fastText文本分类算法
1、概述
FastText 文本分类算法是有Facebook AI Research 提出的一种简单的模型。实验表明一般情况下,FastText 算法能获得和深度模型相同的精度,但是计算时间却要远远小于深度学习模型。fastText 可以作为一个文本分类的 baseline 模型。
2、模型架构
fastText 的模型架构和 word2vec 中的CBOW 模型的结构很相似。CBOW 模型是利用上下文来预测中间词,而fastText 是利用上下文来预测文本的类别。而且从本质上来说,word2vec是属于无监督学习,fastText 是有监督学习。但两者都是三层的网络(输入层、单层隐藏层、输出层),具体的模型结构如下:
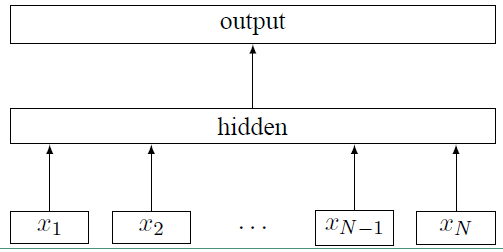
上面图中 $x_i$ 表示的是文本中第 $i$ 个词的特征向量,该模型的负对数似然函数如下:

上面式子中的矩阵 A 是词查找表,整个模型是查找出所有的词表示之后取平均值,用该平均值来代表文本表示,然后将这个文本表示输入到线性分类器中,也就是输出层的 softmax 函数。式子中的 B 是函数 $ f $ 的权重系数。
3、分层 softmax(Hierarchical softmax)
首先来看看softmax 函数的表达式如下:
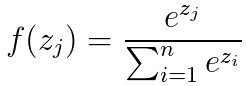
然而在类别非常多的时候,利用softmax 计算的代价是非常大的,时间复杂度为 $O(kh)$ ,其中 $k$ 是类别的数量,$h$ 是文本表示的维度。而基于霍夫曼树否建的层次 softmax 的时间复杂度为 $O(h;log_2(k))$ (二叉树的时间复杂度是 $O(log_2(k))$ )。霍夫曼树是从根节点开始寻找,而且在霍夫曼树中权重越大的节点越靠近根节点,这也进一步加快了搜索的速度。
4、N-grams 特征
传统的词袋模型不能保存上下文的语义,例如“我爱你”和“你爱我”在传统的词袋模型中表达的意思是一样的,N-grams 模型能很好的保存上下文的语义,能将上面两个短语给区分开。而且在这里使用了 hash trick 进行特征向量降维。hash trick 的降维思想是讲原始特征空间通过 hash 函数映射到低维空间。
5、代码实现
import jieba
import fasttext as ft
from skllearn.model_selection import train_test_split ““
分词
去停用词
把处理过后的词写入文本
””
# 有监督的学习,训练分类器
classifier = ft.supervised(filePath, "classifier.model")
result = classifier.test(filePath) # 预测文档类别
labels = classifier.predict(texts) # 预测类别+概率
labelProb = classifier.predict_proba(texts) # 得到前k个类别
labels = classifier.predict(texts, k=3) # 得到前k个类别+概率
labelProb = classifier.predict_prob(texts, k=3)
参考论文:Bag of Tricks for Efficient Text Classification
fastText文本分类算法的更多相关文章
- 带监督的文本分类算法FastText
该算法由facebook在2016年开源,典型应用场景是“带监督的文本分类问题”. 模型 模型的优化目标如下: 其中,$<x_n,y_n>$是一条训练样本,$y_n$是训练目标,$ ...
- FastText 文本分类使用心得
http://blog.csdn.net/thriving_fcl/article/details/53239856 最近在一个项目里使用了fasttext[1], 这是facebook今年开源的一个 ...
- 【十大算法实现之naive bayes】朴素贝叶斯算法之文本分类算法的理解与实现
关于bayes的基础知识,请参考: 基于朴素贝叶斯分类器的文本聚类算法 (上) http://www.cnblogs.com/phinecos/archive/2008/10/21/1315948.h ...
- 文本分类需要CNN?No!fastText完美解决你的需求(后篇)
http://blog.csdn.net/weixin_36604953/article/details/78324834 想必通过前一篇的介绍,各位小主已经对word2vec以及CBOW和Skip- ...
- 文本分类需要CNN?No!fastText完美解决你的需求(前篇)
http://blog.csdn.net/weixin_36604953/article/details/78195462?locationNum=8&fps=1 文本分类需要CNN?No!f ...
- 深度学习之文本分类模型-前馈神经网络(Feed-Forward Neural Networks)
目录 DAN(Deep Average Network) Fasttext fasttext文本分类 fasttext的n-gram模型 Doc2vec DAN(Deep Average Networ ...
- 万字总结Keras深度学习中文文本分类
摘要:文章将详细讲解Keras实现经典的深度学习文本分类算法,包括LSTM.BiLSTM.BiLSTM+Attention和CNN.TextCNN. 本文分享自华为云社区<Keras深度学习中文 ...
- 文本分类(TFIDF/朴素贝叶斯分类器/TextRNN/TextCNN/TextRCNN/FastText/HAN)
目录 简介 TFIDF 朴素贝叶斯分类器 贝叶斯公式 贝叶斯决策论的理解 极大似然估计 朴素贝叶斯分类器 TextRNN TextCNN TextRCNN FastText HAN Highway N ...
- Atitti 文本分类 以及 垃圾邮件 判断原理 以及贝叶斯算法的应用解决方案
Atitti 文本分类 以及 垃圾邮件 判断原理 以及贝叶斯算法的应用解决方案 1.1. 七.什么是贝叶斯过滤器?1 1.2. 八.建立历史资料库2 1.3. 十.联合概率的计算3 1.4. 十一. ...
随机推荐
- Maven(八)Eclipse创建Web项目(复杂方式)
1. 生成标准的Web工程结构 2. 勾选结尾为webapp的包 3. 生成的文件结构如下 3.1 生成的目录结构若存在错误,缺少servlet.api 3.1.1 添加步骤如下 4.生成后存在的缺点 ...
- Java并发编程学习:线程安全与锁优化
本文参考<深入理解java虚拟机第二版> 一.什么是线程安全? 这里我借<Java Concurrency In Practice>里面的话:当多个线程访问一个对象,如果不考虑 ...
- idea代码快捷
idea代码快捷:main函数快捷:psvmfor循环快捷:fori.foreach系统输出快捷:sout.serr 更多的提示可以按Ctrl+ J 进行查看 更改快捷:File-->Setti ...
- Js 控制随机数概率
如: 取 1~10 之间的随机数,那么他们的取值范围是: 整数 区间 概率 1 [0,1) 0.1 2 [1,2) 0.1 3 [2,3) 0.1 4 [3,4) 0.1 5 [4,5) 0.1 6 ...
- 小程序 lazy-load 不生效的问题
最近在开发家里喵喵的小程序(娱乐),本想抽一小部分时间做个懒加载.看了小程序官网 API,给 image 标签加上 lazy-load 就能实现懒加载.但从微信开发者工具看,似乎并没有生效.搜了一下, ...
- Javascript删除数组里的某个元素
删除array数组中的某个元素,首先需要确定需要删除元素的索引值. ? 1 2 3 4 5 6 7 var arr=[1,5,6,12,453,324]; function indexOf(val){ ...
- JS之函数实际参数转换成数组的方法[].slice.call(arguments)
实际参数在函数中我们可以使用 arguments 对象获得 (注:形参可通过 arguments.callee 获得),虽然 arguments 对象与数组形似,但仍不是真正意义上的数组. 我们可以通 ...
- cf24D. Broken robot(高斯消元)
题意 题目链接 Sol 今天上午的A题.想出来怎么做了但是没时间写了qwq 思路很简单,首先把转移方程列一下,发现每一个位置只会从下一行/左右转移过来,而且第N行都是0,那么往下转移的都可以回带. 剩 ...
- cf934C. A Twisty Movement(思维题)
题意 题目链接 Sol 这题最直接的维护区间以0/1结尾的LIS的方法就不说了. 其实我们可以直接考虑翻转以某个位置为中点的区间的最大值 不难发现前缀和后缀产生的贡献都是独立的,可以直接算.维护一下前 ...
- C# 8.0的三个值得关注的新特性
本文翻译自:https://dzone.com/articles/3-new-c-8-features-we-are-excited-about 转载请注明出自:葡萄城官网,葡萄城为开发者提供专业的开 ...