论文阅读笔记十八:ENet: A Deep Neural Network Architecture for Real-Time Semantic Segmentation(CVPR2016)

论文源址:https://arxiv.org/abs/1606.02147
tensorflow github: https://github.com/kwotsin/TensorFlow-ENet
摘要
在移动端上进行实时的像素级分割十分重要。基于分割的深度神经网络中存在大量的浮点运算而且需要经过较长的时间才可以进行投入使用。该文提出的ENet目的是减少潜在的计算。ENet相比现存的分割网络,速度快18倍,参数量要少79倍,同时分割得到的准确率不有所损失,甚至有所提高。
介绍
目前,增强现实可穿戴设备,家庭智能设备,自动驾驶的兴起,迫切需要将语义分割(场景理解)算法移植到较低性能的移动端设备上。分割算法对图像中的每一个像素点进行类别标记。进来,较大的数据集与较强的计算资源(GPU,TPU)的出现促进了卷积神经网络超越传统的计算机视觉算法。尽管卷积网络在分类和识别任务取得较好的效果,但进行像素级分割时,仍生成较为粗糙的空间结果。因此,经常会在此算法基础上拼接其他算法来对结果进行增强,像基于颜色的分割,条件随机场等。
为了对图片进行空间分类和进行精细的分割,已经出现了像SegNet,FCN等网络结构,这些结构都是基于VGG-16的大型多分类网络。但其有大量的参数和长时间的推理时间。因此,这些网络并不适用于要求处理图片速度高于10fps的移动端或者电池供电的应用设备上。
该文所提出的网络结构主要应用于快速的推理与进行较高准确率的分割。
相关工作
语义分割对于图片理解与寻找目标发挥着重要的作用。在增强现实与自动驾驶中,语义分割发挥着举足轻重的作用,此外,实时性的要求也是极高的。当下的计算机视觉应用普遍使用深度神经网络。场景分析较好的卷积网络使用两阶段网络结构:编码层和解码层。受自编码器的启发。编码-解码结构的网络在SegNet中出现并得到了改进。编码部分类似于VGG的卷积网络用于对输入进行分类,而解码部分主要用于对编码网络部分的输出进行上采样。但这些网络的一个重大缺点是数量巨大的参数延长了其推理时间。不同于FCN,在SegNet中,VGG16的全连接层被移除,为了减少其浮点操作和内存的占用。但SegNet这种轻量级的网络仍无法做到实时分割。
其他结构基于较简单的分类器后接CRF作为一个后处理的步骤。这些复杂的后处理操作经常无法标记一帧图片中较小的物体。CNN可以结合RNN来提高准确率,但无法解决速度消失的问题。但RNN可以作为一种后处理手段与任何其他技术进行结合。
网络结构
ENet网络结构如下表格,该文参考ResNet,将其结构描述为一个主分支与一个带有卷积核的附加分支,最后进行像素级的相加融合。
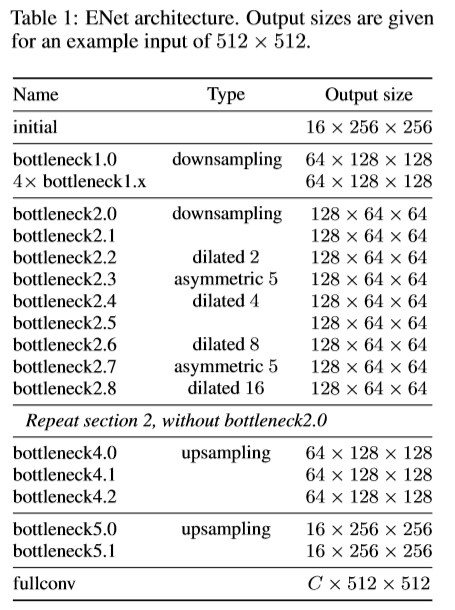
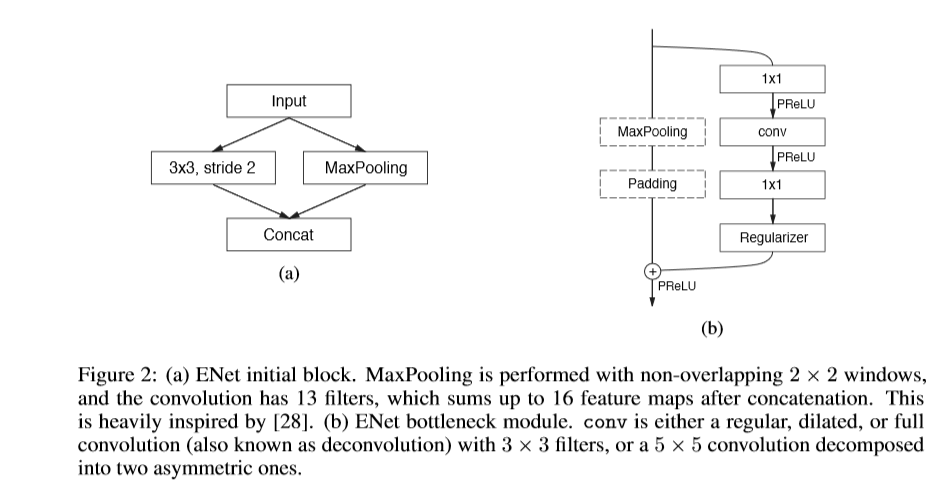
ENet中的每个block如下图b所示,每个block包含有三个卷积层:一个1x1的映射用于减少维度,一个主卷积层,一个1x1的扩张。将BN层与PReLU层穿插其中,将此结构组合定义为bottleneck 模型。如果bottleneck为下采样,则在主分支上添加一个最大池化层,同时,bollteneck中第一个1x1的映射被一个大小为2x2,stride为2的卷积进行替换,对激活值进行padding操作,使其与feature map的尺寸相匹配。卷积大小为3x3的,类型有普通卷积,空洞卷积,及转置卷积等,有时,用1x5或者5x1的非对称卷积对其替换。对于正则化处理,在bottleneck2.0之前使用p=0.01,其他条件下使p=0.1。
ENet的初始部分包含单独的一个block。如上图a.第一阶段包含5个bottleneck部分。第二,三阶段结构相同,但第三阶段的开始处并未有下采样的过程。前三个阶段属于编码阶段。第四五阶段属于解码阶段。由于cuDNN使用分离的内核进行卷积与偏差项的计算,为了减少内核的调用与内存的占用,该网络并未使用偏差项,结果发现,准确率也并未受很大的影响。在每个卷积层与pReLU层之间添加了一层BN层。在解码网络部分,最大池化层,被最大上采样层代替,padding被无偏差项的空间卷积替换。ENet在最后一个上采样过程中并未使用最大池化的索引,因为输入图片的通道为3,而输出通道数为类别数,最终,用一个全卷积模型作为网络的最后模型,占用部分解码网络的处理时间。
设计选择
Feature map的尺寸:语义分割中对图片进行下采样操作有两处缺点:(1)feature map分辨率的减少意味着空间位置信息的损失,如准确的边界信息等。(2)进行全像素的语义分割要求网络的输出大小要与输入的大小相同。这意味着对图片进行了下采样,就要进行形同程度的上采样。增加了模型的大小与计算资源。对于第一个问题,FCN通过添加编码层的feature map,SegNet通过保留编码网络中最大池化过程中最大值的索引,并借此在解码网络中生成稀疏的上采样maps。考虑到内存需要,该文使用SegNet的方式。同时,过分的下采样,十分不利于分割的准确率。
下采样的一个优点是:在下采样过的图片中进行卷积操作会有较大的感受野,从而可以获得更多的上下文信息。上下文信息十分利于不同类别的区分。该文发现使用空洞卷积的效果会更好。
Early downsampling: 要想实现较好的分割效果和实时的操作,要意识到处理较大的输入图片是十分消耗资源的。ENet的前两个block极大的减少了输入的尺寸,同时,只使用了一小部分feature map。由于可视化信息是高度空间冗余的,可以将其压缩为一种更有效的表达形式。网络的初始部分作用为特征提取及后续网络对输入的预处理。
解码尺寸大小:SegNet是一个极其对称的网络结构,ENet网络结构是非对称的,包含一个较大的编码层和一个小的解码网络。原因是编码层应该像原始分类网络的结构相似。用于处理较小的数据,同时进行信息的处理与滤波,解码网络对编码网络的输出进行上采样用于对细节的微调。
非线性操作:该文发现去掉网络初始层中的大部分ReLU层会提升分割的效果,作者认为此网络的深度不够深。然后,该文将所有ReLU替换为PReLUs,针对每张feature map增加了一个额外的参数。
信息保留的维度变化: 前半部分进行下采样是有必要的,但剧烈的维度衰减不利于信息的流动。为解决这个问题,该文任务在池化层后接一个卷积层增加了维度,进而增加了计算资源。为此,该文将池化操作与卷积操作进行并行操作,然后进行拼接。同时,在原始的ResNet的结构中,进行下采样时,第一个1x1的映射,在所有维度上进行的是步长为2的卷积,丢弃了75%左右的输入信息。将卷积核增加至2x2利于信息的保留。
分解卷积核: 一个二维的卷积可以被分解为两个维度为1的卷积核。(nxn => nx1,1xn),该文使用5x1,1x5的非对称卷积,减弱了函数学习的过拟合同时增加了感受野。卷积核的分解带来的另一个好处是可以减少大量的参数。加上非线性处理,使计算功能更加丰富。
空洞卷积:该文将bottleneck中的卷积层替换为空洞卷积并进行串联,增大了感受野,提高了分割的IOU。
正则化:目前的分割数据集有限,因此网络的训练很容易达到过拟合。该文使用空间Dropout进行处理。
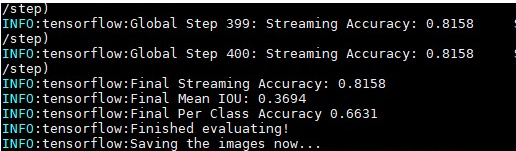
结果
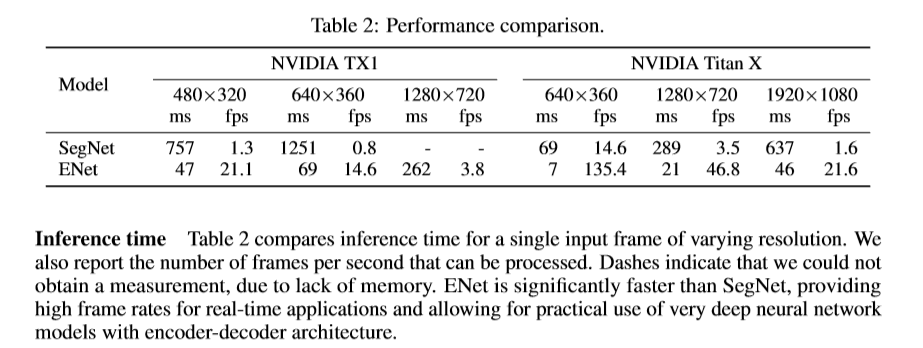

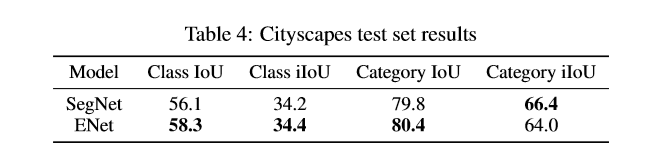
Reference
[1] Y. LeCun and Y. Bengio, “Convolutional networks for images, speech, and time series,” The handbook of brain theory and neural networks, pp. 255–258, 1998.
[2] A. Krizhevsky, I. Sutskever, and G. E. Hinton, “Imagenet classification with deep convolutional neural networks,” in Advances in Neural Information Processing Systems 25, 2012, pp. 1097–1105.
[3] K. Simonyan and A. Zisserman, “Very deep convolutional networks for large-scale image recognition,” arXiv preprint arXiv:1409.1556, 2014.
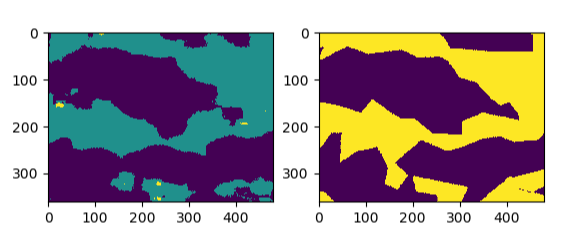
对于MFB的类别权重预处理得到的分割结果:
论文阅读笔记十八:ENet: A Deep Neural Network Architecture for Real-Time Semantic Segmentation(CVPR2016)的更多相关文章
- 论文阅读笔记十四:Decoupled Deep Neural Network for Semi-supervised Semantic Segmentation(CVPR2015)
论文链接:https://arxiv.org/abs/1506.04924 摘要 该文提出了基于混合标签的半监督分割网络.与当前基于区域分类的单任务的分割方法不同,Decoupled 网络将分割与分类 ...
- 论文阅读笔记十六:DeconvNet:Learning Deconvolution Network for Semantic Segmentation(ICCV2015)
论文源址:https://arxiv.org/abs/1505.04366 tensorflow代码:https://github.com/fabianbormann/Tensorflow-Decon ...
- 论文阅读笔记十五:Pyramid Scene Parsing Network(CVPR2016)
论文源址:https://arxiv.org/pdf/1612.01105.pdf tensorflow代码:https://github.com/hellochick/PSPNet-tensorfl ...
- 论文阅读笔记十三:The One Hundred Layers Tiramisu: Fully Convolutional DenseNets for Semantic Segmentation(FC-DenseNets)(CVPR2016)
论文链接:https://arxiv.org/pdf/1611.09326.pdf tensorflow代码:https://github.com/HasnainRaz/FC-DenseNet-Ten ...
- 【论文笔记】Malware Detection with Deep Neural Network Using Process Behavior
[论文笔记]Malware Detection with Deep Neural Network Using Process Behavior 论文基本信息 会议: IEEE(2016 IEEE 40 ...
- 论文翻译:2022_PACDNN: A phase-aware composite deep neural network for speech enhancement
论文地址:PACDNN:一种用于语音增强的相位感知复合深度神经网络 引用格式:Hasannezhad M,Yu H,Zhu W P,et al. PACDNN: A phase-aware compo ...
- 论文阅读笔记四十一:Very Deep Convolutional Networks For Large-Scale Image Recongnition(VGG ICLR2015)
论文原址:https://arxiv.org/abs/1409.1556 代码原址:https://github.com/machrisaa/tensorflow-vgg 摘要 本文主要分析卷积网络的 ...
- 论文阅读笔记十二:Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation(DeepLabv3+)(CVPR2018)
论文链接:https://arxiv.org/abs/1802.02611 tensorflow 官方实现: https: //github.com/tensorflow/models/tree/ma ...
- 【论文阅读】Sequence to Sequence Learning with Neural Network
Sequence to Sequence Learning with NN <基于神经网络的序列到序列学习>原文google scholar下载. @author: Ilya Sutske ...
随机推荐
- Light oj 1021 - Painful Bases
题意: 给一个B进制的数,一个10进制的数K,B进制数有x位, 对着x位进行全排列的话,有x!种可能, 问这x!的可能中,有多少种可以整除K,各个位置上的数字都不同. 思路:状态压缩,数位DP #i ...
- linux中创建python的虚拟环境
1,何为虚拟环境 linux是支持多用户的系统,如果某一位用户不想使用公用环境,想指定特殊的python版本安装仅供个人使用的一些包,那么虚拟环境将满足他的要求 2,虚拟环境使用需要virtualen ...
- 集合-HashMap
该文章的实践内容来自how2java网站,集合的学习篇章 1.概念: HashMap是以哈希表作为底层数据结构,以一组键值对作为存储单元的Map接口的实现类. 其主要特点是,容器内的元素不以添加顺序排 ...
- 【转】Win10下python3和python2多版本同时安装并解决pip共存问题
[转]Win10下python3和python2多版本同时安装并解决pip共存问题 特别说明,本文是在Windows64位系统下进行的,32位系统请下载相应版本的安装包,安装方法类似. 使用pytho ...
- C++著名程序库的比较和学习经验
内容目录:1.C++各大有名库的介绍——C++标准库2.C++各大有名库的介绍——准标准库Boost3.C++各大有名库的介绍——GUI4.C++各大有名库的介绍——网络通信5.C++各大有名库的介绍 ...
- Linux 网络侦错:无法联机原因分析
所谓的软件问题,绝大部分就是 IP 参数设定错误啊,路由不对啊,还有 DNS 的 IP 设定错误等等的, 这些问题都是属于软件设定啦!只要将设定改一改,利用一些侦测软件查一查,就知道问题出在哪里了!基 ...
- 范数(norm) 几种范数的简单介绍
原文地址:https://blog.csdn.net/a493823882/article/details/80569888 我们知道距离的定义是一个宽泛的概念,只要满足非负.自反.三角不等式就可以称 ...
- 阿里云服务器上通过Docker部署redmine
背景:在日常工作的过程中会遇到各种各样的问题,每个问题来了之后需要花时间解决.这里就面临两个问题. 1:问题责任不明确,有时候会遇到数据库或者物理服务器的问题,这时候就需要把相应问题指派给相应的人,传 ...
- UDP/TCP拾遗
1.UDP的特点 (1)UDP 是无连接的,即发送数据之前不需要建立连接. (2)UDP 使用尽最大努力交付,即不保证可靠交付,同时也不使用拥塞控制. (3)UDP 是面向报文的.UDP 没有拥塞控制 ...
- 前端 -----jQuery的事件绑定和解绑
11-jQuery的事件绑定和解绑 1.绑定事件 语法: bind(type,data,fn) 描述:为每一个匹配元素的特定事件(像click)绑定一个事件处理器函数. 参数解释: type (S ...