python爬虫scrapy之downloader_middleware设置proxy代理
一、背景:
小编在爬虫的时候肯定会遇到被封杀的情况,昨天爬了一个网站,刚开始是可以了,在settings的设置DEFAULT_REQUEST_HEADERS伪装自己是chrome浏览器,刚开始是可以的,紧接着就被对方服务器封杀了。
代理:
代理,代理,一直觉得爬去网页把爬去速度放慢一点就能基本避免被封杀,虽然可以使用selenium,但是这个坎必须要过,scrapy的代理其实设置起来很简单。
注意,request.meta['proxy']=代理ip的API
middlewares.py
class HttpbinProxyMiddleware(object):
def process_request(self, request, spider):
pro_addr = requests.get('http://127.0.0.1:5000/get').text
request.meta['proxy'] = 'http://' + pro_addr
#request.meta['proxy'] = 'http://' + proxy_ip
设置启动上面我们写的这个代理
settings.py
DOWNLOADER_MIDDLEWARES = {
'httpbin.middlewares.HttpbinProxyMiddleware': 543,
}
spiders
httpbin_test.py import scrapy class HttpbinTestSpider(scrapy.Spider):
name = "httpbin_test"
allowed_domains = ["httpbin.ort/get"]
start_urls = ['http://httpbin.org/get']
def parse(self, response):
print(response.text)
origin的值其实就是本地的公网地址,但是因为我们用了代理,这里的ip是美国的一个ip
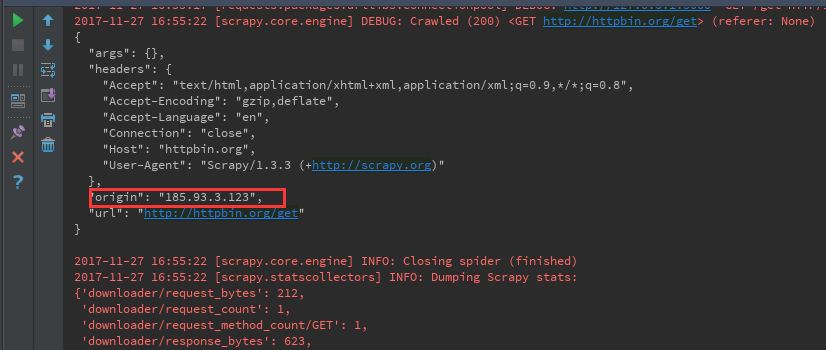

二、那么问题来了,现在有这么一个场景,如上所述的话,我每个请求都会使用代理池里面的代理IP地址,但是有些操作是不需要代理IP地址的,那么怎么才能让它请求超时的时候,再使用代理池的IP地址进行重新请求呢?
spider:
1、我们都知道scrapy的基本请求步骤是,首先执行父类里面(scrapy.Spider)里面的start_requests方法,
2、然后start_requests方法也是取拿我们设置的start_urls变量里面的url地址
3、最后才执行make_requests_from_url方法,并只传入一个url变量
那么,我们就可以重写make_requests_from_url方法,从而直接调用scrapy.Request()方法,我们简单的了解一下里面的几个参数:
1、url=url,其实就是最后start_requests()方法里面拿到的url地址
2、meta这里我们只设置了一个参数,download_timeout:10,作用就是当第一次发起请求的时候,等待10秒钟,如果没有请求成功的话,就会直接执行download_middleware里面的方法,我们下面介绍。
3、callback回调函数,其实就是本次的本次所有操作完成后执行的操作,注意,这里可不是说执行完上面所有操作后,再执行这个操作,比如说请求了一个url,并且成功了,下面就会执行这个方法。
4、dont_filter=False,这个很重要,有人说过不加的话默认就是False,但是亲测必须得加,作用就是scrapy默认有去重的方法,等于False的话就意味着不参加scrapy的去重操作。亲测,请求一个页面,拿到第一个页面后,抓取想要的操作后,第二页就不行了,只有加上它才可以。
import scrapy class HttpbinTestSpider(scrapy.Spider):
name = "httpbin_test"
allowed_domains = ["httpbin.ort/get"]
start_urls = ['http://httpbin.org/get'] def make_requests_from_url(self,url):
self.logger.debug('Try first time')
return scrapy.Request(url=url,meta={'download_timeout':10},callback=self.parse,dont_filter=False) def parse(self, response):
print(response.text)
middlewares.py
下面就是上面请求10秒后超时会执行的操作process_exception方法,心细的同学会发现,我们在spider文件里面输出log的时候,是直接输出的,那是因为scrapy早都在父类里面给你定义好了,直接应用就行,但是在middlewares里面需要自己定义一个类变量定义,才能使用引用。
class HttpbinProxyMiddleware(object):
logger = logging.getLogger(__name__) # def process_request(self, request, spider):
# # pro_addr = requests.get('http://127.0.0.1:5000/get').text
# # request.meta['proxy'] = 'http://' + pro_addr
# pass
#
# def process_response(self, request, response, spider):
# # 可以拿到下载完的response内容,然后对下载完的内容进行修改(修改文本的编码格式等操作)
# pass def process_exception(self, request, response, spider):
self.logger.debug('Try Exception time')
self.logger.debug('Try second time')
proxy_addr = requests.get('http://127.0.0.1:5000/get').text
self.logger.debug(proxy_addr)
request.meta['proxy'] = 'http://{0}'.format(proxy_addr)
settings.py
这里才是关键,我们需要执行middlewares里面的HttpbinProxyMiddleware类下面的方法,这里需要注意的是我取消了下载中间件的retry中间件,因为scrapy本身就有自动重试的方法,为了试验效果,这里取消了默认的重试中间件。
DOWNLOADER_MIDDLEWARES = {
'httpbin.middlewares.HttpbinProxyMiddleware': 543,
#设置不参与scrapy的自动重试的动作
'scrapy.downloadermiddlewares.retry.RetryMiddleware':None
}
注意:
上面我访问的url是httpbin.org,这个网站不用代理也可以打开,这里你可以在不打开翻墙工具的时候,访问google.com,因为我自己学习用的代理地址基本都是国内的地址,所以即使是google也是打不开的。
总结:
上面我们介绍了两种scrapy加代理的写法:
1、第一种是直接每次访问都使用代理IP发起请求
2、第二种是在不能正常获取请求结果的时候,再使用代理ip。
3、我们学习了scrapy中如何打印logging日志,从而简单判断问题和执行步骤。
小知识:
['scrapy.downloadermiddlewares.httpauth.HttpAuthMiddleware',
'scrapy.downloadermiddlewares.downloadtimeout.DownloadTimeoutMiddleware',
'scrapy.downloadermiddlewares.defaultheaders.DefaultHeadersMiddleware',
'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware',
'httpbin.middlewares.HttpbinProxyMiddleware',
'scrapy.downloadermiddlewares.redirect.MetaRefreshMiddleware',
'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware',
'scrapy.downloadermiddlewares.redirect.RedirectMiddleware',
'scrapy.downloadermiddlewares.cookies.CookiesMiddleware',
'scrapy.downloadermiddlewares.stats.DownloaderStats']
2017-11-27 23:36:47 [scrapy.middleware] INFO: Enabled spider middlewares:
['scrapy.spidermiddlewares.httperror.HttpErrorMiddleware',
'scrapy.spidermiddlewares.offsite.OffsiteMiddleware',
'scrapy.spidermiddlewares.referer.RefererMiddleware',
'scrapy.spidermiddlewares.urllength.UrlLengthMiddleware',
'scrapy.spidermiddlewares.depth.DepthMiddleware']
scrapy默认middleware
这里我们可以再Terminal下面打印一下,简单介绍一下:
1、在scrapy中的中间件里面,对应的中间件后面的数字越小,执行优先级越高。
2、如果你想取消某个download_middlewares的话就直接如我上面写的,把它Copy出来,加个None,这样它就不执行了。
3、补充,如果你看过scrapy的基本执行流程图的话,就会知道scrapy除了下载中间件,还有个spider中间件,所以用的时候不要用错了。
D:\项目\小项目\scrapy_day6_httpbin\httpbin>scrapy settings --get=DOWNLOADER_MIDDLEWARES_BASE
{"scrapy.downloadermiddlewares.httpauth.HttpAuthMiddleware": 300, "scrapy.downloadermiddlewares.useragent.UserAgentMiddleware": 500, "scrapy.downloadermiddlewares.redirect.MetaRefres
hMiddleware": 580, "scrapy.downloadermiddlewares.httpcache.HttpCacheMiddleware": 900, "scrapy.downloadermiddlewares.redirect.RedirectMiddleware": 600, "scrapy.downloadermiddlewares.r
obotstxt.RobotsTxtMiddleware": 100, "scrapy.downloadermiddlewares.retry.RetryMiddleware": 550, "scrapy.downloadermiddlewares.cookies.CookiesMiddleware": 700, "scrapy.downloadermiddle
wares.defaultheaders.DefaultHeadersMiddleware": 400, "scrapy.downloadermiddlewares.stats.DownloaderStats": 850, "scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddlewar
e": 590, "scrapy.downloadermiddlewares.httpproxy.HttpProxyMiddleware": 750, "scrapy.downloadermiddlewares.downloadtimeout.DownloadTimeoutMiddleware": 350, "scrapy.downloadermiddlewar
es.ajaxcrawl.AjaxCrawlMiddleware": 560}
python爬虫scrapy之downloader_middleware设置proxy代理的更多相关文章
- Python爬虫连载10-Requests模块、Proxy代理
一.Request模块 1.HTTP for Humans,更简洁更友好 2.继承了urllib所有的特征 3.底层使用的是urllib3 4.开源地址:https://github.com/req ...
- python爬虫scrapy框架——人工识别登录知乎倒立文字验证码和数字英文验证码(2)
操作环境:python3 在上一文中python爬虫scrapy框架--人工识别知乎登录知乎倒立文字验证码和数字英文验证码(1)我们已经介绍了用Requests库来登录知乎,本文如果看不懂可以先看之前 ...
- python爬虫Scrapy(一)-我爬了boss数据
一.概述 学习python有一段时间了,最近了解了下Python的入门爬虫框架Scrapy,参考了文章Python爬虫框架Scrapy入门.本篇文章属于初学经验记录,比较简单,适合刚学习爬虫的小伙伴. ...
- python爬虫scrapy项目详解(关注、持续更新)
python爬虫scrapy项目(一) 爬取目标:腾讯招聘网站(起始url:https://hr.tencent.com/position.php?keywords=&tid=0&st ...
- Python 爬虫入门(二)—— IP代理使用
上一节,大概讲述了Python 爬虫的编写流程, 从这节开始主要解决如何突破在爬取的过程中限制.比如,IP.JS.验证码等.这节主要讲利用IP代理突破. 1.关于代理 简单的说,代理就是换个身份.网络 ...
- [Python爬虫] scrapy爬虫系列 <一>.安装及入门介绍
前面介绍了很多Selenium基于自动测试的Python爬虫程序,主要利用它的xpath语句,通过分析网页DOM树结构进行爬取内容,同时可以结合Phantomjs模拟浏览器进行鼠标或键盘操作.但是,更 ...
- 安装python爬虫scrapy踩过的那些坑和编程外的思考
这些天应朋友的要求抓取某个论坛帖子的信息,网上搜索了一下开源的爬虫资料,看了许多对于开源爬虫的比较发现开源爬虫scrapy比较好用.但是以前一直用的java和php,对python不熟悉,于是花一天时 ...
- python爬虫scrapy学习之篇二
继上篇<python之urllib2简单解析HTML页面>之后学习使用Python比较有名的爬虫scrapy.网上搜到两篇相应的文档,一篇是较早版本的中文文档Scrapy 0.24 文档, ...
- Python爬虫Scrapy框架入门(0)
想学习爬虫,又想了解python语言,有个python高手推荐我看看scrapy. scrapy是一个python爬虫框架,据说很灵活,网上介绍该框架的信息很多,此处不再赘述.专心记录我自己遇到的问题 ...
随机推荐
- python第七十课——python2与python3的一些区别
1.性能:py3.x起始比py2.x效率低,但是py3.x有极大的优化空间,效率正在追赶 2.编码:py3.x原码文件默认使用utf-8编码,使得变量名更为广阔 中国='CHI' print(中国) ...
- 实现ppt幻灯片播放倒计时
需求:为控制会议时间,采取ppt幻灯片播放倒计时的办法,倒计时5分钟. 分析:用EnumWindows枚举窗口,发现PPT窗口类名有三种:PP12FrameClass.MS-SDIb.screenCl ...
- Python:Day09
Ubantu忘记密码: 1.开机长按shift,进入界面后按e: 2.将红框中内改成如下并按F10重启: 3.输入passwd,然后用户名,然后重新输入密码: locale命令查看系统中是否有中文 a ...
- arduino json 解析
#include <ArduinoJson.h> void setup() { Serial.begin(9600); DynamicJsonDocument jsonBuffer(200 ...
- Git分支管理规范
关于Git的一些分支管理规范... 一.分支与角色说明 Git 分支类型 master 分支(主分支) 稳定版本 develop 分支(开发分支) 最新版本 release 分支(发布分支) 发布新版 ...
- Linux死锁检测-Lockdep
关键词:LockDep.spinlock.mutex. lockdep是内核提供协助发现死锁问题的功能. 本文首先介绍何为lockdep,然后如何在内核使能lockdep,并简单分析内核lockdep ...
- IntelliJ IDEA 破解方法
2017版破解方法: 1. 到网站http://idea.lanyus.com/,按要求修改电脑HOST,获取注册码: 使用前请将“0.0.0.0 account.jetbrains.com”添加到h ...
- IntelliJ IDEA 高效率配置
之前学习和开发的时候一直用Eclipse,现在转战IDEA,记录一下IDEA的个性化设置,有助于提高效率.(参考:http://www.cnblogs.com/huaxingtianxia/p/586 ...
- Eclipse中快速打开文件所在的文件夹位置
本篇文章是紧接着Elicpse使用技巧-打开选中文件文件夹或者包的当前目录文章写的,本文主要是讲的利用eclipse插件的方式打开文件夹的位置, 由于eclipse版本的区别,所以插件也分成两种(实测 ...
- xxtea---单片机数据加密算法
转:https://www.cnblogs.com/LittleTiger/p/4384741.html 各位大侠在做数据传输时,有没有考虑过把数据加密起来进行传输,若在串口或者无线中把所要传的数据加 ...