fastText文本分类算法
1、概述
FastText 文本分类算法是有Facebook AI Research 提出的一种简单的模型。实验表明一般情况下,FastText 算法能获得和深度模型相同的精度,但是计算时间却要远远小于深度学习模型。fastText 可以作为一个文本分类的 baseline 模型。
2、模型架构
fastText 的模型架构和 word2vec 中的CBOW 模型的结构很相似。CBOW 模型是利用上下文来预测中间词,而fastText 是利用上下文来预测文本的类别。而且从本质上来说,word2vec是属于无监督学习,fastText 是有监督学习。但两者都是三层的网络(输入层、单层隐藏层、输出层),具体的模型结构如下:
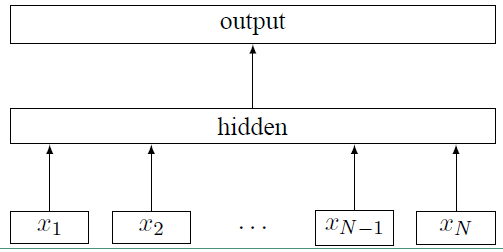
上面图中 $x_i$ 表示的是文本中第 $i$ 个词的特征向量,该模型的负对数似然函数如下:

上面式子中的矩阵 A 是词查找表,整个模型是查找出所有的词表示之后取平均值,用该平均值来代表文本表示,然后将这个文本表示输入到线性分类器中,也就是输出层的 softmax 函数。式子中的 B 是函数 $ f $ 的权重系数。
3、分层 softmax(Hierarchical softmax)
首先来看看softmax 函数的表达式如下:
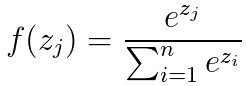
然而在类别非常多的时候,利用softmax 计算的代价是非常大的,时间复杂度为 $O(kh)$ ,其中 $k$ 是类别的数量,$h$ 是文本表示的维度。而基于霍夫曼树否建的层次 softmax 的时间复杂度为 $O(h;log_2(k))$ (二叉树的时间复杂度是 $O(log_2(k))$ )。霍夫曼树是从根节点开始寻找,而且在霍夫曼树中权重越大的节点越靠近根节点,这也进一步加快了搜索的速度。
4、N-grams 特征
传统的词袋模型不能保存上下文的语义,例如“我爱你”和“你爱我”在传统的词袋模型中表达的意思是一样的,N-grams 模型能很好的保存上下文的语义,能将上面两个短语给区分开。而且在这里使用了 hash trick 进行特征向量降维。hash trick 的降维思想是讲原始特征空间通过 hash 函数映射到低维空间。
5、代码实现
import jieba
import fasttext as ft
from skllearn.model_selection import train_test_split ““
分词
去停用词
把处理过后的词写入文本
””
# 有监督的学习,训练分类器
classifier = ft.supervised(filePath, "classifier.model")
result = classifier.test(filePath) # 预测文档类别
labels = classifier.predict(texts) # 预测类别+概率
labelProb = classifier.predict_proba(texts) # 得到前k个类别
labels = classifier.predict(texts, k=3) # 得到前k个类别+概率
labelProb = classifier.predict_prob(texts, k=3)
参考论文:Bag of Tricks for Efficient Text Classification
fastText文本分类算法的更多相关文章
- 带监督的文本分类算法FastText
该算法由facebook在2016年开源,典型应用场景是“带监督的文本分类问题”. 模型 模型的优化目标如下: 其中,$<x_n,y_n>$是一条训练样本,$y_n$是训练目标,$ ...
- FastText 文本分类使用心得
http://blog.csdn.net/thriving_fcl/article/details/53239856 最近在一个项目里使用了fasttext[1], 这是facebook今年开源的一个 ...
- 【十大算法实现之naive bayes】朴素贝叶斯算法之文本分类算法的理解与实现
关于bayes的基础知识,请参考: 基于朴素贝叶斯分类器的文本聚类算法 (上) http://www.cnblogs.com/phinecos/archive/2008/10/21/1315948.h ...
- 文本分类需要CNN?No!fastText完美解决你的需求(后篇)
http://blog.csdn.net/weixin_36604953/article/details/78324834 想必通过前一篇的介绍,各位小主已经对word2vec以及CBOW和Skip- ...
- 文本分类需要CNN?No!fastText完美解决你的需求(前篇)
http://blog.csdn.net/weixin_36604953/article/details/78195462?locationNum=8&fps=1 文本分类需要CNN?No!f ...
- 深度学习之文本分类模型-前馈神经网络(Feed-Forward Neural Networks)
目录 DAN(Deep Average Network) Fasttext fasttext文本分类 fasttext的n-gram模型 Doc2vec DAN(Deep Average Networ ...
- 万字总结Keras深度学习中文文本分类
摘要:文章将详细讲解Keras实现经典的深度学习文本分类算法,包括LSTM.BiLSTM.BiLSTM+Attention和CNN.TextCNN. 本文分享自华为云社区<Keras深度学习中文 ...
- 文本分类(TFIDF/朴素贝叶斯分类器/TextRNN/TextCNN/TextRCNN/FastText/HAN)
目录 简介 TFIDF 朴素贝叶斯分类器 贝叶斯公式 贝叶斯决策论的理解 极大似然估计 朴素贝叶斯分类器 TextRNN TextCNN TextRCNN FastText HAN Highway N ...
- Atitti 文本分类 以及 垃圾邮件 判断原理 以及贝叶斯算法的应用解决方案
Atitti 文本分类 以及 垃圾邮件 判断原理 以及贝叶斯算法的应用解决方案 1.1. 七.什么是贝叶斯过滤器?1 1.2. 八.建立历史资料库2 1.3. 十.联合概率的计算3 1.4. 十一. ...
随机推荐
- 【Java每日一题】20170215
20170214问题解析请点击今日问题下方的“[Java每日一题]20170215”查看(问题解析在公众号首发,公众号ID:weknow619) package Feb2017; public cla ...
- MyBatis:GeneratorConfig生成mapper以及pojo
首先我们需要导入相应的依赖 之后需要针对的配置一些数据 接着我们需要针对性的写配置文件,在根目录下写mybatis的主要配置文件 如上图我们配置了数据库连接.对应的一些pojo.mapper.java ...
- 史上最全python面试题详解(三)(附带详细答案(关注、持续更新))
38.面向对象深度优先和广度优先是什么? 39.面向对象中super的作用? 40.是否使用过functools中的函数?其作用是什么? Python自带的 functools 模块提供了一些常用的高 ...
- mapreduce中文乱码,已解决
问题: mapreduce中文乱码 原因: 再用Hadoop处理数据的时候,发现输出的时候,总是会出现乱码,这是因为Hadoop在设计编码的时候,是写死的.默认是UTF-8,所以当你处理的文件编码格式 ...
- 百度前端学院-基础学院-第20到21天之setTimeOut与setInterval
setTimeout()可以使用clearTimeout()关闭 setInterval() 方法会不停地调用函数,直到 clearInterval() 被调用或窗口被关闭. 注意:setInterv ...
- 环信easeui集成:坑总结2018(二)
环信EaseUI 集成,集成不做描述,看文档即可,下面主要谈一些对easeui的个性化需求修改. 该篇文章将解决的问题: 1.如何发送视频功能 2.未完待续.. ------------------- ...
- Android项目实战(三十三):AS下获取获取依赖三方的jar文件、aar 转 jar
使用 Android studio 开发项目中,有几种引用三方代码的方式:jar 包 ,类库 ,gradle.build 的compile依赖. 大家会发现github上不少的项目只提供compile ...
- ionic开发中,输入法键盘弹出遮挡住div元素
采用ionic 开发中,遇到键盘弹出遮挡元素的问题. 以登陆页面为例,输入用户名和密码时,键盘遮挡了登陆按钮. 最终采用自定义指令解决了问题: .directive('popupKeyBoardSho ...
- mongodb数据分组按字符串split
db.getCollection('users').aggregate([ {$match:{ZWBH:11}}, {$unwind:'$UUID'}, {$project : { PM : { $s ...
- Windows服务System权限下在当前用户桌面创建快捷方式C#实例程序
Windows服务一般运行在System权限下,这样权限比较高,方便执行一些高权限的操作. 但是,Environment.GetFolderPath等函数获取的也是System用户下的,而不是当前用户 ...