过程.在计算机编写程序中,递归算法对解决一大类问题是十分有效的,它往往使算法的描述简洁而且易于理解. 递归算法解决问题的特点: (1) 递归就是在 ...
- Monkey测试结果分析
Monkey测试结果分析 什么是monkey Monkey 测试是 Android 自动化测试的手段之一,它通过模拟用户的按键输入.触摸屏输入等,测试设备多长时间出现异常.Monkey 是一个命令行工 ...
- [XAF] Llamachant Framework Modules
Llamachant Framework Modules 最近更新 2018-08-22 *变更:我们从所需的模块列表中删除了审计跟踪模块.如果要在应用程序中使用Audit Trail功能,请将Aud ...
- 网络编程——UDP编程
一个简单的聊天代码:运行结果: 在这个程序之中,由于recvfrom函数拥塞函数,没有数据时会一直阻塞,所以客户端和服务器端只能通过一回一答的方式进行信息传递.严格的讲UDP没有明确的客户端和服务端, ...
- sqlserver 多行转一行
sql 例子: SELECT STUFF((SELECT ',' + CONVERT(VARCHAR, b.SCsinfoSourceId) FROM PZDataCsinfo b WHERE b.D ...
- #254 Reverse a String
翻转字符串 先把字符串转化成数组,再借助数组的reverse方法翻转数组顺序,最后把数组转化成字符串. 你的结果必须得是一个字符串 这是一些对你有帮助的资源: Global String Object ...
- querySelectorAll选择器的js实现
自从标准浏览器增加了querySelector这个类JQ的方法后,选择一个元素变成了一件so easy的事情.但是某些浏览器还是不支持.使用jq库又有点太大,其实可以自己动手实现这个选择器,具体代码如 ...
- TCP/IP(一)之开启计算机网络之路
阅读目录(Content) 一.局域网.广域网和Internet 1.1.局域网 1.2.广域网 1.3.Internet 二.计算机数据之间通信的过程 2.1.路由器的功能(转发收到的分组) 三.O ...
- Redis 指令 学习笔记
Redis 什么是Redis redis是一种nosql数据库,他的数据是保存在内存中,同时redis可以定时把内存数据同步到磁盘,即可以将数据持久化,还提供了多个语言的API,操作比较方便 安装re ...