Python笔记(十七):生成器
(一)生成器(Generator)
Python生成器是创建迭代器的简单方法。简单来说,生成器是一个函数,它返回一个我们可以迭代的对象(迭代器)(一次一个值)。
因为下面会用到列表生成式,这里先说明下列表生成式:
列表生成式:
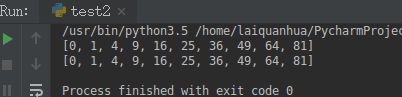
theLi = [i*i for i in range(10)]
下面这段代码的效果和上面的列表生成式是一样的(一开始可能不太习惯列表生成式的写法,多写几次就习惯了):
L = []
for i in range(10):
L.append(i*i)
可在IDE中将结果打印出来.
(二)创建生成器
1、将列表生成式的[]换成()就行了。
theLi = [i*i for i in range(10)] print(theLi)
#创建一个生成器
theGe = (i*i for i in range(10)) print('生成器:',theGe)
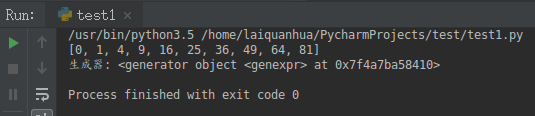
可以看到,print('生成器:',theGe)输出的是一个生成器对象,不会直接输出结果
2、在函数中定义yield语句就行了(执行到yield语句时,就会返回结果,不过生成器函数和普通函数还是有区别的,下面会说明)
def theGe():
i = 1
yield i print(type(theGe()))
(三)生成器函数和普通函数的区别
1、Generator函数包含一个或多个yield语句。
2、调用生成器函数时,它返回一个生成器对象,但不会立即执行。
3、生成器函数会自动实现__iter__()和__next__()方法。
4、执行顺序不同:普通函数执行到最后一句或者return语句时,就返回结果.而生成器函数,则是每次调用next()方法时执行,遇到yied语句就返回结果,再次执行时从上次结束的yield语句处开始执行.(执行顺序的问题,设个断点运行一次就清楚了)。
5、局部变量和状态会被保存,一直到下一次调用。
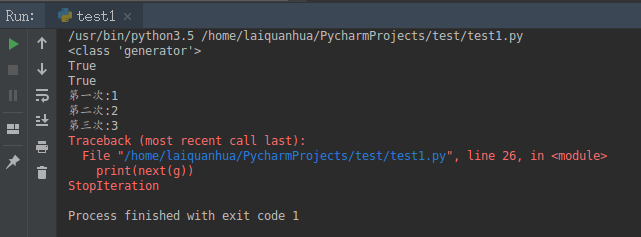
6、函数结束时,抛出StopIteration异常。
举个例子:
from collections import Iterable
from collections import Iterator def gen(): i = 1
print('第一次:',end='')
yield i
i += 1
print('第二次:',end='')
yield i
i += 1
print('第三次:',end='')
yield i print(type(gen()))
#生成器也是迭代器
print(isinstance(gen(),Iterable))
print(isinstance(gen(),Iterator)) g = gen()
print(next(g))
print(next(g))
print(next(g))
print(next(g))
(四)生成器的使用
例如:使用生成器实现杨辉三角

比较简单的一种理解方式,将每一行都看成一个列表,通过末尾补0的方式来计算下一行列表的值.
例如:我们知道第二行的元素,我们可以通过下面这种方式获得三行的元素(这个规律是通用的)
#第二行
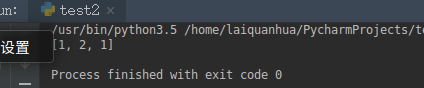
L2 = [1,1] L2.append(0) #此时变成了[1,1,0] L3 = []
# 列表的索引为-1的时候,值=0. L2[-1] = 0
L3.append(L2[-1] + L2[0])
L3.append(L2[0]+L2[1])
L3.append(L2[1]+L2[2]) print(L3)
而下面这段代码
L3 = []
# 列表的索引为-1的时候,值=0. L2[-1] = 0
L3.append(L2[-1] + L2[0])
L3.append(L2[0]+L2[1])
L3.append(L2[1]+L2[2])
其实就是:
L3 = []
for i in range(len(L2)):
L3.append(L2[i-1] + L2[i])
也是(列表生成式的写法):
L3 = [L2[i-1]+L2[i] for i in range(len(L2))]
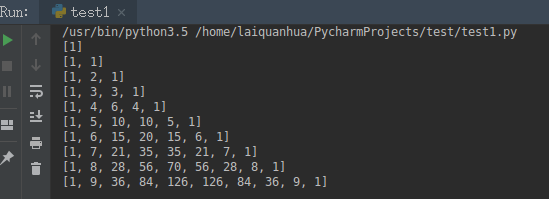
实现杨辉三角:
#杨辉三角
def yhTriangles(n):
yh = [1]
while len(yh) <= n:
yield yh
yh.append(0)
yh = [yh[i-1] + yh[i] for i in range(len(yh))] for i in yhTriangles(10):
print(i)
(五)使用生成器的优势
1、易于实现,代码更简洁,容易阅读。(例如:使用迭代器我们需要自己去定义__iter__()和_next_()方法,而生成器会自动处理这些)
2、对内存更加友好.例如:我们创建一个列表的时候,是一创建就存放到内存中的,如果数据量很大,毫无疑问会占用大量内存(而很多时候,我们可能并不需要访问所有数据)。如果列表元素可以通过某种算法推算出来,一边循环一边计算,这样就能节省大量的内存。Python的生成器就可以实现这种功能.
3、生成器可以代表一个无限的数据流.(无限的数据流是不能直接存放到内存中的,因为内存是有限的)
Python笔记(十七):生成器的更多相关文章
- python笔记2 生成器 文件读写
生成器 一边循环一边计算的机制,称为生成器(Generator). 把一个列表生成式的[]改成(),就创建了一个generator: 创建了一个generator后,通过for循环来迭代它. 著名的斐 ...
- Python笔记(十七)_面向对象编程
面向对象编程 概念:简称OOP,是一种程序设计思想:OOP把对象作为程序的基本单元,一个对象包含了数据和操作数据的函数 面向对象的设计思想:抽象出类class,根据类class创建实例对象instan ...
- Python学习笔记014——生成器Generator
1 生成器定义 在Python中,一边循环一边计算的机制,称之为生成器(generator). 生成器是一个迭代器. 含有yield语句的函数是生成器函数,该函数被调用时返回一个生成器对象(yield ...
- python3.4学习笔记(十七) 网络爬虫使用Beautifulsoup4抓取内容
python3.4学习笔记(十七) 网络爬虫使用Beautifulsoup4抓取内容 Beautiful Soup 是用Python写的一个HTML/XML的解析器,它可以很好的处理不规范标记并生成剖 ...
- python笔记 - day5
python笔记 - day5 参考: http://www.cnblogs.com/wupeiqi/articles/5484747.html http://www.cnblogs.com/alex ...
- python笔记之itertools模块
python笔记之itertools模块 itertools模块包含创建有效迭代器的函数,可以用各种方式对数据进行循环操作,此模块中的所有函数返回的迭代器都可以与for循环语句以及其他包含迭代器(如生 ...
- s21day22 python笔记
s21day22 python笔记 一.内容回顾及补充 模块补充 importlib.import_module:通过字符串的形式导入模块 #示例一: import importlib # 用字符串的 ...
- guxh的python笔记一:数据类型
1,基本概念 1.1,数据类型 基本数据类型:字符串,数字,布尔等 引用数据类型:相对不可变(元组),可变(列表,字典,集合等) 基本数据类型存放实际值,引用数据类型存放对象的地址(即引用) ==:判 ...
- Python:笔记(7)——yield关键字
Python:笔记(7)——yield关键字 yield与生成器 所谓生成器是一个函数,它可以生成一个值的序列,以便在迭代中使用.函数使用yield关键字可以定义生成器对象. 一个例子 我们调用该函数 ...
- Python:笔记(4)——高级特性
Python:笔记(4)——高级特性 切片 取一个list或tuple的部分元素是非常常见的操作.Python提供了切片操作符,来完成部分元素的选取 除了上例简单的下标范围取元素外,Python还支持 ...
随机推荐
- 使用ANNdotNET进行情感分析
2018年10月的MSDN杂志上发表了由James McCaffrey撰写的文章“使用CNTK的情感分析” .在这篇博文中,我将向您介绍这篇非常好且写得很好的MSDN文章示例.我不打算重复MSDN文章 ...
- arcgis 加载png图片实现图片跟随地图缩放 和图片的动态播放
效果图: 主要原理: png加载到地图上是不可能的, 图像本身是没有地理信息的. 这里采用一种办法, 在地图上创建一个图形图层, 图形图层放一个矩形,给这个矩形用一个图片填充符号填充. 关键技术点: ...
- WebSocket 协议
1.1 背景知识 由于历史原因,在创建一个具有双向通信机制的 web 应用程序时,需要利用到 HTTP 轮询的方式.围绕轮询产生了 “短轮询” 和 “长轮询”. 短轮询 浏览器赋予了脚本网络通信的编程 ...
- python三大神器之virtualenv
virtualenv virtualenv用来管理python项目环境,隔离出一个只属于这个项目的虚拟python环境(windows和Linux用法一样). 首先你需要安装virtualenv模块 ...
- HTML语法介绍
一 基本标签(块级标签和内联标签) <hn>: n的取值范围是1~6; 从大到小. 用来表示标题. <p>: 段落标签. 包裹的内容被换行.并且也上下内容之间有一行空白. &l ...
- JQ-bootstrap我的开源前端框架
因为实在不知道写啥,所以迟迟没有相关的介绍.但是必须要积累过程资产,所以还是介绍一下,不定哪天就有人用了. 首先还是介绍遇到的问题,我是做传统后台管理系统的,公司赶时髦,要用boo ...
- 浅谈SpringAOP
0. 写在最前面 之前实习天天在写业务,其中有一个业务是非常的复杂,涉及到了特别多的表.最后测下来,一个接口的时间,竟然要5s多. 当时想写一个AOP,来计算处理接口花费多长时间,也就是在业务逻辑的前 ...
- MySQL中间件之ProxySQL(12):禁止多路路由
返回ProxySQL系列文章:http://www.cnblogs.com/f-ck-need-u/p/7586194.html 1.multiplexing multiplexing,作用是将语句分 ...
- camera测试之MTF
1.MTF介绍 MTF(Modulation Transfer Function)模量传递函数.MTF是camera成像对比度和分辨率的综合表现.从另一个角度来看,camera成像过程可以简单看成下图 ...
- 结构型---适配器模式(Adapter Pattern)
适配器模式——把一个类的接口变换成客户端所期待的另一种接口,从而使原本接口不匹配而无法一起工作的两个类能够在一起工作.适配器模式有类的适配器模式和对象的适配器模式两种形式,下面我们分别讨论 ...